🚀 Inspiration
I never imagined I’d be submitting to a global hackathon solo, with just my basic laptop and zero prior hackathon experience.
It all started during an internship at a reputed tech firm in India. I was given real tasks but no mentorship. No one to ask for help. At first, I was terrified. I didn't even know where to begin. But I forced myself to sit down, day after day, and figure things out alone.
That struggle became my strength.
Later, while working on a side project, I found myself constantly battling YAML files. So I built a basic YAML generator just for myself. That project opened my eyes. What if I could go beyond just generating YAMLs? What if I could analyze and patch them intelligently using AI?
That idea planted the seed for GenKube Guard and even though I was scared of failing, I knew I had to try.
🔧 What it does
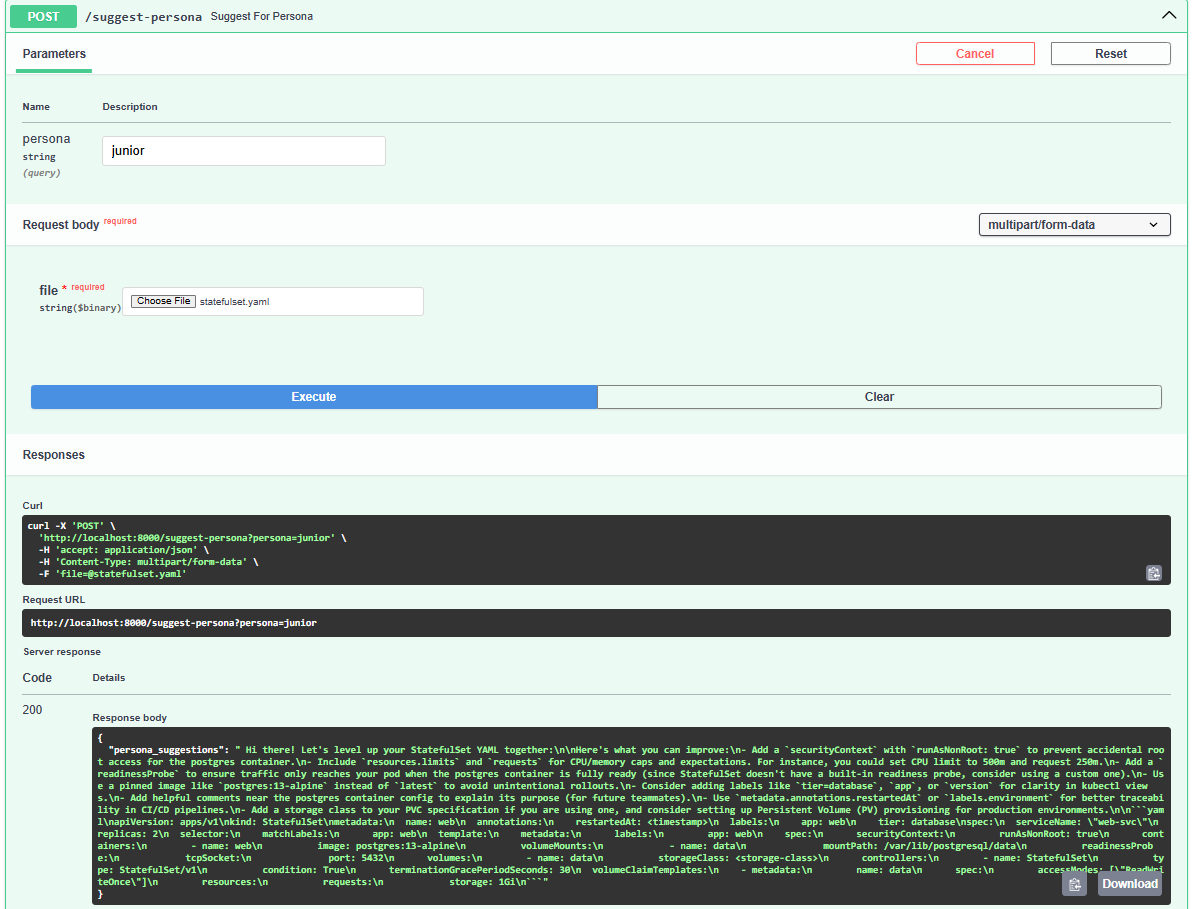
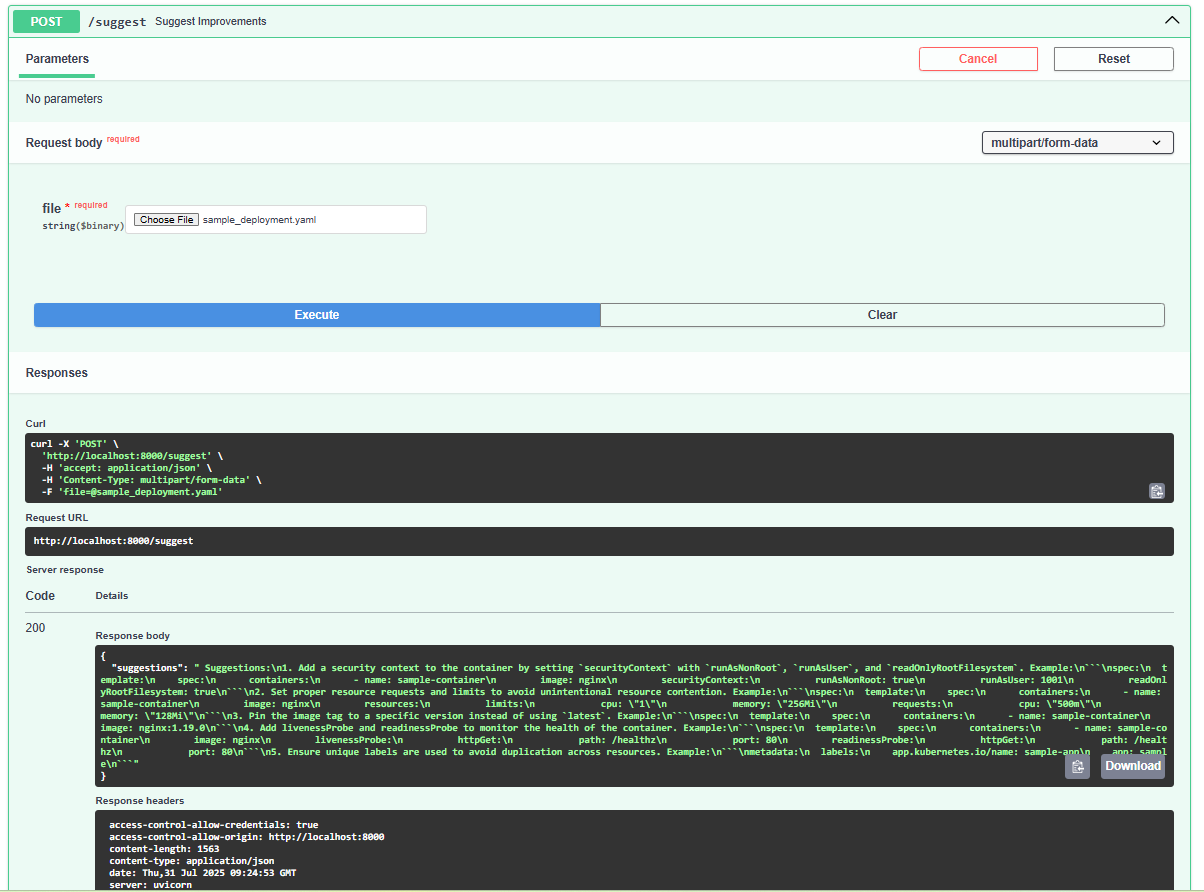
GenKube Guard is an LLM-powered DevSecOps assistant for Kubernetes YAMLs. It:
- Analyzes YAMLs using
kube-linter - Explains issues in plain language using an LLM
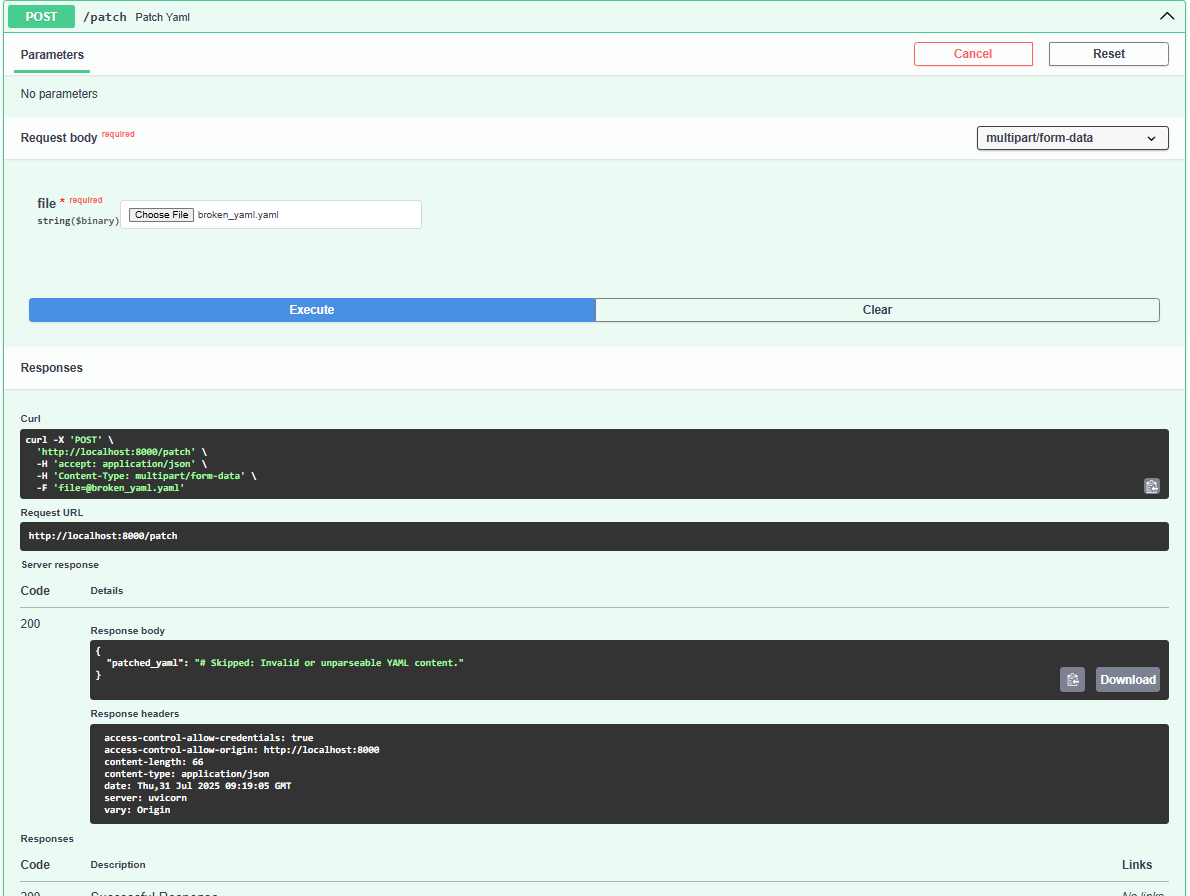
