Inspiration
Every compliance team knows the feeling: the auditors call at 5 PM and arrive at 9 AM. What follows is a frantic night of manual database queries, cross-referencing spreadsheets, chasing down ghost employee IDs, and praying nothing slips through. The problem isn't intelligence — it's bandwidth. Human analysts can only move so fast.
We asked a simple question: what if one sentence was enough?
Not "summarize this data." Not "answer my question." But genuinely — investigate this database, find every violation, fix what you can, and hand me a signed PDF post-mortem before the auditors walk in.
That question became Genesis.
What It Does
Genesis is an autonomous financial intelligence agent built on Gemini 2.5 Flash and LangGraph. You type one prompt. It deploys eight specialist agents that write their own Python scripts, execute them in an isolated sandbox, read and write to MongoDB, detect money laundering networks across 50,000 transactions, and generate a full PDF post-mortem — all without you lifting a finger after that first sentence.
Three investigation modes:
🔍 Fintech Compliance Audit
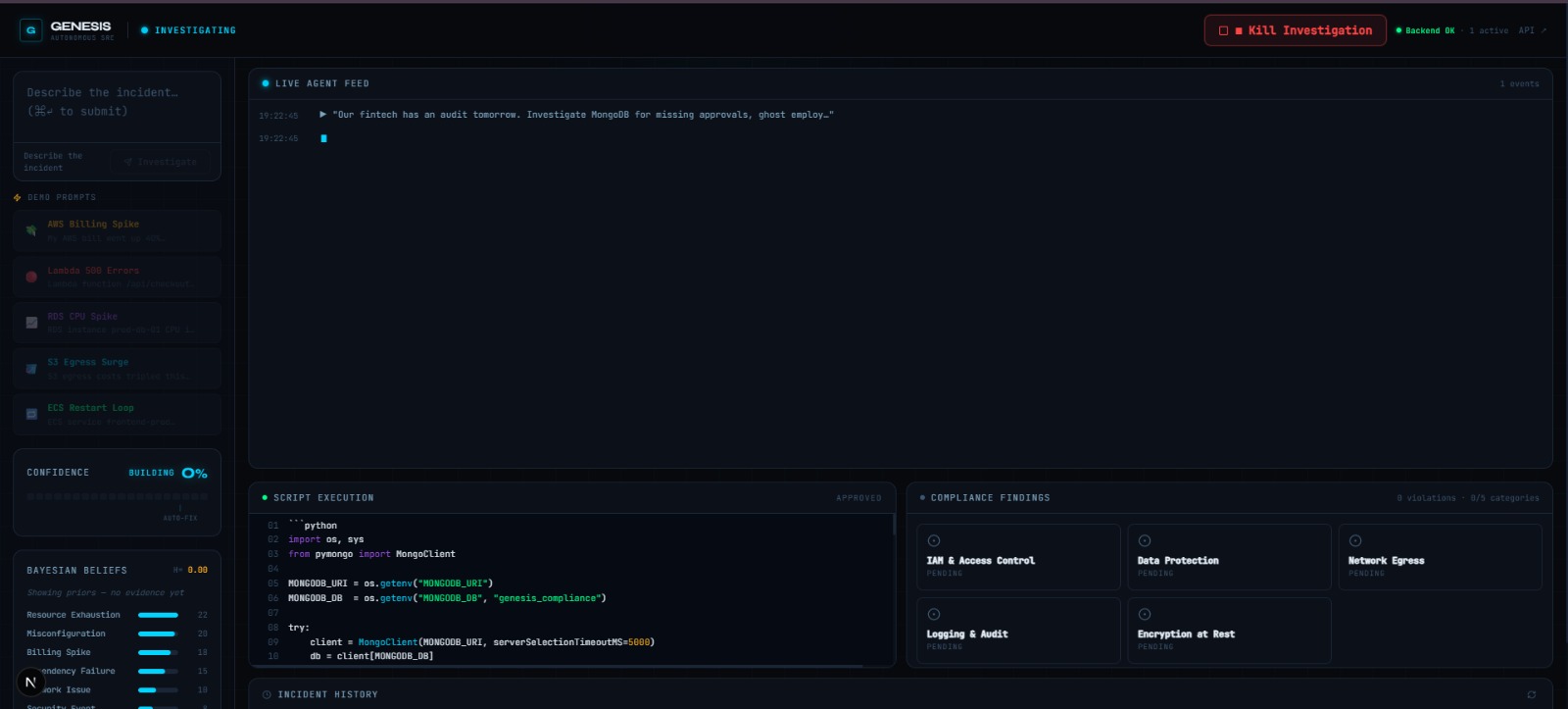
"Our fintech company has an external audit tomorrow. Investigate our MongoDB database for compliance violations."
