-
-

Training a model on the DL1 instance with HPU device
-

Preview of Training Set (Real data)
-

Generated samples during training
-

Generated samples during training #2 (1230 epoch)
-

Generated samples during training #3 (500 epoch)
-

Generated samples during training #4 (100 epoch)
-

Generated samples during training #1 (epoch ~6K+)
-
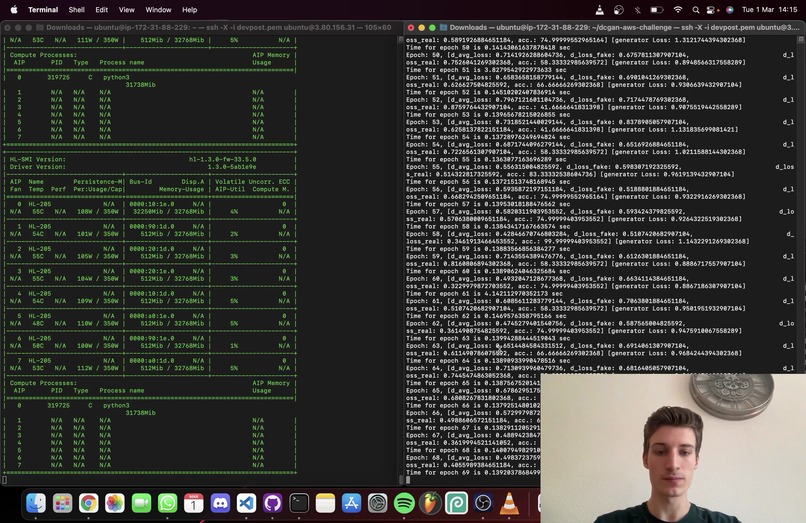
Training DCGAN with HPU using 1 Gaudi Core (1 worker) - snapshot from demonstration
-
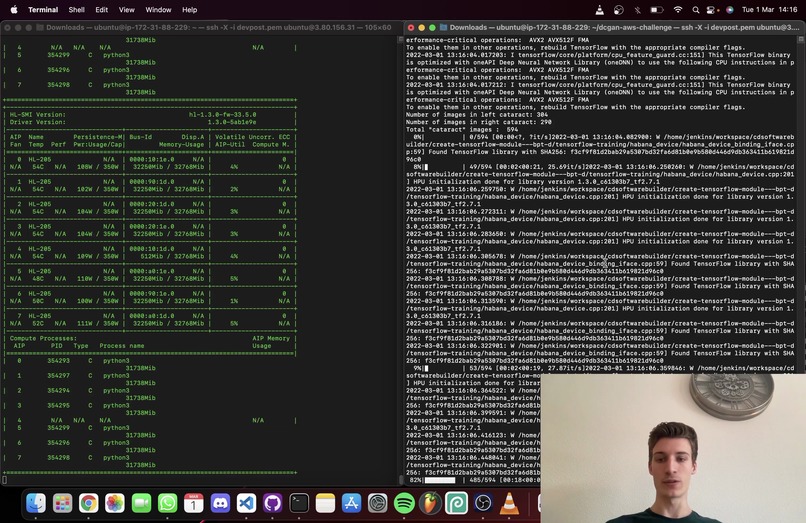
Horovod Distributed Training on 8 Cores (8 workers) - snapshot from demonstration
-

