-
-
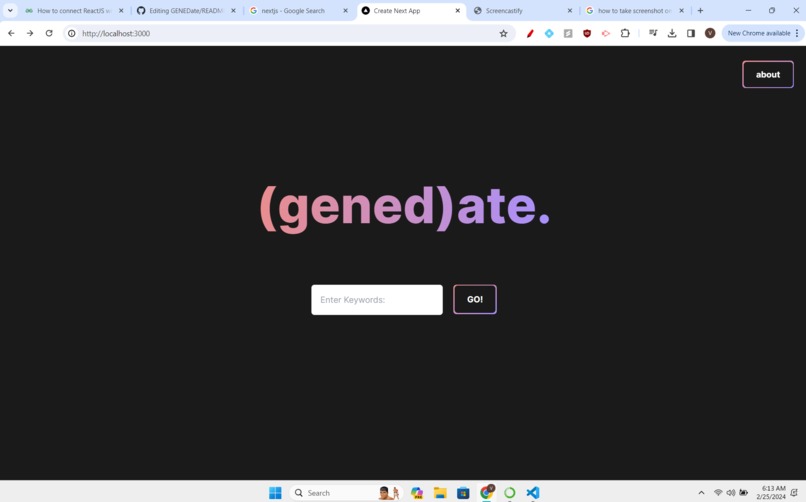
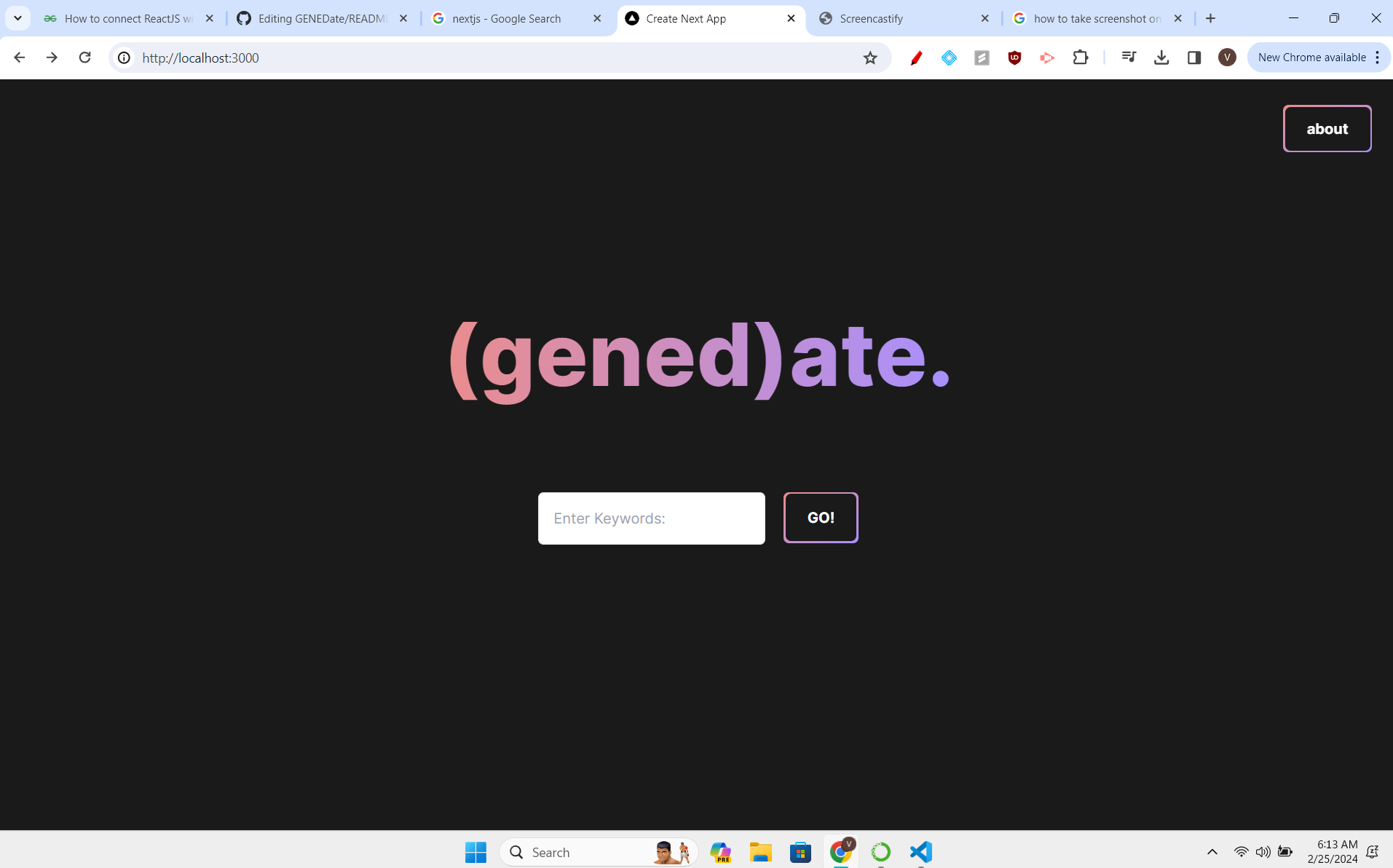
Landing Page
-
Loading Screen
-
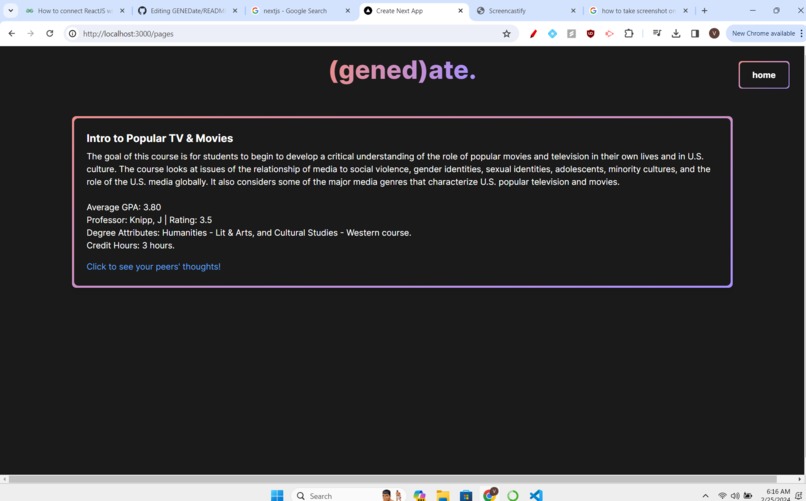
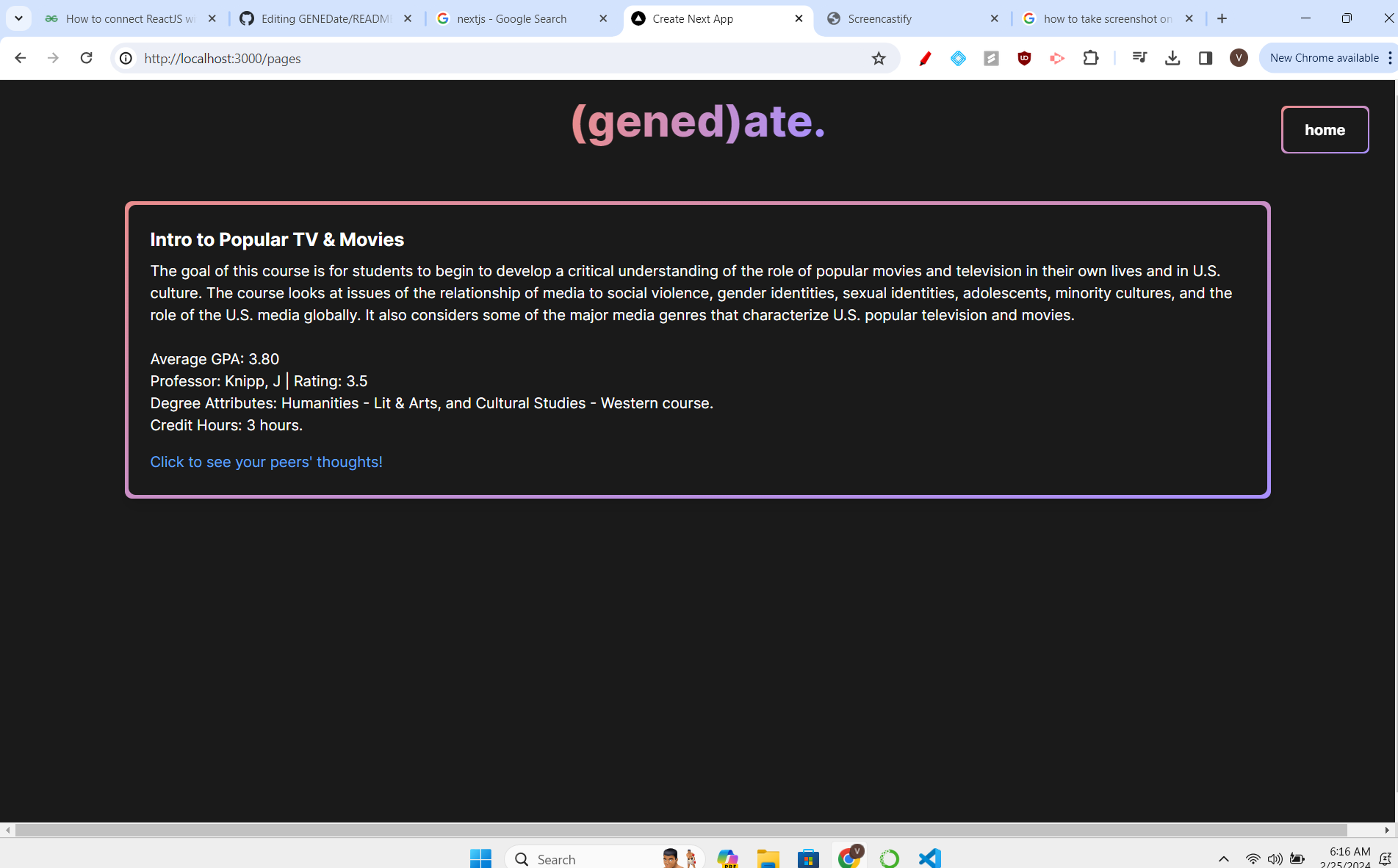
Result Page
-
About Us
Inspiration
We aren't ashamed to admit that we're not exactly the most ‘studious’ learners. The quest to find the easiest GenEd is nothing short of a sacred ritual as the semester looms. Hours would be spent on sites such as Rate My Professor, wading through an endless sea of lukewarm two-star roasts. Not long after, you'd find our browser tabs taking a detour to the Grade Disparity archives, hoping to find that magical 3.9+ Average GPA. Finally, we would pull up (shudder) Reddit, hoping to find our peers’ interesting experiences with these classes. What if there was a way to combine these resources into a singular efficient tool? Bing! Lightbulb moment!
