




Inspiration
In the era of precision medicine, identifying pathogenic variants from vast genomic datasets and providing robust clinical evidence is critical for saving lives. Yet, current workflows are a formidable beast: VCF files are unwieldy, public databases are fragmented and hard to integrate, and manual annotation is time-consuming, error-prone, and slow. Imagine doctors and researchers bogged down in this data quagmire, unable to swiftly gain critical insights when facing time-sensitive diseases like lung adenocarcinoma.
Our inspiration stems from a strong desire to solve this very pain point! We firmly believe that through automated, intelligent data processing and evaluation, we can give time back to the clinic and bring precision to treatment, accelerating every patient's path to recovery.
What it does
GeneInsight is a high-performance, automated platform for genetic variant analysis. It can:
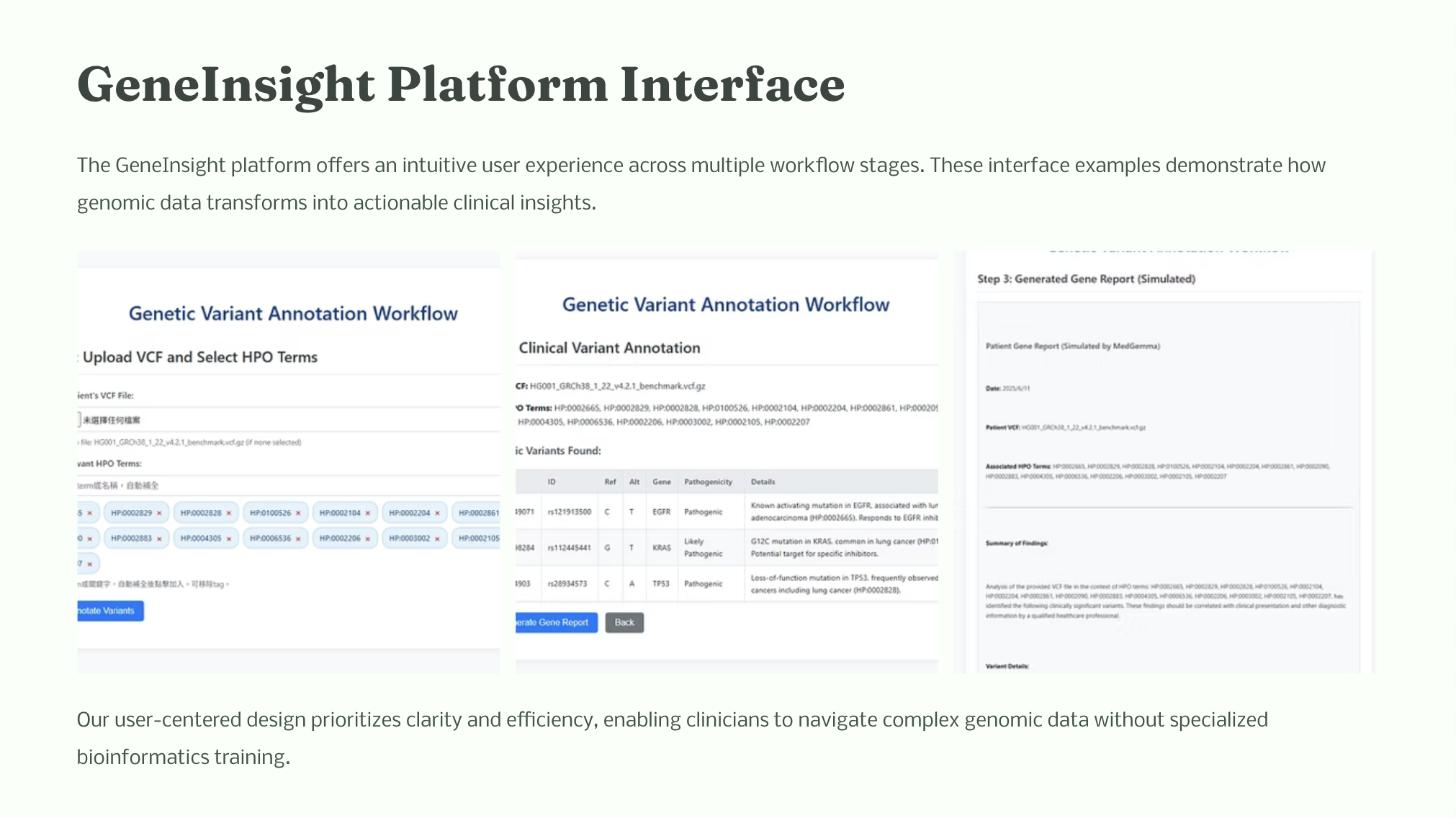
Automate Variant Annotation: Seamlessly integrate and automatically annotate genetic variants from raw VCF files with the most authoritative global public databases (e.g., ClinVar, gnomAD, dbSNP), providing comprehensive and up-to-date background information.