Genesis finds five violation categories autonomously — missing approvals, ghost employee IDs, deactivated approvers, role violations, and incomplete audit trails. Then it fixes them. It writes corrective entries back to the database, by itself, after asking your permission first.
🕸 AML Network Investigation
"Investigate our IBM AML transaction dataset for money laundering networks."
Genesis reads 50,000 transactions, builds a directed graph with NetworkX, and detects four money laundering typologies: fan-out smurfing, fan-in aggregation, circular flows, and structuring below the \$10,000 reporting threshold. The frontend renders a live D3 network graph of flagged accounts.
💼 Wealth Management Analysis
"Analyse our client portfolio data for risk concentrations and flag anomalous trading."
Genesis segments clients by wealth tier, computes Herfindahl diversification scores, detects wash trading and velocity anomalies, and generates personalized rebalancing recommendations — one per client.
The moment that made this feel real came during testing:
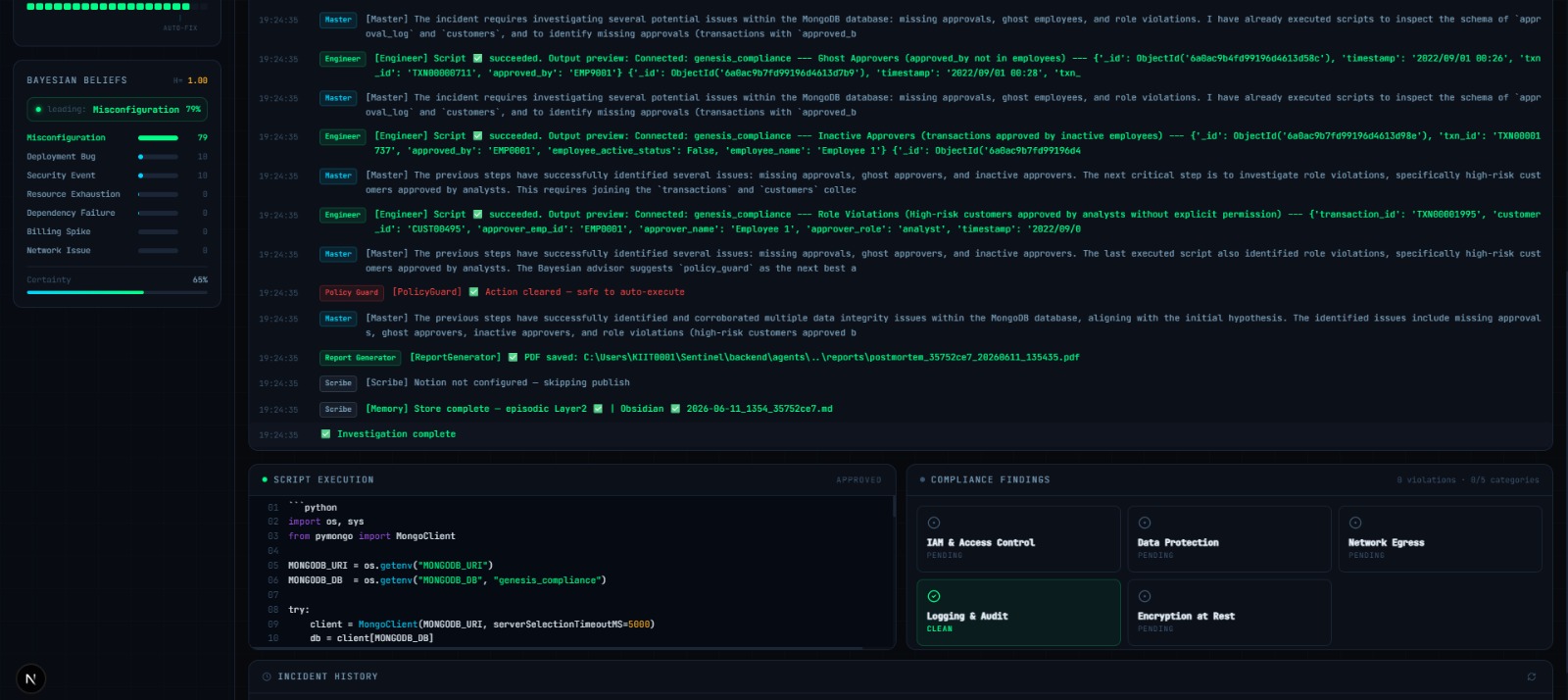
[Engineer] Script ✅ succeeded.