What it does
(gened)ate is a web application that seeks to combine different sources of data with a natural language processor to recommend UIUC students the best GenEd possible based on their search inputs. Students will simply enter keywords, such as “Asian, Culture, Politics”, and be matched with a GenEd that fits their interests and needs. The classes are displayed with a plethora of different metrics, including descriptions, average GPA, a RateMyProfessor rating and a link to the class’s reddit page for more info. (gened)ate’s modern and minimalistic designs aims to make the search for GenEds a better experience for UIUC students.
How we built it
The creation of (gened)ate can be split into three different parts: Data Collection, Natural Language Processing, and Front/Backend development. In order to gather the data needed for our Natural Language model, we accessed UIUC class info data sets, and a public github API for RateMyProfessor. We combined all the class data into a CSV dataset, which we passed to our Natural Language Processor. First, we preprocessed all the data. The keywords from the text were extracted from rake_nltk, a powerful Python library. This included stemming words so words like ‘history’ and ‘historical’ would be matched together. We also expanded the keywords to synonyms, so words similar in meaning could match. Finally, we implemented the Cosine similarity algorithm which encoded the user keywords and text keywords as vectors, and compared them to get a similarity score. We iterated through all the Gen Ed descriptions to find the highest similarity score that determined the best match. The last major aspect of our project was the creation of an application which integrates a TypeScript application with Next.js, React, and Flask. The aim of our web application was to remain modern and easy to use, so we focused on creating gradient colors and a straightforward User Interface.
Challenges we ran into
Over the course of our 36 hours in production, we ran into a couple of notable problems. First, we faced obstacles in implementing the Natural Language Processing Algorithm. The biggest challenge we faced with the NLP algorithm was determining the tradeoff between runtime and accuracy. Some of the algorithms and models we wanted to use were more accurate, but they took too long to run so we had to find the perfect balance between viability and speed, which we found with the cosine similarity function and Rake. Another challenge that we encountered was cleaning and preparing the data for our model. There were many null values, inconsistent strings, and other miscellaneous issues that we needed to process in order to ensure our model was accurate. Processing this data and thinking of unique solutions was definitely a large challenge we faced.
Accomplishments that we're proud of
Our proudest achievement during this whole project was being able to integrate Flask with React. We had trouble posting the user input to an API endpoint which we would then grab within Flask and perform the analysis with. Making sure that the user input passed smoothly into our backend and that the output of our algorithm was displayed properly for the user was the toughest challenge. It was only through a combined team effort were we able to successfully combine both technologies to create our final product. Our perseverance and success in integrating Flask and React, and overcoming this challenge was most definitely something all of us are proud of.
What we learned
On a technical level, we learned how to build robust web applications and interface between Flask and React using APIs. We also gained experience with NLP pipelining, and how to use them to do semantic searches. On a higher level, probably the most valuable thing we learned was git control. Everyone had to learn how to create pull requests and solve merge conflicts, which taught us how to delegate and manage tasks better.
What's next for (gened)ate
Although we accomplished a lot over the last 36 hours, we still have many ideas that we hope to implement in the future. We want to begin by expanding the number of GenEd classes we recommend from one to three so students have a greater variety in choice. We also want to increase the accuracy of our NLP model by incorporating student reviews from Reddit into our descriptions. These reviews will better represent a class's difficulty and student’s true experiences. Lastly, we hope to continue to improve our UI, by implementing better load times and a simpler layout.
Built With
- flask
- html
- javascript
- nextjs
- nlms
- pandas
- pypi
- python
- react
- tailwind
- typescript


Log in or sign up for Devpost to join the conversation.