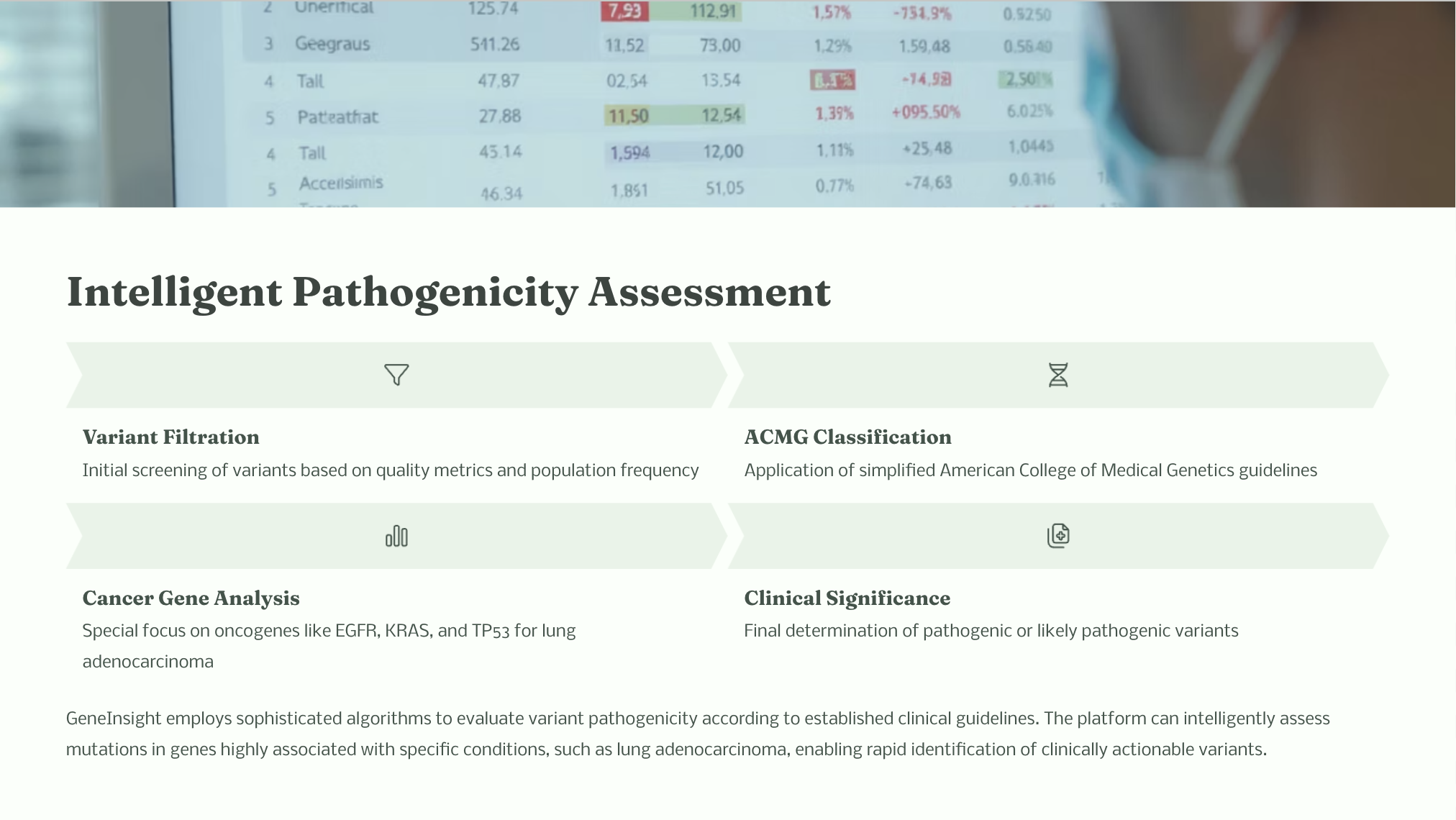
Intelligent Pathogenicity Assessment: Incorporate a simplified ACMG guideline to intelligently assess variants based on their clinical significance, population frequency, gene functional impact, and presence within disease-specific gene panels (such as our lung adenocarcinoma gene panel). It outputs clear pathogenicity classifications (e.g., Pathogenic, Likely Pathogenic, VUS).
