-
-

home
-

how it works
-

genome link preview
-

storj


Inspiration
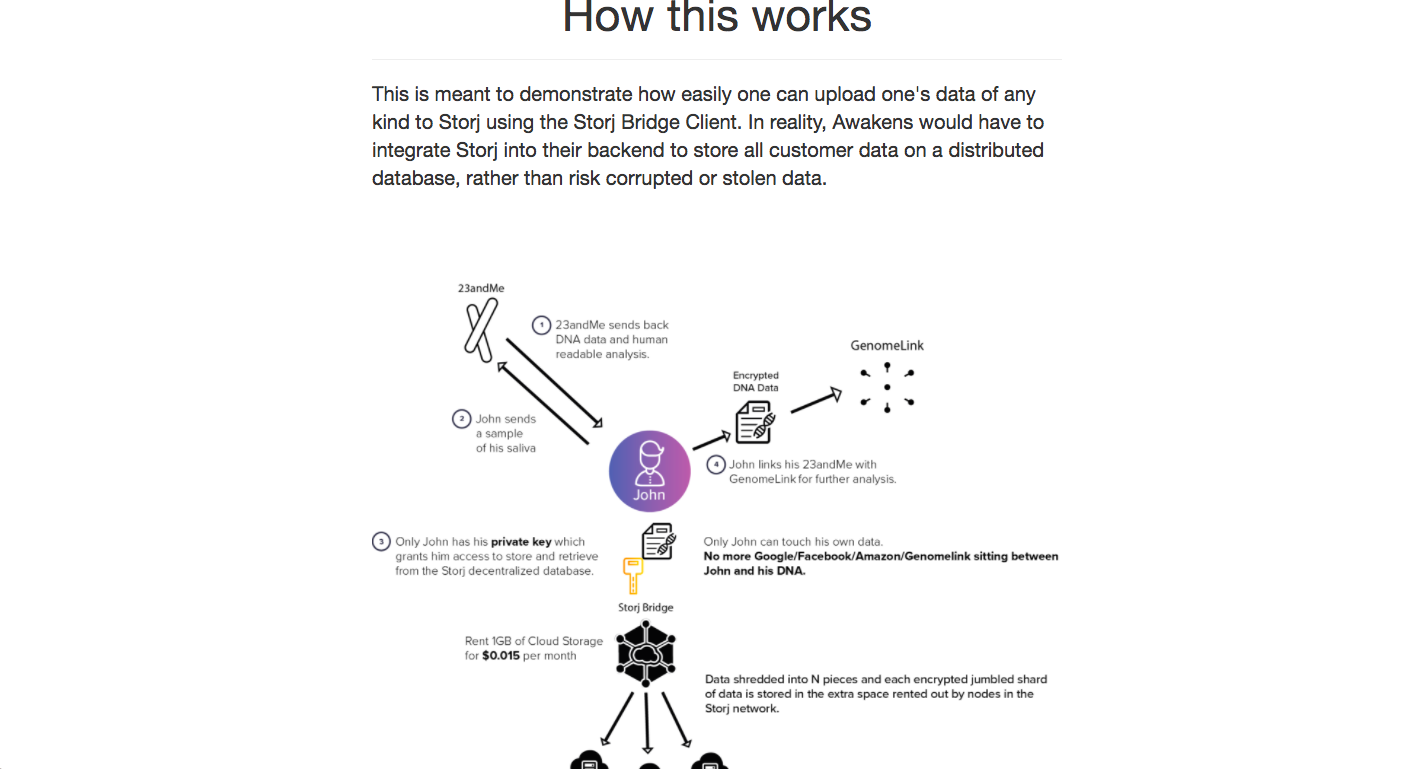
Storing entire genome is expensive. Could be cheaper. Also it would be pretty dystopian to think that there could be centralized companies in the future that hold everyone's genetic data and their human readable interpretation. Would be slightly less sketchy if this was stored in a distributed, tamper-proof manner.
What it does
Gets Genelink's interpretation of an individual user's data as a JSON file of reports of scores for various phenotypes. Then compresses, encrypts, and stores this human readable genetic data on a secure, distributed hash table of nodes running the Storj network.
How I built it
Using Node.js server to connect with Genomelink and Storj Bridge Client, and React.js with Wow.js/Bootstrap on the frontend. I made a simple little diagram on Illustrator to demonstrate the data flow. I also "over engineered" this on purpose after building it once with vanilla JS and jquery, just to get some practice with Babel, webpack, SSR, etc.