- Auto-patches insecure Deployments and StatefulSets
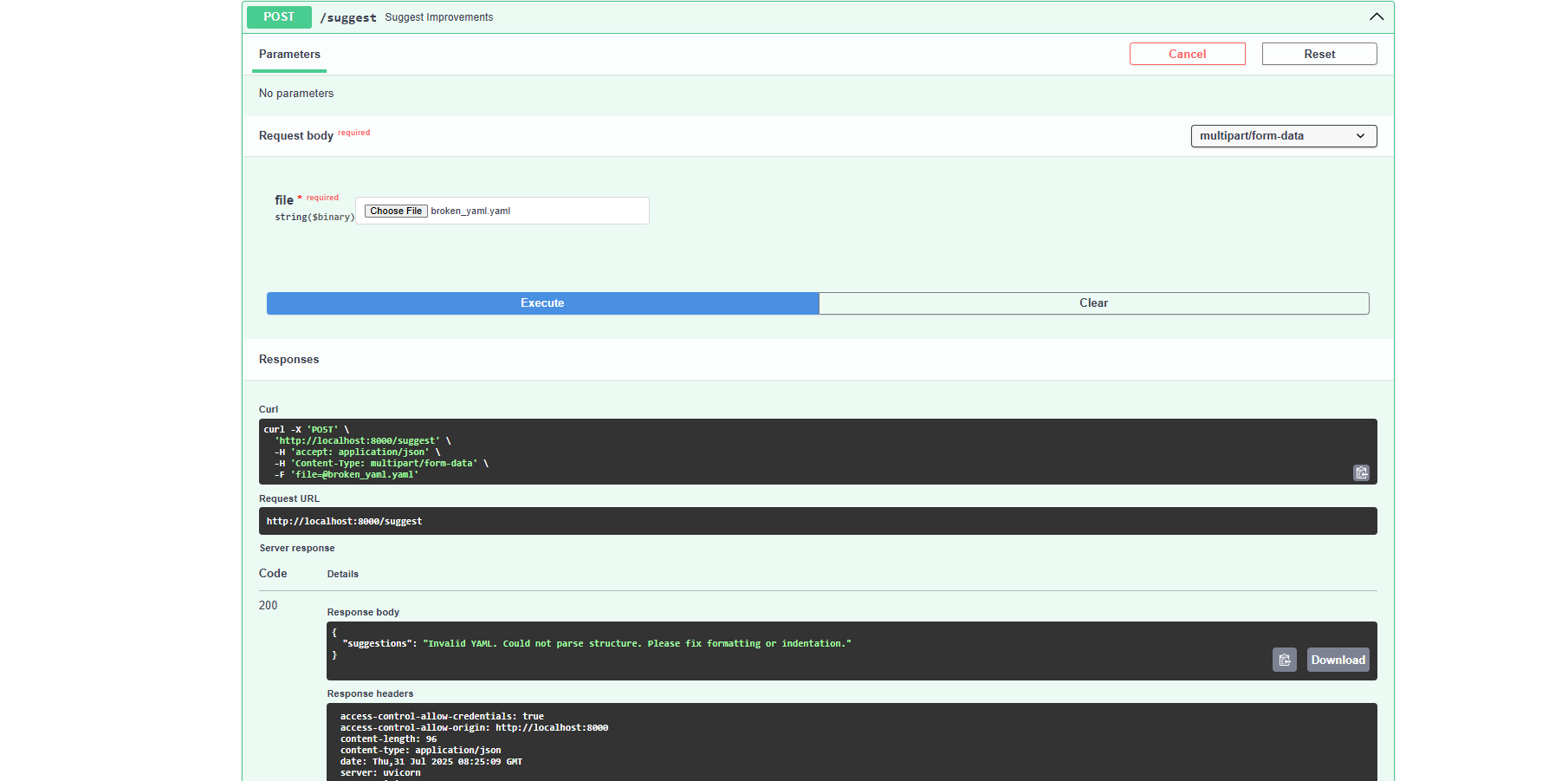
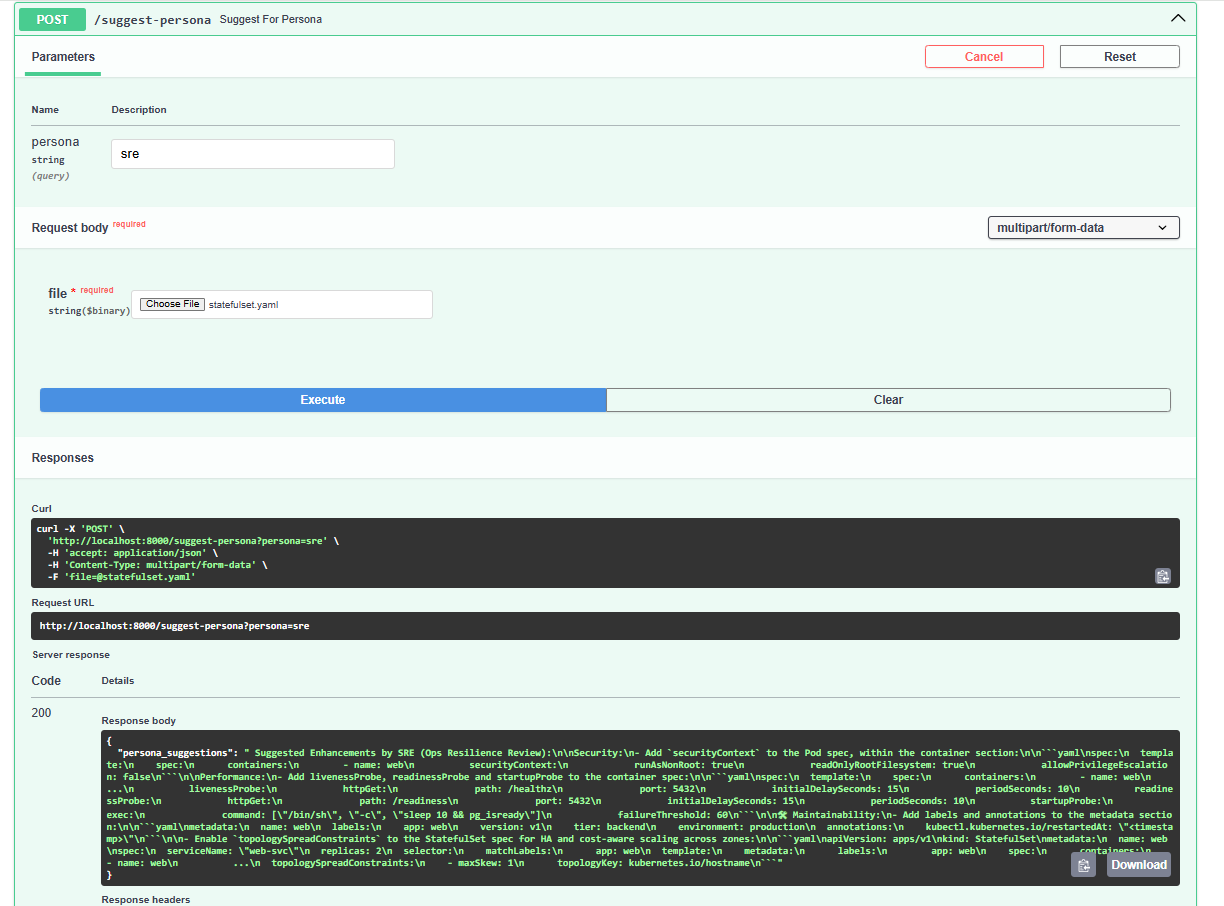
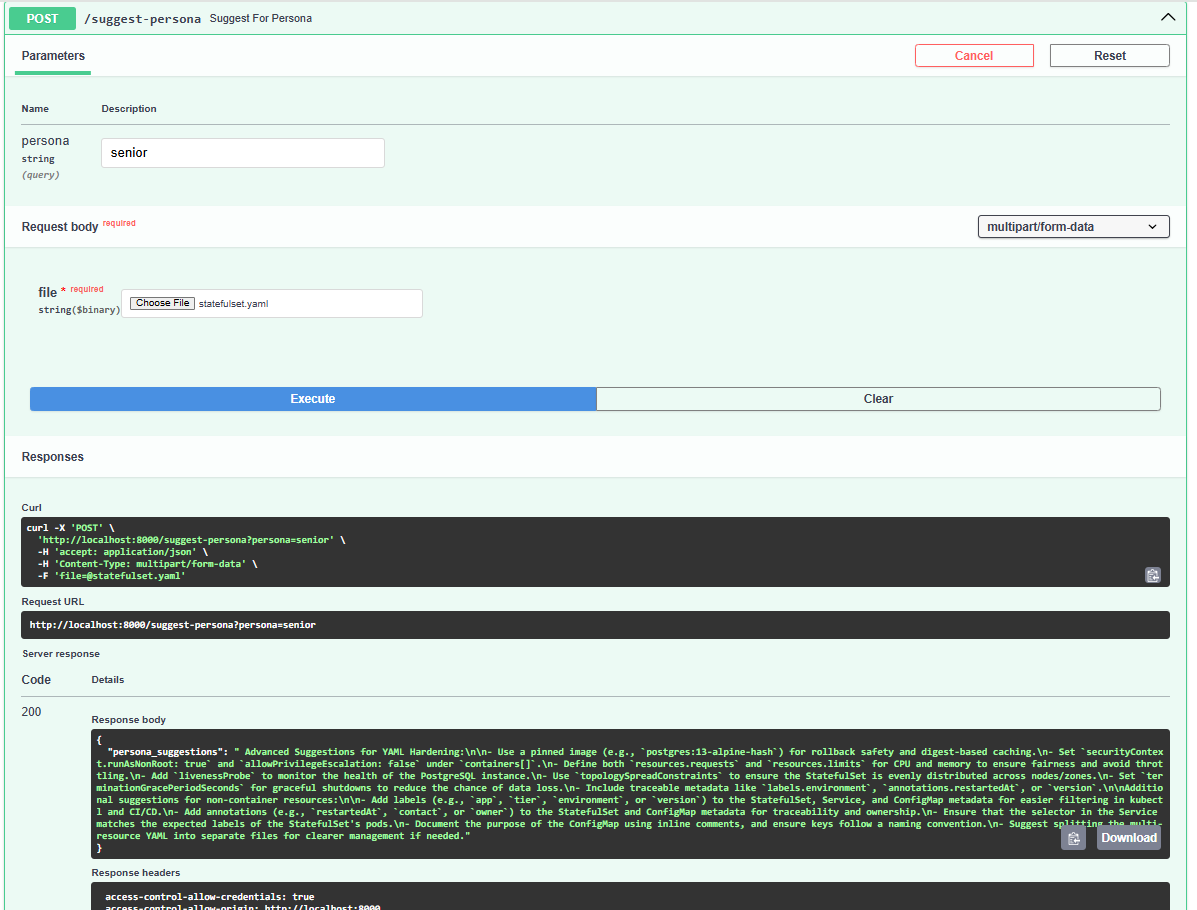
- Provides persona-based suggestions (junior, senior, SRE)
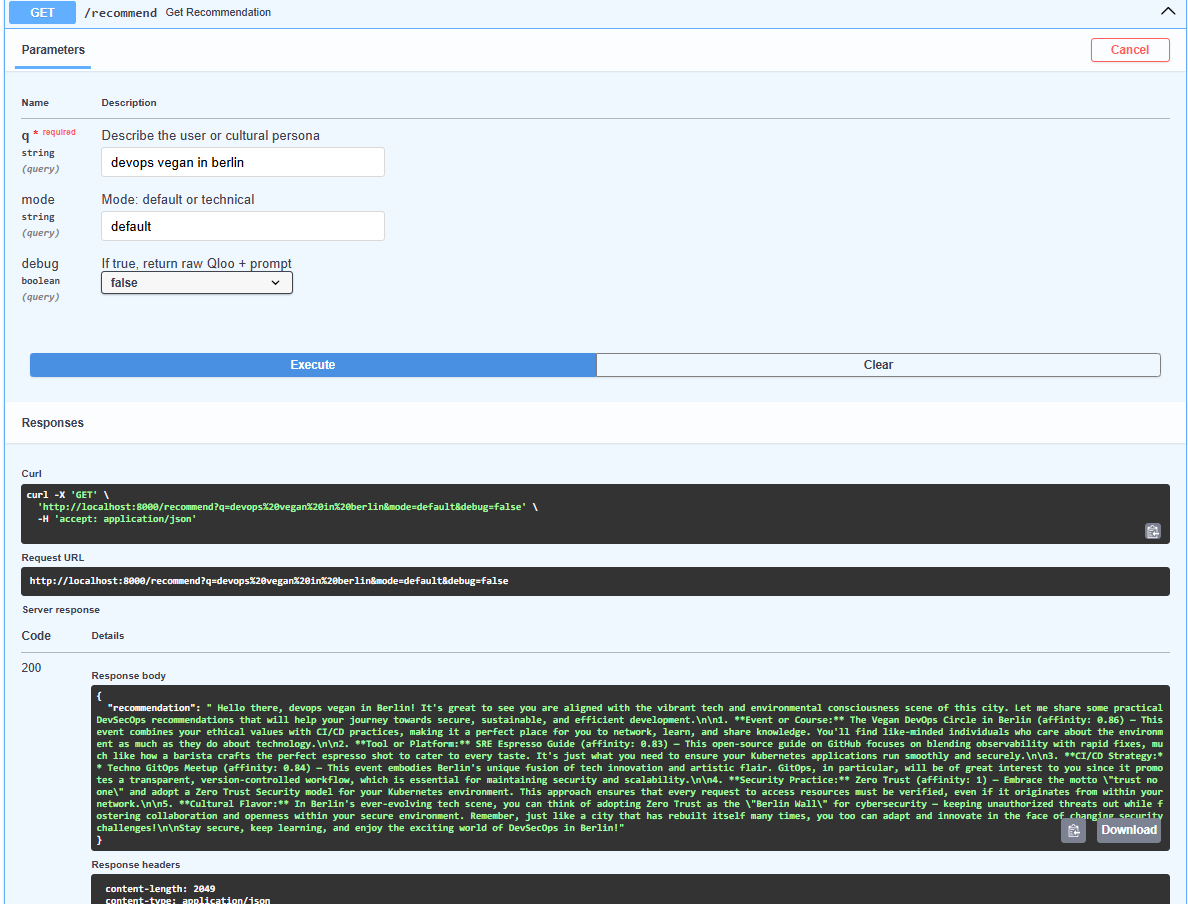
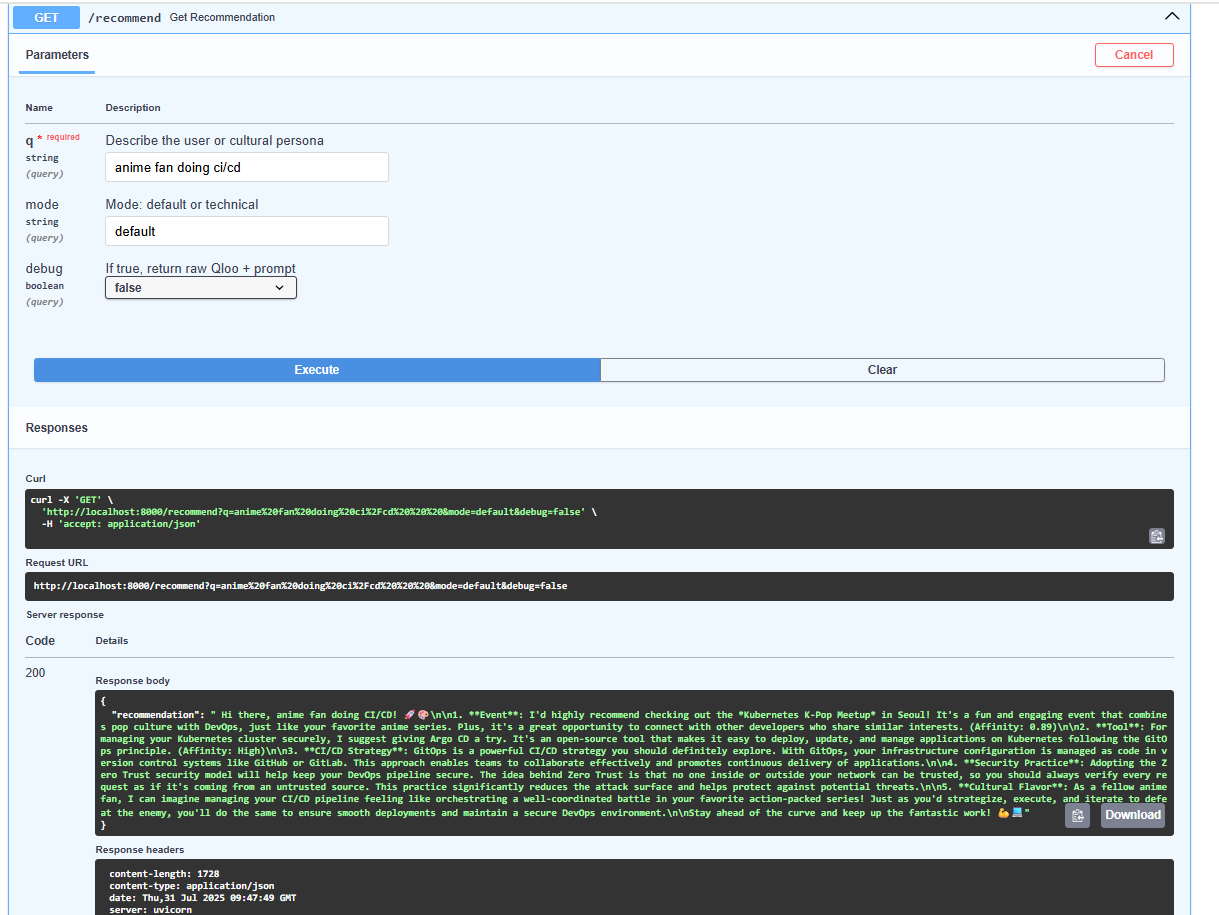
- Integrates cultural DevSecOps recommendations using a mock Qloo API
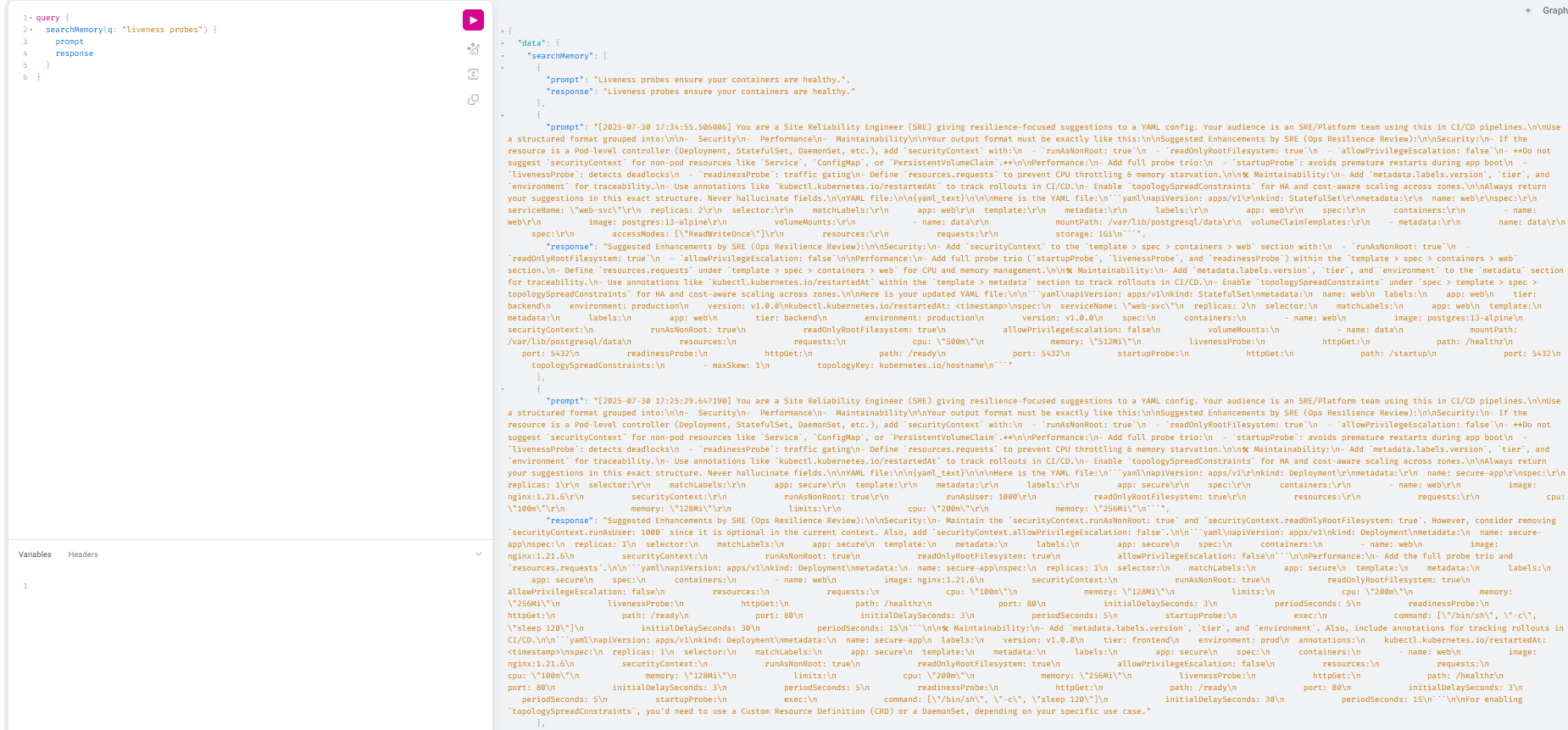
- Enables memory search via GraphQL and FAISS RAG
🏗️ How I built it
- Backend: FastAPI with routes like