Provide Clinical Evidence: Beyond just classification, it offers a detailed list of evidence behind each pathogenicity determination, helping clinicians quickly understand and validate the results. This serves as powerful substantiation for crafting precise treatment plans.
Accelerate Clinical Decision-Making: All raw data, rich annotations, and intelligent assessment results are centrally stored in the cloud database MongoDB Atlas, providing a foundation for rapid querying and data visualization. This significantly reduces the time from genomic data to clinical insight.
Automate Genetic Analysis Report Generation: By combining assessment results with all annotation information, we leverage advanced MedGemma to automatically generate a structured, easy-to-understand genetic analysis report. This dramatically streamlines the clinical reporting process, ensuring accuracy and consistency.
Our goal: To transform genomic information from a challenge into a powerful tool that empowers clinicians.
How we built it
We built this efficient and flexible solution from the ground up, with meticulous care:
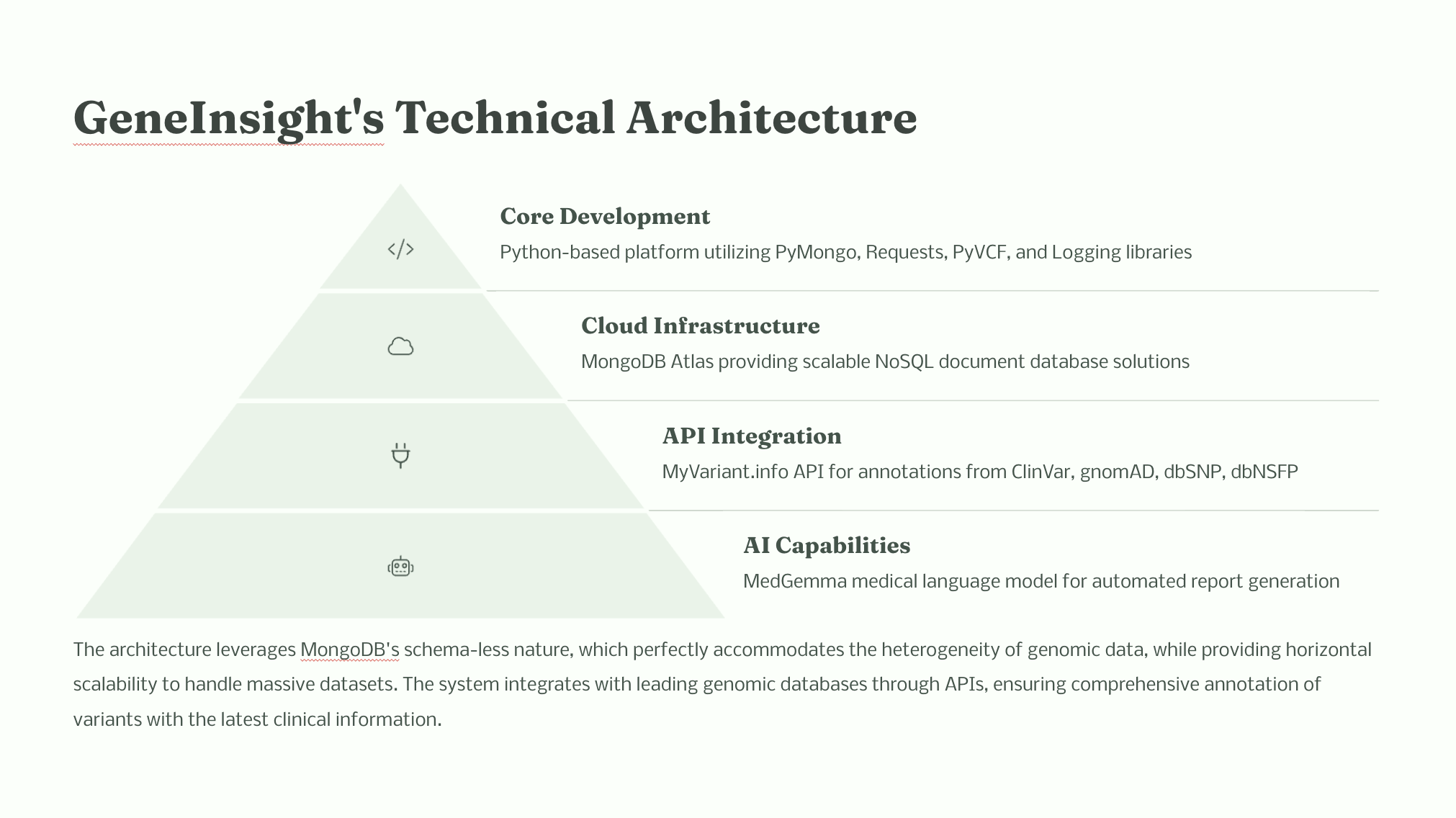
Cloud Database Foundation — MongoDB Atlas (Enhanced Description): We chose MongoDB Atlas for its NoSQL document-oriented flexibility and horizontal scalability. The heterogeneous nature, massive scale (from GB to PB levels), and constantly evolving annotation standards of genomic data make MongoDB the perfect choice. It doesn't require a rigid, predefined schema, effortlessly handling data complexity. Furthermore, through its powerful indexing and aggregation framework, it enables high-performance read/write operations and complex queries on vast datasets. Atlas's high availability and fault tolerance mechanisms also ensure the stability and reliability of critical clinical data.
Efficient VCF Processing: For large VCF files like NA12878, we implemented a chunking (batch processing) strategy. Using the PyVCF library, we read data in batches, significantly reducing memory footprint and ensuring efficient handling of multi-terabyte genomic datasets.
Single-Point Annotation Integration: Say goodbye to tedious, multiple API calls! We cleverly utilize MyVariant.info, an integrated API service, to obtain comprehensive annotation information from multiple authoritative databases (e.g., ClinVar, gnomAD, dbSNP, dbNSFP) with a single request. This greatly simplifies the code and enhances annotation efficiency.
Python Automation Engine: The entire workflow's core is driven by Python. We use the requests library for API interactions and implement a strict API request delay mechanism to respect the rate limits of various public databases, preventing service interruptions.
