-
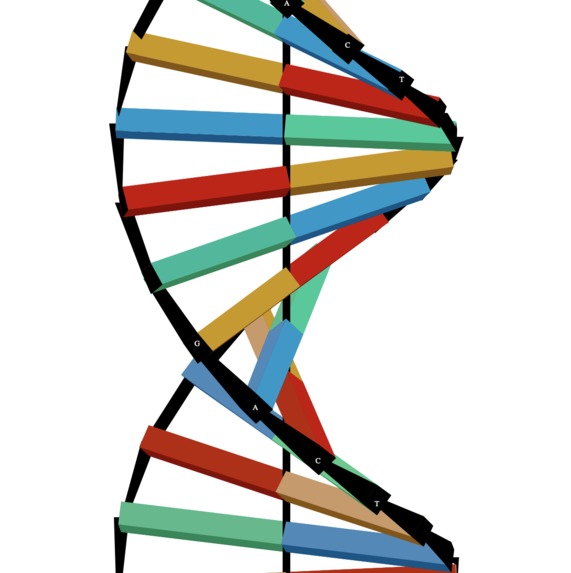
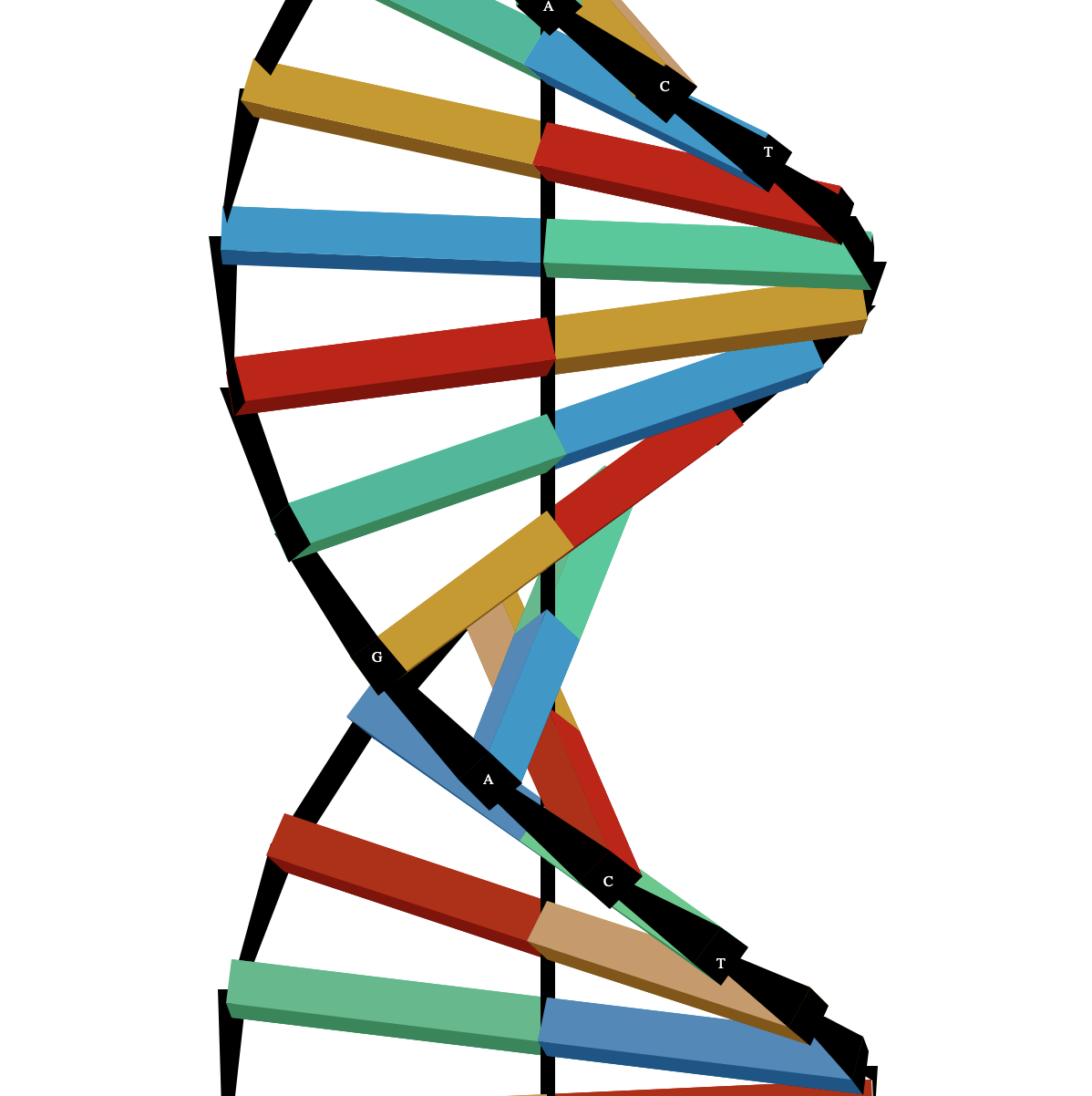
Rendering of a series of DNA base pairs
What it does
Our project is an educational tool that allows users to enter a search query for a gene in a species of their choice. Searches the NCBI Gene database to obtain the sequence of said gene and renders a color-coded 3D model of the gene's base sequence. It also allows the user to explore hypothetical splicing of various genes.
How we built it
The gene sequences were webscraped from NCBI Gene and NCBI Nucleotide public databases using Requests, Beautiful Soup, LXML, and the NCBI Entrez programming utilities API. The UI was built in Python using the cmu_112_graphcis framework built by Carnegie Mellon University. The 3D rendering of the genes was done via camera projection matrices. The splash screen was made with Perlin noise.
Challenges we ran into
There was significant difficulty in figuring out how to interface with the API to obtain the correct sequences and information about them. For some of the genes, the DNA sequences we were looking for were listed as mutations of other famous genes, so finding the different sequence was also difficult. Also, near the beginning, we spent a while discussing how to best avoid an ethical dilemma from the ramifications of gamification of the gene-splicing aspect.
Accomplishments that we're proud of
We are most proud of our query engine's ability to somewhat reliably scrape arbitrary genomes based on user input, as well as our UI's ability to neatly visualize the base pairs.
What we learned
We learned a great deal about interdisciplinary collaboration due to the aspects of webscraping, genetics, 3D graphics, interfacing with APIs, and user interactivity. In the process we gained further appreciation of each other's unique skills as we divided up the work.

Log in or sign up for Devpost to join the conversation.