-
-
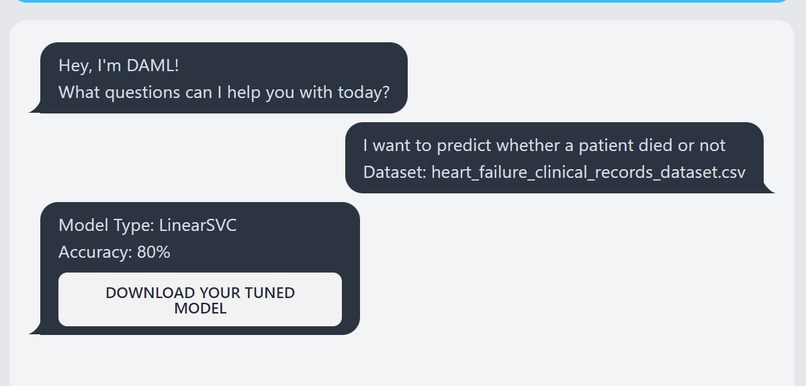
Use of the "DAML" assistant web application
-
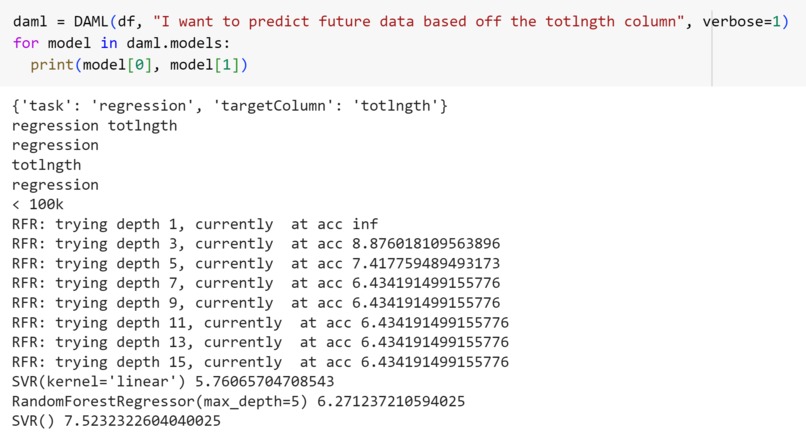
Verbose output from the model
-

DNLML logo




Introducing Durhack Natural-Language Machine-Learning (DNLML): Your Gateway to Effortless Machine Learning!
At Durhack '23, we've unveiled an innovative project that transforms the world of machine learning. DNLML empowers individuals with minimal technical expertise to harness the power of machine learning effortlessly. Through a user-friendly, natural language interface, this groundbreaking framework allows you to build machine learning models without the need for coding skills.
How does it work? Simply provide your dataset and express your query in plain language. For instance, you can ask, 'I want to predict whether a patient died or not.' In return, DNLML does the heavy lifting, crafting the best-performing model for your task, please see the example below for more information
Our technology stack, including ChatGPT 3.5 for natural language processing, Pandas for dataset management, and scikit-learn for model selection and training, streamlines the process.
Durhack NLML redefines accessibility and convenience in the world of machine learning. It's not just a tool; it's a game-changer. Join us in revolutionizing the way we approach data analysis and predictive modeling. Welcome to the future of machine learning, powered by the simplicity of natural language. 🚀 #DurhackNLML"
Example
- Dataset URL: https://www.kaggle.com/datasets/andrewmvd/heart-failure-clinical-data
- Query: "I want to predict whether a patient died or not"
- Process:

- Result: the best trained model (LinearSVC) is pickled and then returned to the user as model.sav
Capabilities
- Data Cleaning: the system conducts a moderate level of data cleaning including null value removal, categorical data encoding as well as data normalisation
- ML Scenarios: the system can currently deal with labelled classification tasks and regression tasks
- A variety of models: the system can currently choose between 7 distinct models in order to find the best model to solve the users specific problem on their unique dataset.
Technology
The technology used for this project is surprisingly simple (apart from model debugging)
- Model Generation
- ChatGPT 3.5 (Natural language pprocessing)
- Pandas (loading of dataset files into ddataframe)
- sklearn (model selection and training of models)
- API
- FastAPI (API framework)
- Web Interface
- Nuxt3
Using the API
Because I have some credits left over from OpenAI, please feel free to use the API :)
url: <to be added after event)
- / : says Hello
- /link : processes an NLAI request with a dataset url
- dataset_url: query
- task: query
- /file : processes an NLAI request with a base64 encoded csv
- dataset: body (ensure that the start 'data:text/csv;base64,' is removed from the front)
- task: body
Both the processing routes will return the following
- type: the model that was selected as the best after tuning
- accuracy: the test accuracy of the chosen model
- url: a link to download the model as a pickle
Built With
- chatgpt
- fastapi
- javascript
- nuxt3
- pandas
- python
- sklearn
- vue


Log in or sign up for Devpost to join the conversation.