Intro
-

Project summary
-

How I've build my project
-

My approach to Gaudi/Habana framework & Horovod
-

Use of Gaudi & Horovod
-

Use of Gaudi & Horovod
-

Confirm use of Habana framework / Gaudi
-

Future work
-

Links


















Inspiration
I come from a company where I've worked on AI applications that had medical use-cases. I worked before with Classification and Object Detection networks/models but I had no prior experience with GANs, so I wanted to learn more about it. When I started with this challenge, I took a deep dive into how GANs work and came up with the idea to use GANs as a tool to generate synthetic data for medical purposes. So, I went searching on Kaggle for datasets but I wanted to try a unique dataset. After searching for a while I came across ODIR (Ocular Disease Intelligent Recognition) dataset. This dataset was used for disease recognition, but the class 'Cataract' had only 500+ images, so I thought, why not try to produce more data based on these images?
What it does
It tries to generate synthetic data (mimic) based on real-life medical data. In this case, it's generating samples that are based on 'Cataract' disease images. If you would like to see some results, please click on the right arrow next to the video above this page. I've uploaded a preview of what the training set looks like and images of generated samples during training.
You can also find more information about my project in my presentation: https://bit.ly/3pqYz06
How I built it
- Custom DCGAN Model Architecture (Incl. Batch & Instance normalization for better style transferring)
- TensorFlow, Python
- Habana Framework
- Use of HPU devices (Gaudi cores)
- Horovod implementation for Distributed Training
Dataset
I'm using an Ocular Disease dataset from Kaggle called "ODIR" that contains images of the eye disease called 'cataract'. Cataract is a "cloudy" area in the center of the eye that leads to a decrease in vision. The goal of the model is trying to generate new data out of the given images. If you are curious about what the images of the disease look like, you can find them in the project media. It shows a preview of the training set that is used.
Ocular Disease Intelligent Recognition (ODIR) is a structured ophthalmic database of 5,000 patients with age, color fundus photographs from left and right eyes, and doctors' diagnostic keywords from doctors.
This dataset is meant to represent a ‘‘real-life’’ set of patient information collected by Shanggong Medical Technology Co., Ltd. from different hospitals/medical centers in China. In these institutions, fundus images are captured by various cameras in the market, such as Canon, Zeiss, and Kowa, resulting in varied image resolutions. Annotations were labeled by trained human readers with quality control management. They classify patients into eight labels including:
- Normal (N),
- Diabetes (D),
- Glaucoma (G),
- Cataract (C),
- Age related Macular Degeneration (A),
- Hypertension (H),
- Pathological Myopia (M),
- Other diseases/abnormalities (O)
Dataset URL: https://www.kaggle.com/andrewmvd/ocular-disease-recognition-odir5k
Challenges I ran into
- Creating a stable GAN architecture (Discriminator and Generator model)
- Implementing Habana and optimizing the DCGAN model architecture for Habana and HPU devices
- Optimizing operations for HPU usage
- Distributed Training with Horovod
Accomplishments that I'm proud of
- From no prior experience in GANs, to creating & understanding how it works. I learned different types of GAN networks, architectures, operations, normalizations (InstanceNormalization, Spectral Normalization), etc.
- Creating a working DCGAN network that produces 'decent' results after training for a while. I'm curious what the results would look like if I had the chance to run the training for a long period of time. Especially on the DL1 instance.
- Implementation of the Habana framework
- Implementation of Horovod
- Gained experience with AWS (and DL1 instance)
What I learned
- How GANs work (I had no prior experience with GANs)
- How to make use of the Habana framework to improve training efficiency
- Using Horovod for Distributed Learning
- Working with AWS and AWS instances (DL1, AMIs)
- Overall state-of-the-art techniques
What's next for Generate Synthetic-data for Eye Disease Cataract using DCGAN
- Finishing my own custom Data Augmentation Algo, specially written for this project. The algorithm is called “New Data by Combining (NDC)”. You can find an explanation about NDC here: https://bit.ly/35DAFat
- Use more data for the training set
- Hyperparameter tuning, using RayTune in combination with Horovod
- If results aren’t improving after the above implementations, maybe switching to another model architecture would help (CGAN, Encoder GAN, StyleGAN, etc).
Generated samples
Note that most of the shown samples in my project media are generated in the beginning stage of the training process. Most of the samples are generated below the < 1230 epochs except for one. I forgot from which epoch it was, but I can vaguely remember it was a few thousand epochs (which is still in the beginning phase of the training process for a GAN network).
More information
For more information about this project, see my presentation here: https://bit.ly/3pqYz06
Built With
- amazon-web-services
- dcgan
- dl1
- gan
- habana
- horovod
- tensorflow











Log in or sign up for Devpost to join the conversation.