Created audit log entry for missing approval: TXN00003773
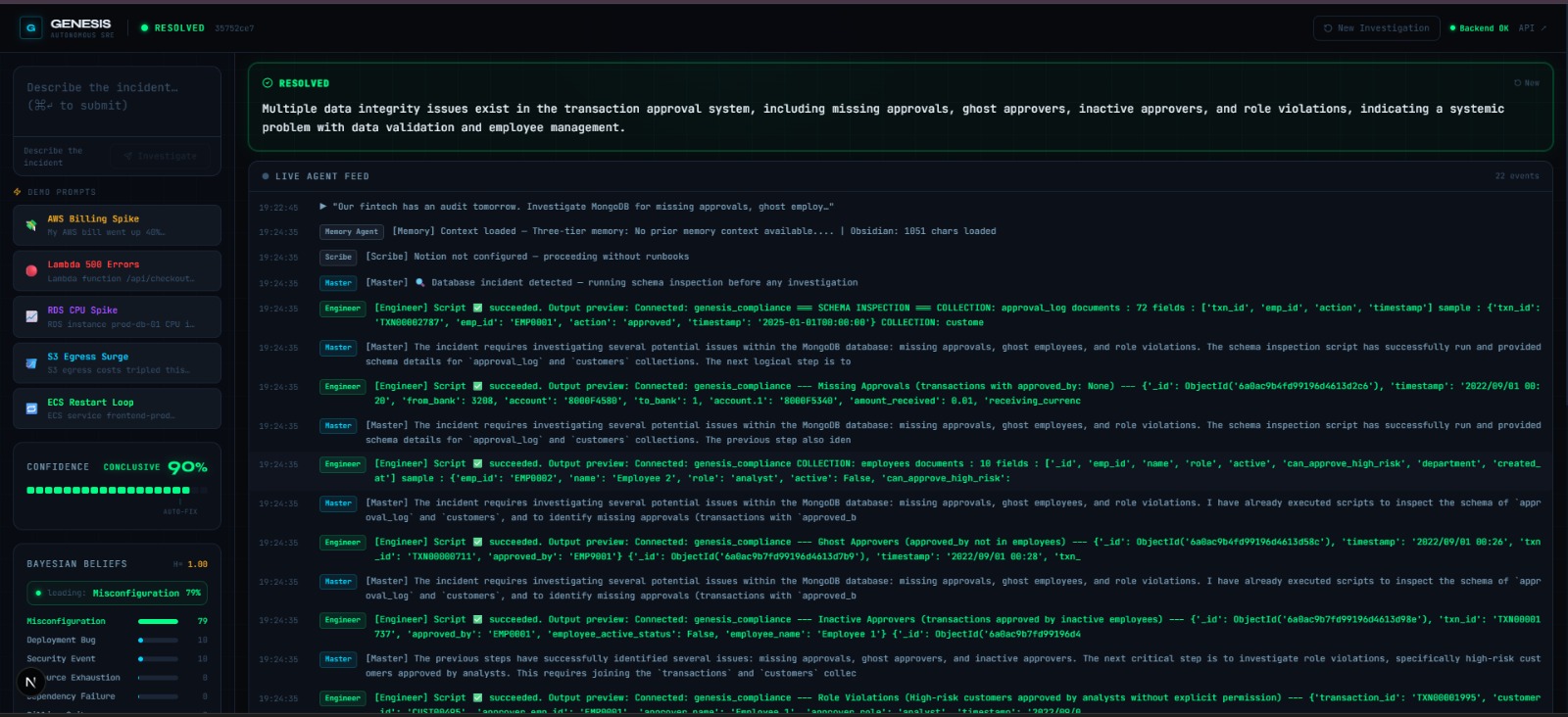
An AI agent found a compliance violation and fixed it in a production database. That is not a demo feature — that is the default behaviour.
