-
-
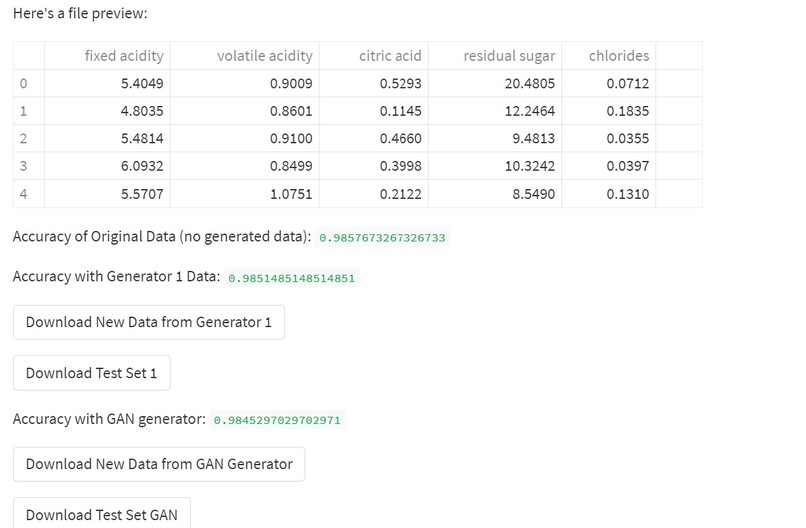
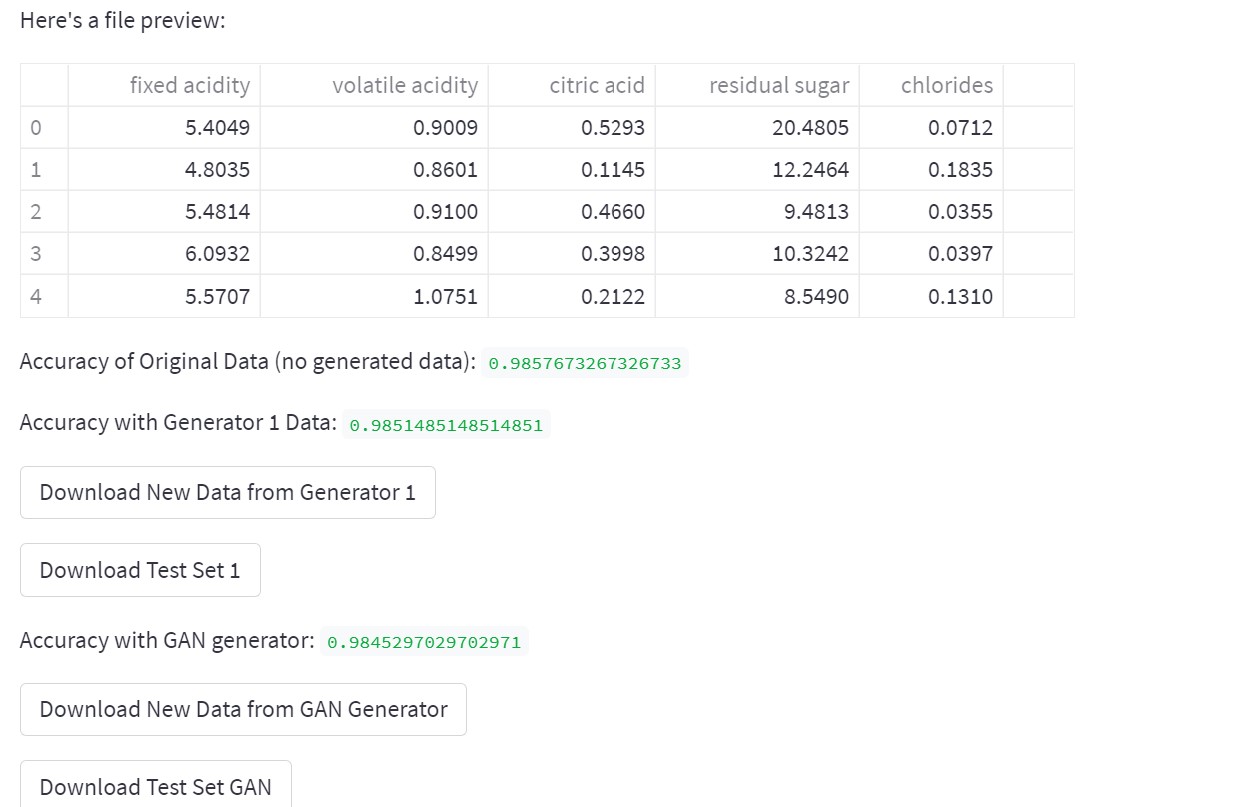
Validated results from generation
-
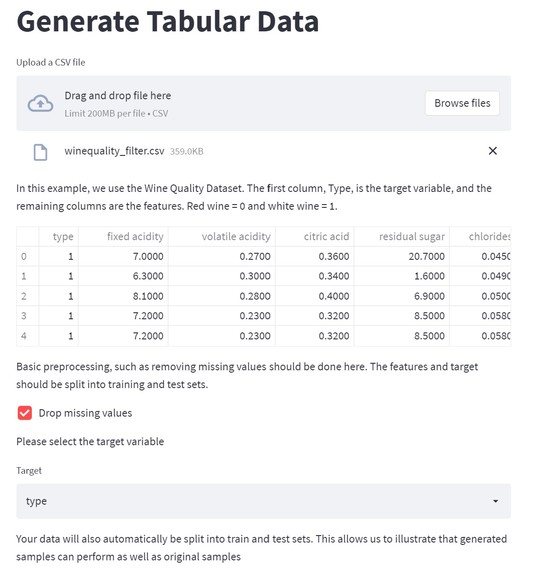
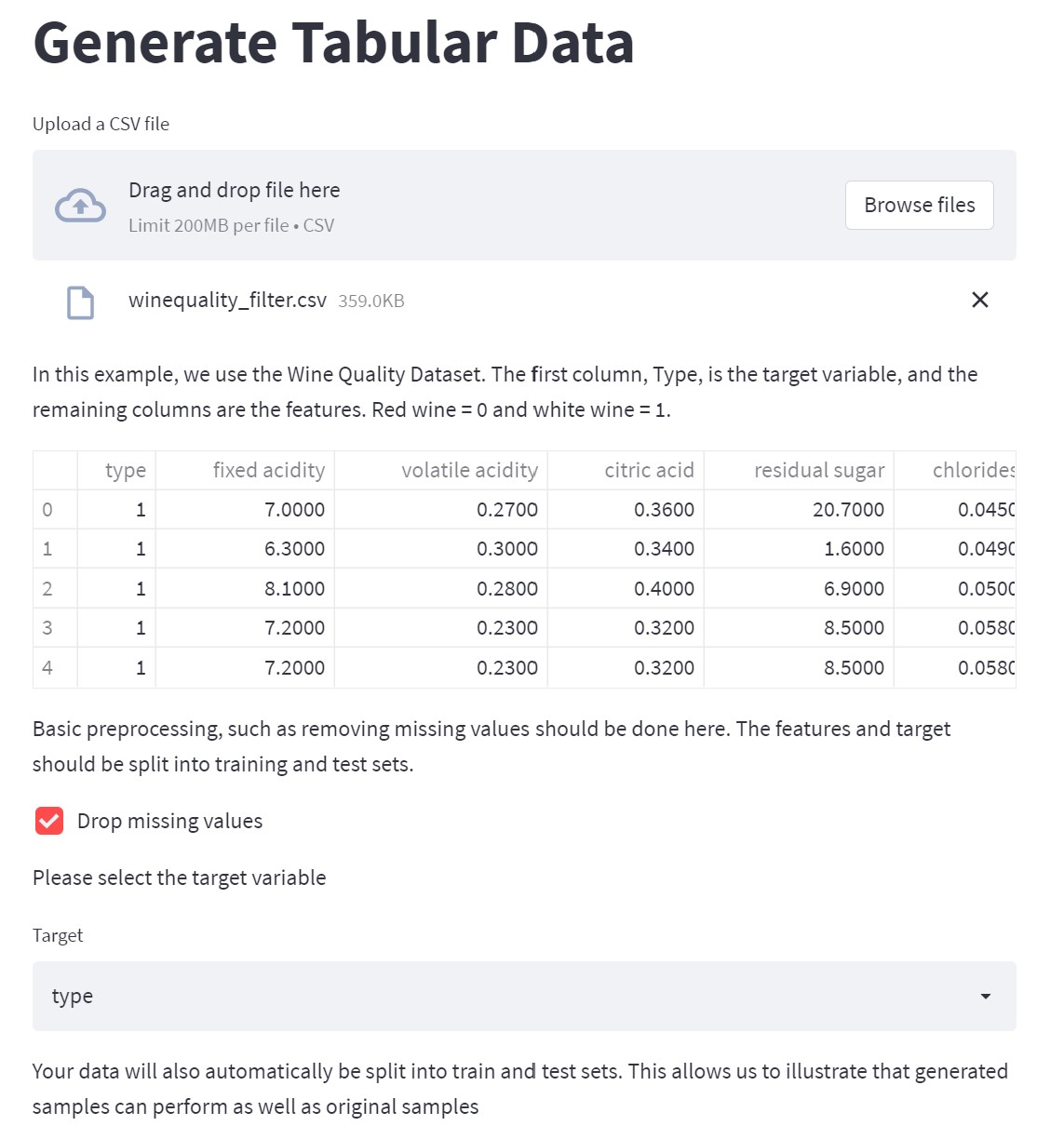
Preview of the uploaded dataset and basic preprocessing steps
-

Images generated from

Inspiration💡
As machine learning enthusiasts, we're bubbling with ideas, but sometimes it's hard to find adequate data for training our models. Whether it's images, text, or tabular data, models almost always tend to perform better with quality data. With this in mind, we've always wondered if we can generate new data with added noise and quirks based off of our input samples. Users can further use these additional samples to train their model, which leads to better model performance across unseen samples. This tool would not just help only hackers, but professionals across all different fields, from generating pictures of rare birds to scarce realistic data.