Intelligent Assessment Module: Our Python module incorporates a simplified ACMG pathogenicity assessment logic. This combines gene panel filtering (e.g., for lung adenocarcinoma), variant type, population frequency, and prediction tool scores to transform raw annotations into clinically relevant insights.
Genetic Report Generation Module: We will integrate Med-Gemini (or a similar medical-specific large language model). By sending structured variant information, pathogenicity assessments, and clinical evidence to its API, the model can automatically generate a detailed genetic analysis report. This includes a summary of the variant, explanation of clinical significance, background information on related genes, and clinical phenotype correlations based on HPO terms, significantly improving report writing efficiency and professionalism.
Challenges we ran into
This journey of innovation wasn't without its bumps; we wrestled with some "boulders," but each challenge made us stronger:
The Battle with API Rate Limiting: Public genomic database APIs often have request frequency limits, an invisible wall. Initially, we frequently encountered request blocks. Ultimately, we overcame this through a carefully designed delay strategy, ensuring each API call could complete successfully—a clever game with server rules.
Unlocking Complex Data Models: Genomic data structures are like "Russian nesting dolls," multi-layered and varied in format. How to structure the vast, flexible JSON data returned by MyVariant.info into MongoDB while maintaining query efficiency was a significant brain-teaser. We spent a lot of time testing different document designs.
The "Art of Simplification" for ACMG Guidelines: The intricacy of ACMG pathogenicity assessment guidelines is awe-inspiring, but fully programmatic implementation for massive datasets is a huge undertaking. Our challenge was how to appropriately simplify the assessment logic while retaining clinical relevance, enabling efficient automation. This means our tool is a powerful "mine detector," not the ultimate "judge," but it vastly accelerates the "mine detection" process.
Performance Bottlenecks with Large Files: Although chunking effectively handles VCF file reading, API response times from MyVariant.info, network latency, and MongoDB batch insertion performance remain potential challenges for truly massive datasets. This prompts us to consider future parallel processing and distributed computing architectures.
Extraction of Unstructured Clinical Evidence: Much valuable clinical evidence is hidden within unstructured text (e.g., medical literature narratives). While the project conceptually incorporates HPO terms, automating the extraction and structuring of this unstructured data from medical literature and patient records requires more advanced NLP techniques—a starry sky for our future expansion.