Also added Particle.js, the quintessential JS library for any project with "chain," "block," or "bit" in the name.
Challenges I ran into
Webpack, and also the Storj API is rapidly changing so I had to revert several versions back for a working app.
Accomplishments that I'm proud of
Used this as an opportunity to deep dive into webpack and various loaders.
What I learned
Server side rendering React.
What's next for GeneChain
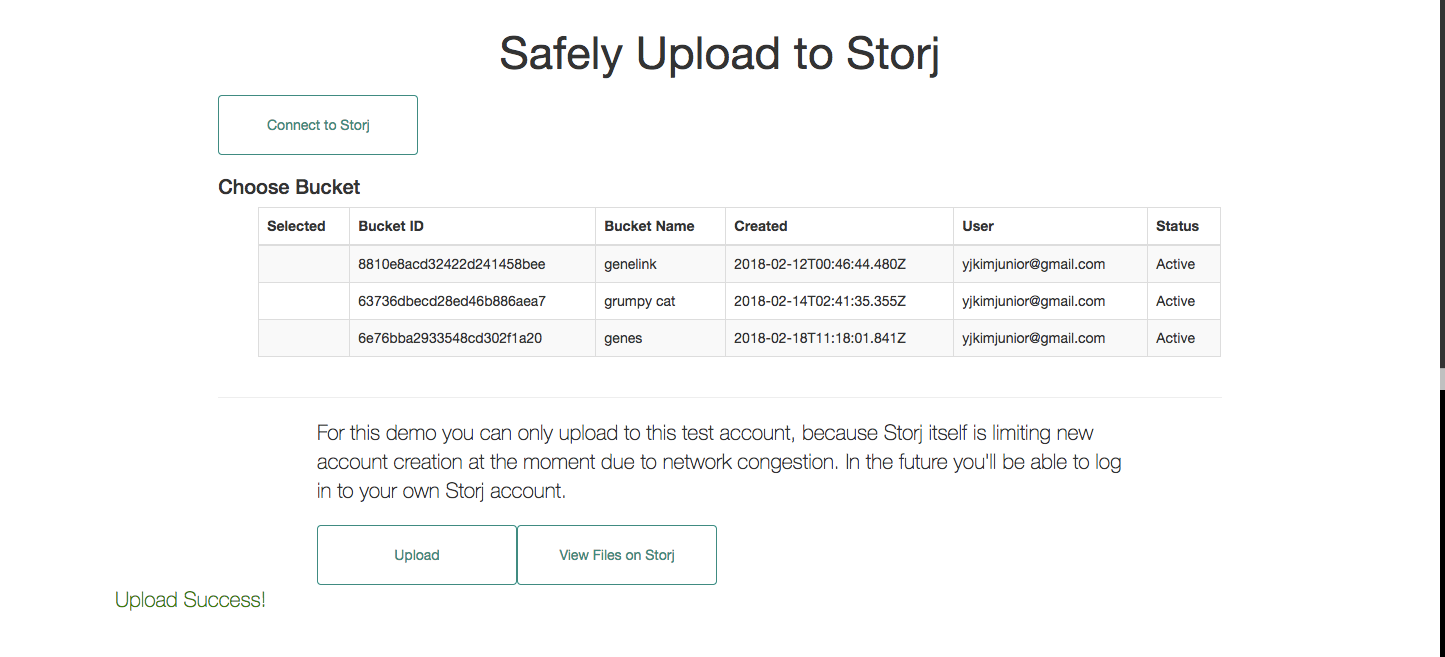
Because Storj itself has limited new account creation due to network congestion, this demo app only allows you to try uploading demo DNA data to a demo account.
In the future, for this to really accomplish the goal of self sovereign data storage, it would be necessary for companies like 23andMe and Awakens to integrate their backend with Storj/Sia.
Also needs integration with latest release of Storj Bridge Client.
Built With
- blockchain
- distributed-hashtable
- express.js
- node.js
- react
- storj

Log in or sign up for Devpost to join the conversation.