/analyze,/patch,/suggest,/recommend,/memory - LLM: Mistral via Ollama (run locally)
- Mock Qloo Integration: Built fallback response logic when the API key didn’t work
- Memory Engine: FAISS-based vector store with semantic fallback
- Prompt Engineering: Custom YAML-aware templates for each endpoint
- Deployment: Shifted to Hugging Face when Render free tier maxed out (not compatible with Ollama)
🧱 Challenges I ran into
- LLM inference was very slow especially on a basic 16GB RAM laptop
- Docker rebuilds took forever, and sometimes froze the system
- Qloo API didn’t respond, so I manually crafted fallback responses for every query
- Couldn’t deploy LLM backend live on Hugging Face (Ollama is local only)
- Most difficult of all: emotional exhaustion. I cried some nights, doubting myself, wondering if I could finish.
But something kept me going maybe it was the thought that I’ve come this far, there’s no turning back.
🏆 Accomplishments that I'm proud of
- Built GenKube Guard completely solo design, code, testing, and deployment
- Started from a simple YAML generator → ended with an LLM-powered assistant
- Every endpoint was tested with multiple YAMLs and edge cases
- Created persona-aware, culturally tuned responses without real Qloo access
- Pushed past fear, burnout, and system limitations and finished strong
📚 What I learned
- Kubernetes internals, YAML structuring, kube-linter
- FastAPI, Docker, Ollama, FAISS, RAG, and GraphQL
- How to write structured prompt templates for secure AI output
- Resilience: the ability to keep going even when nothing seems to work
- That done with heart beats perfect with fear
🔮 What’s next for GenKube Guard
- Cloud-hosted LLM inference to enable full production deployment
- Full Qloo API integration (once accessible)
- A lightweight web UI (maybe React or plain HTML)
- DevSecOps CI integration (e.g., GitHub Actions plugin)
- Open-sourcing the project and documenting it to help others build YAML tooling with LLMs
💔 The Last-Minute Challenge
Right before submitting, Render’s free tier maxed out.
I rushed to deploy on Hugging Face Spaces, but there I hit the final roadblock:
Ollama doesn’t run on Hugging Face — meaning my deployed app can’t generate real LLM responses.
So for /recommend and /suggest, the app only returns mock fallback data.
Yes, it breaks part of the magic.
Yes, I was devastated.
But I’ve shared my full local demo video — where everything works perfectly: real prompts, real YAMLs, real LLM inference.
🧡 Thank you for reading.
This isn’t just a tool. It’s the story of how I stopped being afraid and started building.
– Aswathi VK
Built With
- docker
- faiss
- fastapi
- github
- graphql
- hugging-face-spaces
- kube-linter
- markdown
- mistral-llm
- mock-response
- ollama
- python
- yaml

Log in or sign up for Devpost to join the conversation.