How We Built It
The Eight-Agent Pipeline
The architecture separates thinking from doing at every layer:
You → Master Orchestrator → Approval Gate → Engineer
↓
Scout · Analyst · Policy Guard · Scribe
Memory Agent · Report Generator
- Master reasons and routes using Gemini 2.5 Flash + LangGraph. It never executes anything directly. Every output is structured JSON with a 3-attempt retry loop.
- Engineer writes Python and runs it inside an E2B sandboxed environment. It retries on failure, intercepts graph data markers, and streams results back via SSE.
- Approval Gate pauses before every script execution, shows the exact code, a plain-English explanation, and the Master's reasoning — then waits for human approval before proceeding.
- Policy Guard maintains a blocklist of destructive operations (
drop_database,terminate_instance,delete_bucket, etc.) and forces a full halt requiring explicit human approval. - Scout uses Firecrawl to fetch documentation and runbooks on demand.
- Scribe reads Notion runbooks at investigation start and publishes the post-mortem at the end.
- Memory Agent manages a three-tier Supabase memory store.
- Report Generator produces a ReportLab PDF with findings, evidence, confidence scores, and full timeline.
The Self-Improvement Loop — Arize Phoenix
This is the architectural centrepiece of the Arize track integration. Every Gemini call is auto-instrumented. Every script execution is a named span. Every failure is a structured event with full context.
Investigation 1: Script fails — KeyError on field "employee_id"
Phoenix records the failure as a structured trace
Investigation 2: Master queries Phoenix MCP → "what failed last run?"
Phoenix returns: employee_id → emp_id was the fix
Master writes the correction into working memory
Script succeeds on first attempt
Genesis gets measurably better across investigations. Open the Phoenix dashboard, run two investigations on the same dataset, and watch the error rate drop. The improvement is not inferred — it is directly observable.
The Research: BAIRA
Standard LLM agents pick their next action by intuition. We framed investigation as a POMDP — Partially Observable Markov Decision Process — under the Bayesian Active Investigation and Response Architecture:
$$a^* = \arg\max_a \frac{H(B) - \mathbb{E}[H(B' \mid a, o)]}{\text{cost}(a)}$$
Where $B$ is the current belief distribution over root cause categories, and the numerator is the expected information gain from taking action $a$. The selector runs in pure Python before every LLM call — zero API cost — and injects a ranked action suggestion into the Master's context. Historical root cause priors are derived from real incident data and updated as investigations complete.
The Three-Tier Memory System
| Layer | Contents | Cost |
|---|---|---|
| Layer 3 — Semantic Rules | Human-editable patterns promoted from recurring failures | ~500 tokens, flat forever |
| Layer 2 — Episodic Memory | Past investigations as vectors in Supabase, max 300 active | Decay = recency × success × confidence |
| Layer 1 — Working Memory | Ephemeral state in LangGraph AgentState for current run | Free |
The Watchdog
Proactive monitoring under \$1/day via token-gated triage:
- Tier 1 — Pure Python threshold checks every 5 minutes. Zero LLM calls.
- Tier 2 — Gemini Flash lightweight triage. Fires only when Tier 1 triggers.
- Tier 3 — Full Genesis pipeline. Runs only when Tier 2 confirms a real anomaly.