LLM Report Generation & Accuracy Control: When integrating LLMs like MedGemma for report generation, ensuring the medical accuracy of the output, avoiding hallucinations, and conforming to clinical reporting standards presents challenges that demand precise prompt engineering and rigorous validation.
Accomplishments that we're proud of
We are incredibly proud of GeneInsight's achievements, as it's more than just software; it's a bridge to precision medicine:
Achieving End-to-End Automation: We successfully achieved high automation for the entire workflow, from raw VCF files to the identification of pathogenic variants with clinical evidence, and finally, the generation of genetic analysis reports. This means hours or even days of manual work can now be completed in minutes.
Accelerating Clinical Decision-Making: Our solution can significantly reduce the time clinicians spend obtaining crucial genomic insights. In diseases like lung adenocarcinoma, this isn't just about efficiency; it's about gaining precious time for patient treatment.
Building a Robust Data Foundation (Enhanced Description): Through MongoDB Atlas, we've established a flexible, scalable, and high-performance genomic data platform. It can handle massive variant data and, through its flexible document model and powerful indexing mechanisms, provides a reliable foundation for future advanced analysis, AI model training, and rapid data querying.
Integrating Diverse Intelligence: We successfully combined MyVariant.info's multi-source annotation capabilities, PyVCF's efficient parsing, our custom simplified ACMG assessment logic, and MedGemma's report generation capabilities to create a truly intelligent analysis engine.
Empowering Precision Medicine: Our project demonstrates that the interdisciplinary fusion of data engineering and bioinformatics can bring revolutionary changes to clinical research and diagnosis, bringing the dream of personalized treatment a step closer.
What we learned
Every code commit and challenge overcome has been a valuable learning experience:
The Power and Art of NoSQL: Gained a deep understanding of MongoDB's unparalleled flexibility in handling complex, diverse genomic data. Learned how to design more elegant document structures to maximize storage efficiency and query performance.
Mastery of the API Ecosystem: Acquired expertise in interacting effectively with public bioinformatics APIs, including smart selection of integrated services, managing rate limits, and handling/parsing diverse API responses.
Practical Experience in Large Data Strategies: Gained firsthand experience with the practical value of strategies like chunking for handling massive files, a valuable lesson for any future large data projects.
Translating Complex Science into Code: Learned how to break down abstract bioinformatics concepts (like ACMG guidelines) and translate them into executable, maintainable code logic—the art of combining science with engineering.
Collaboration of Software Engineering and Bioinformatics: Deeply appreciated the importance of good software engineering practices (e.g., error handling, logging, modular design) for building stable and efficient bioinformatics analysis tools.
Potential and Challenges of LLMs in Medicine (Added): Began exploring the immense potential of LLMs like MedGemma in automating medical report generation, while also recognizing the challenges of ensuring content accuracy, avoiding misinformation (hallucinations), and adhering to medical ethics.
What's next for GeneInsight
Our journey has just begun; GeneInsight has endless possibilities:
Deeper Intelligent Clinical Evidence Mining: Integrate more advanced Natural Language Processing (NLP) models to automatically extract richer, more precise clinical evidence from unstructured medical literature and electronic health records, even linking it to relevant clinical trials and drug response data.
AI-Driven Precision Pathogenicity Prediction: Introduce more advanced machine learning and deep learning models for more accurate reclassification of VUS (Variants of Uncertain Significance), reducing clinical uncertainty. We will explore AI models that combine multimodal data (e.g., imaging data, gene expression data) for a more comprehensive pathogenicity assessment.
Interactive User Interface and Visualization: Develop an intuitive, user-friendly web interface that allows non-technical clinicians to easily upload VCFs, query variants, review annotations and pathogenicity assessments, and gain quick insights through interactive visualizations.
Disease-Specific Model Optimization and Personalized Reports: Train and optimize specialized gene panels and assessment models for more specific diseases (e.g., different cancer types, rare genetic disorders), and leverage MedGemma to generate highly personalized genetic analysis reports based on disease characteristics and patient needs.
Community and Knowledge Sharing: Explore building a platform where researchers and clinicians can share validated variant cases and clinical evidence, collectively advancing genomic medicine and accelerating the translation and application of medical knowledge.
GeneInsight: Unlocking the mysteries of genes to illuminate the hope of life!

Log in or sign up for Devpost to join the conversation.