What it does🗒️
This application helps users generate new and related images or data for training a more reliable machine learning model. Users who use to generate additional rows of tabular data are prompted to upload and preprocess the data on the screen. They are given the option to drop columns and remove rows with missing values prior to data generation. After data generation, a user is allowed to download the generated data to their liking. Similarly, users who choose to generate images are also given the option to upload a set of images to the application. Images are generated based on previously determined model weights and displayed to the user. The user is given an option to download the set of generated images.
How we built it💻
Tabular Data Generation:
- User is prompted to upload a CSV file, which is read through the system.
- Specific preprocessing steps (such as dropping values and columns) are executed as directed by the user's choice through the web interface.
- The data is passed through tabgan's generator and validated through regression or classification models to ensure data quality.
- Sample data points are shown to the user and metrics are computed to ensure data quality.
Image Generation
- Images are read in through the application
- The images are fed into a customized neural network that is built using Pytorch.
- Weights were determined from training and are applied to the model to generate similar images with some noise.
- Generated images are shown back to the user.
- Note that in our demo, we show a few classes of trained data to show the results of the model. Training done in real time would be too slow to deploy to Streamlit (we're working on this!).
Challenges we ran into📝
- As image and data generation is a fairly new topic, there is not a lot of digestible information written about existing methods. Most of the work and theory revolving around image and data generation are explained in research papers. It was our first time reading computer science focused research papers (linked below). With the complexity that went into building such neural network models, we realized that we were unable to use the scikit-learn library, which we were both familiar with to implement our neural network model. We used Pytorch for the first time to build our current model.
- Our initial run comprised of running our newly built neural network for ten iterations. Surely, we did not expect our model to run for more than 5 hours! While we didn't have the proper computing power on our laptops, we realized that our project was far too ambitious without upgraded GPUs. Our idea of training a neural network for every set of image inputs would take a very long time, so we set off to find a set of generalized model weights that would work for image generation instead. We opted to train our model with a larger and more varied dataset, which in turn would return fine-tuned multipurpose model weights that can be used to generate any image. It would save us and the user a lot of time hours from finding model weights for each iteration of model generation.
Accomplishments that we're proud of🎉
We are proud of being able to come up with a rough and working prototype for our hack. We didn't expect ourselves to be able to learn how to use the technologies we used this weekend. In addition, the theory behind these topics are relatively new, and likely much harder than the theory that is taught in regular computer science classes for undergraduates. We're proud that we were able to get through this and provide a video demonstration of it.
What we learned📋
We learned a lot about the theory behind transfer learning and Generative Adversarial Networks. While it was hard to decipher research papers with dense computer science terms, we were able to break it down and learn a lot about the complex algorithms that drive the face of data generation. We also learned how to use PyTorch to build a customized neural network, and how to deploy our work to Streamlit.
What's next for Generate It🪄
- Add more preprocessing options for the user, such as feature scaling and built-in one hot encoding for categorical data. For image generation, we would like to present an option for the user to remove the background and apply specific filters to make image generation less time intensive.
- Allow users to customize the model (without any code!).
- Optimize the code such that the neural network itself can be shown relatively quickly via Streamlit.
Prize Categories
First Hackathon Birthday
Exactly 50% of our team are first time hackers!
Best Domain Name from Domain.com
Our two submissions are: www.i-need-data.tech; www.generate-it.tech
Best Hack for Hackers
We believe that this hack can truly make a difference for hackers who are planning to work on analytics or machine learning hacks. It's often frustrating to find relevant data online, and there can be cases where there isn't enough data to sustainably train a model or perform analytics. Our hack makes it possible for hackers to worry less, and focus on their project more with limited data.
Best use of Github
Our team used Github as our main source of code sharing and collaboration. We've added a README page and used git commands to sync our work with each other. We learned about workflows in Github this weekend and decided to try it out by adding our own workflow on Github Actions. We will continue to work with this feature and add some unit tests to it in the future.
Dream Big and Create More Cheers with AB inBev
We think that our hack truly fits the theme of "Dream Big," as our hack might've been a little too ambitious for the current technology we own to handle. Besides that, we definitely think it would make the hacker community of machine learning enthusiasts a lot more happier when they're able to run their models with ease.
Log in or sign up for Devpost to join the conversation.