The expensive model runs only when the cheap models agree something is wrong.
Challenges We Ran Into
Prompt brittleness in code generation. Early versions of the Engineer agent produced scripts that failed silently or used wrong field names. Wiring Arize Phoenix traces so the Master could read its own failure history before each new attempt turned this from a recurring bug into a self-correcting loop.
Bounded memory without runaway costs. Naive episodic memory grows unbounded across long-running agents. We built the three-tier architecture with decay scoring and a hard cap of 300 active episodes, with automatic promotion of recurring patterns into flat semantic rules that cost a fixed ~500 tokens forever.
Human-in-the-loop without killing autonomy. The approval gate needed to feel meaningful, not just a checkbox. The solution was surfacing the exact script, a plain-English explanation, and the Master's reasoning simultaneously — so every approval is an informed decision. The 60-second auto-approve keeps live demos running while still demonstrating the safety pattern to judges.
Safe autonomous database writes. Letting an agent write back to a production database required a genuine safety architecture, not just a prompt instruction. The Policy Guard maintains a hard blocklist enforced in code, not in the system prompt. Prompt injection cannot bypass it.
Accomplishments That We're Proud Of
Genesis fixed a compliance violation in MongoDB — by itself. It wrote Python, executed it in a sandbox, and created a corrective audit log entry. After learning from a prior failure via Arize Phoenix traces, it did this on the first attempt.
The self-improvement loop is directly observable. This is not a claim about the architecture — you can open Phoenix, run two investigations, and watch error rates fall as the agent applies what it learned.
Three production-ready investigation modes from one agent architecture. Compliance audit, AML detection, and wealth management are not separate systems — they are playbooks routed through the same eight-agent pipeline.
The Bayesian POMDP selector reduces convergence cost without touching the LLM. Pure Python. Zero API calls. Measurably fewer investigation steps to reach a high-confidence root cause.
What We Learned
The gap between a chatbot and an agent is not the language model. It is everything around it: memory that persists without growing unbounded, safety layers enforced in code rather than prose, sandboxed execution that isolates failures, human oversight that is genuinely informative rather than ceremonial, and observability that makes the agent's reasoning legible.
Arize Phoenix changed how we built Genesis in a fundamental way. Seeing every reasoning step as a structured trace — not as console logs — made failures diagnosable in minutes rather than hours, and turned the self-improvement loop from a theoretical feature into something we could actually watch work in real time.
We also learned that the hardest design problem in autonomous agents is not capability — it is trust. Every architectural decision in Genesis (the approval gate, the policy guard, the three-tier memory, the sandbox) is ultimately an answer to the question: how do you build a system that is powerful enough to be useful and transparent enough to be trusted?
What's Next for Genesis
Regulatory ruleset expansion — Pluggable compliance playbooks for GDPR, SOX, PCI-DSS, and Basel III, each as a structured prompt module loaded at investigation start.
Real-time streaming investigations — MongoDB Atlas webhook triggers that launch Genesis automatically when anomalous write patterns are detected, without waiting for a human prompt.
Confidence-gated autonomy — Below a configurable confidence threshold, Genesis escalates to human review rather than acting. Above it, it proceeds autonomously. The threshold is adjustable per organization.
Multi-tenant deployment — One Genesis instance, fully isolated investigation contexts per organization, with per-tenant memory and trace namespacing in Phoenix.
Adversarial red-teaming — A dedicated agent that attempts to construct prompts that bypass Policy Guard, with every attempt logged to Phoenix as a training signal for hardening the safety layer.
Built With
- amazon-cloudwatch
- arize-phoenix
- aws-cost-explorer
- d3.js
- docker
- e2b
- fastapi
- firecrawl
- gcp-cloud-logging
- gemini-2.5-flash
- google-cloud
- google-cloud-agent-engine
- javascript
- langchain
- langgraph
- mongodb-atlas
- networkx
- next.js
- notion-api
- openinference
- pgvector
- postgresql
- python
- reportlab
- supabase
- tailwind-css
- typescript
- vertex-ai


Log in or sign up for Devpost to join the conversation.