-
-
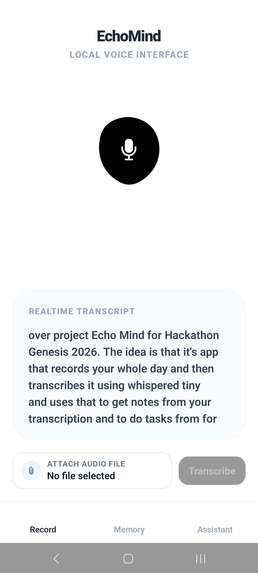
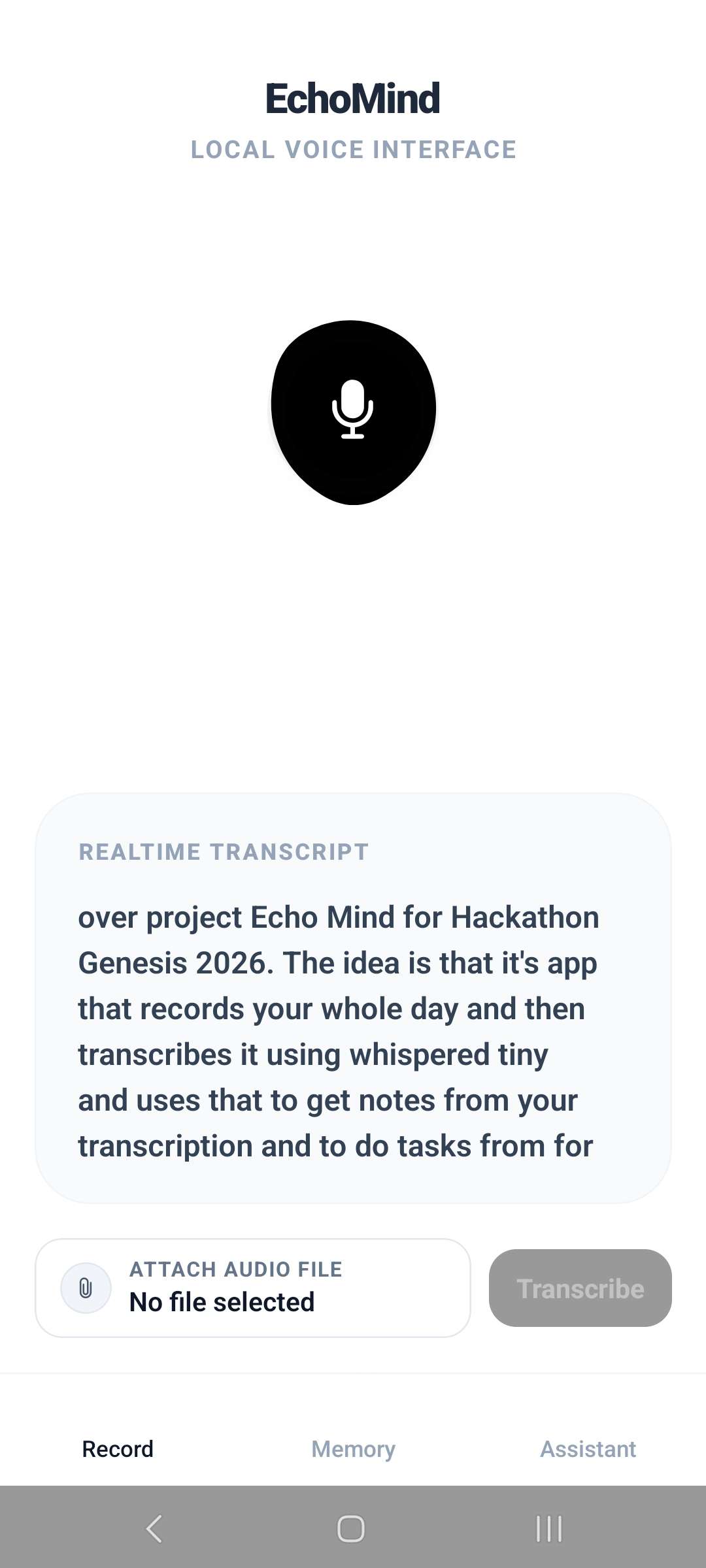
Live Transcription/File Upload
-
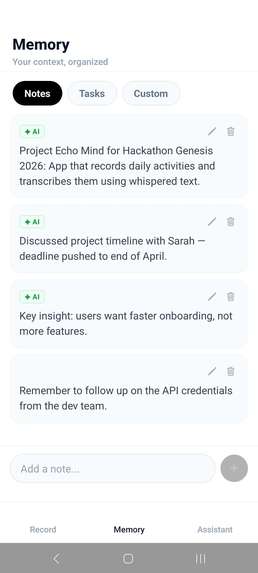
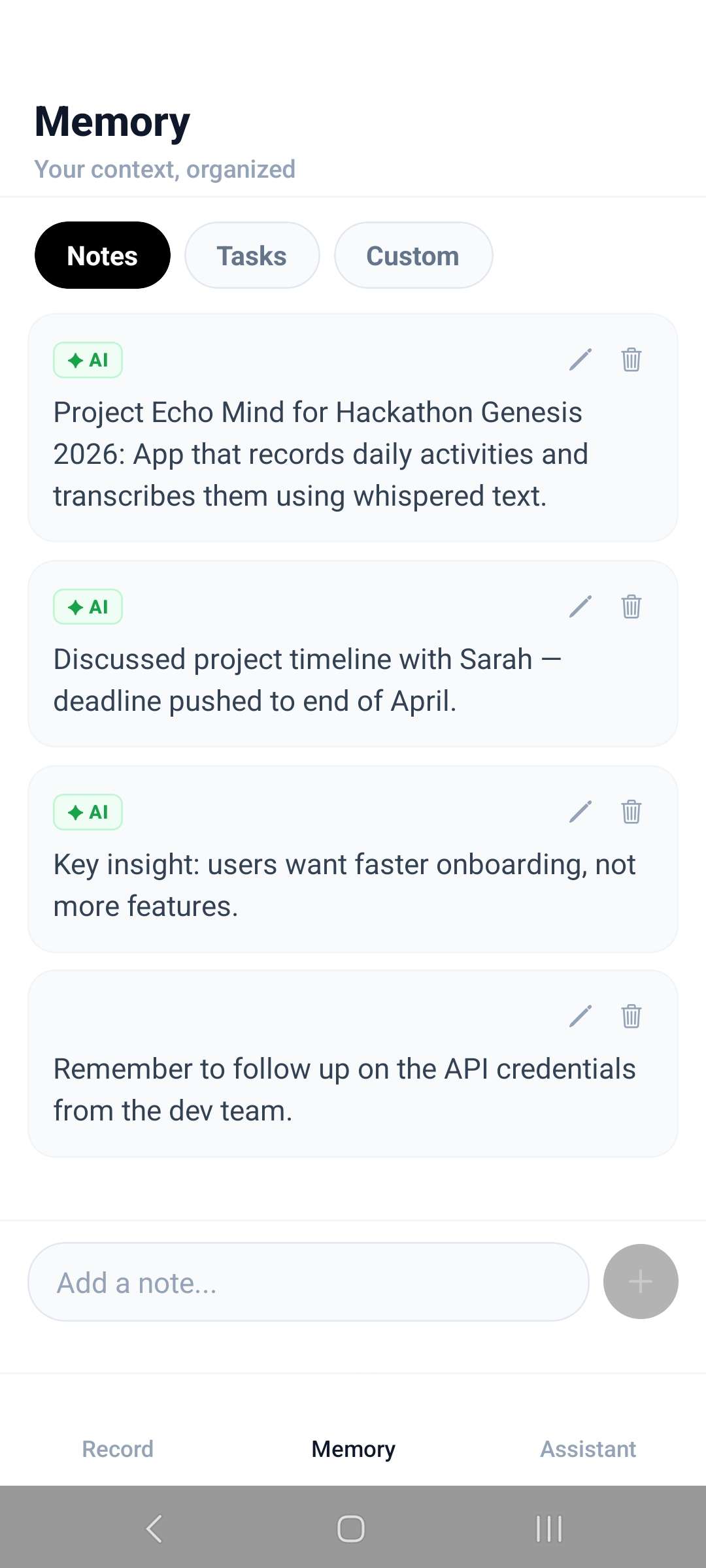
Notes taken from the live transcription
-

Chatbot given context from the audio file

EchoMind
Inspiration
We spend our lives in conversations, meetings, and sudden bursts of inspiration, yet most of that cognitive data is lost to time. Most AI assistants and “AI wearables” rely on always-on cloud connections, which means sensitive conversations are constantly being uploaded and processed remotely.
EchoMind was inspired by the idea of a local-only cognitive extension, a “second brain” that lives entirely on your device. The goal was to create a tool that can listen, remember important details, and help organize ideas throughout the day without sending any personal data to the cloud.
By running entirely on-device, EchoMind demonstrates how generative AI can augment human memory while still preserving user privacy.
Product Summary
EchoMind is a mobile application that functions as a private, on-device AI assistant capable of listening to conversations and extracting meaningful information from them.
When a recording session is started, the app continuously captures audio in the background—even while the device is locked. Speech is transcribed locally using an on-device speech recognition model, and a small language model processes the transcript to identify noteworthy information such as tasks, reminders, and key insights.
Instead of storing everything, EchoMind focuses on selective memory: extracting only the most important moments from conversations and turning them into structured notes. This allows users to revisit their day, recover ideas, and track important details without manually writing anything down.
Because all processing happens locally on the phone, EchoMind provides the benefits of generative AI without compromising privacy or requiring internet connectivity.
Technology Stack
Languages
- TypeScript
- JavaScript
- C++ (native bindings for AI inference)
Frameworks and Libraries
- React Native
- Expo
- Whisper.rn (on-device speech-to-text)
- Llama.rn (local LLM runtime for GGUF models)
- React Native Reanimated
- React Native SVG
- Notifee (foreground service handling)
Platforms
- Android mobile platform
- On-device AI inference using GGUF models
Tools
- Android Studio
- Node.js
- Git
How It's Built
EchoMind is built as a cross-platform mobile application using React Native and the Expo ecosystem. The core intelligence of the system runs entirely on-device through two main components:
- Whisper.rn – a native implementation of OpenAI’s Whisper model that performs high-accuracy offline speech-to-text transcription.
- Llama.rn – a runtime for running local LLMs in GGUF format. EchoMind currently uses Gemma 3 (1B) to analyze transcriptions and extract key insights.
To support continuous listening, the application uses a custom Android foreground service implemented through Notifee. This allows the recording session to remain active even when the app is minimized or the device is locked.
The user interface features a dynamic animated “blob” built using React Native Reanimated and SVG, which provides real-time visual feedback while the system is actively listening.
Challenges Faced
One of the biggest challenges was navigating Android 14’s strict background execution limits. Many foreground services are automatically terminated after a few minutes if configured incorrectly. Ensuring stable long-running recording sessions required restructuring the service lifecycle and using persistent microphone service types.
Another challenge was on-device inference performance. Running a billion-parameter language model on a smartphone requires careful memory management and selective processing. To reduce latency and battery usage, EchoMind only sends noteworthy transcript segments to the LLM rather than processing the entire conversation.
What We Learned
Building EchoMind required deep exploration of native-to-JavaScript communication in React Native. Managing multiple concurrent systems—audio recording, speech recognition, and LLM inference—while maintaining a responsive UI required careful thread management and performance optimization.
We also learned that effective AI assistants require selective intelligence. If an AI remembers everything, it becomes noise. If it remembers only the meaningful moments, it becomes a useful cognitive tool.
Math & Logic
The animated listening indicator is implemented using a dynamic vertex system where each vertex follows a periodic radial offset:
P_i(t) = R · (sin(ωt + φ_i) · scale + 1)
This produces a smooth organic motion that visually represents incoming audio energy, creating a responsive “living” interface during recording.





Log in or sign up for Devpost to join the conversation.