-
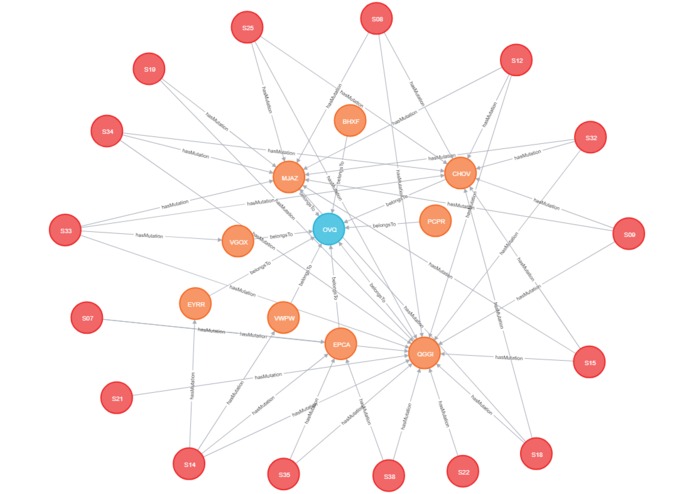
1_Gene_Subgraph
-
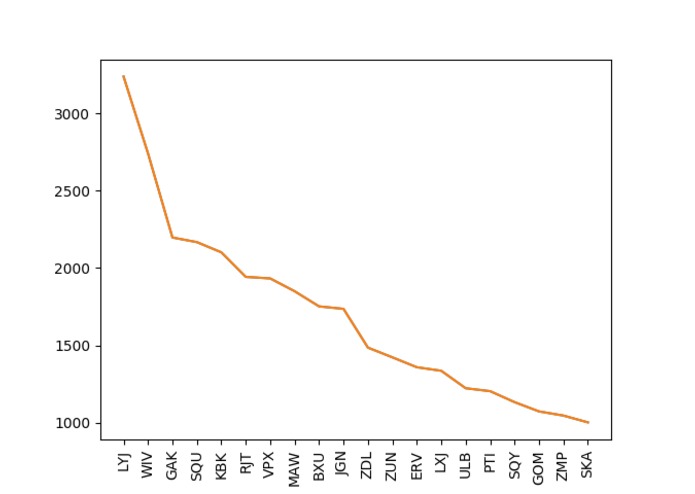
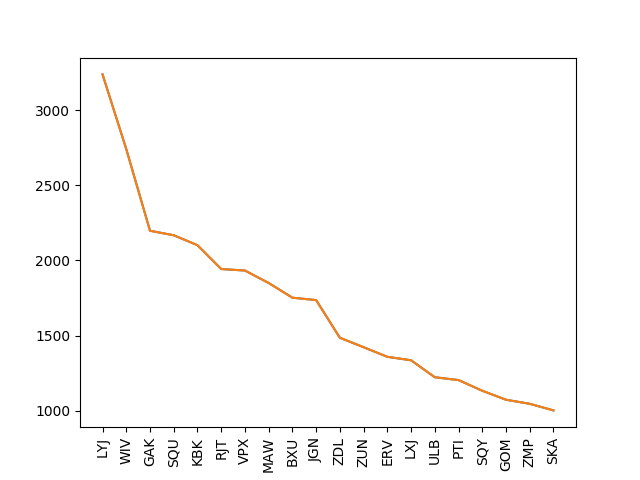
MostFrequentGeneMutation
-
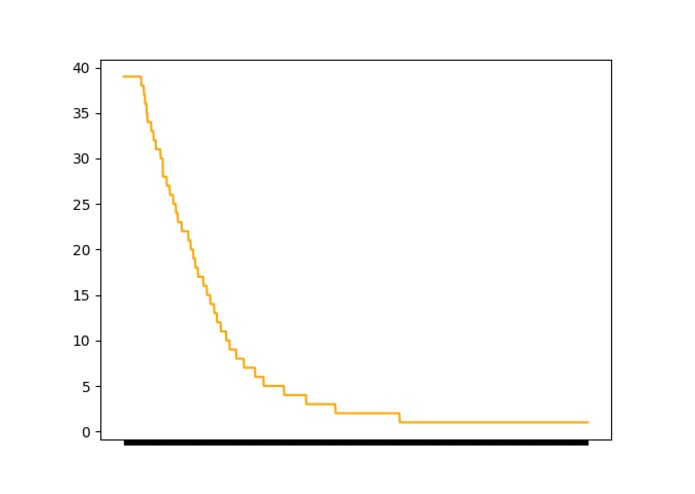
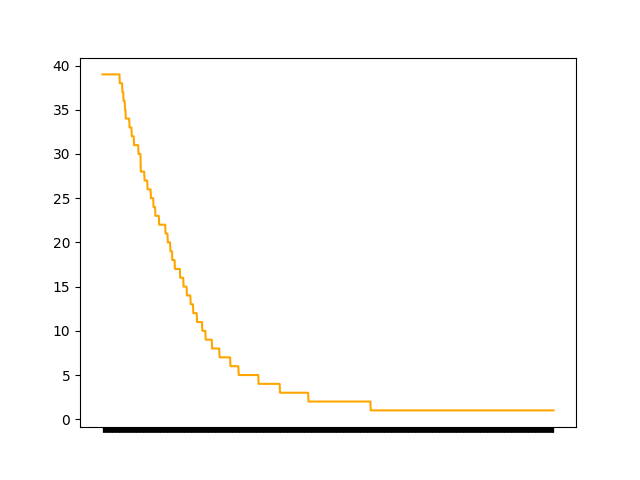
RareMutationDistribution
Inspiration
Everyone knows someone that has been affected by some sort of disease. In most of the cases, that's something stressful but not life-threatening, as a cure is known. That's not the case for rare diseases, though, as the root of their origin is not truly understood and, therefore, developing a cure is hard. We've seen the opportunity of helping by using software tools to try to identify relationships between gene mutations and Hemophilia.
What it does
We try to identify common features among all the affected by the disease in order to try to conclude which possible mutations may lead to disease.
How we built it
We've used Python to visualize the data and Neo4j to compute similarity measures between the mutations. Several centralities algorithms were used in order to study which are the more important mutations. (1_Gene_Subgraph.png)
Challenges we ran into
It has been challenging to use gene data, as it is very different from the usual R^d data used in most of the cases. Also, the dataset is quite big, and importing it and use the generated graph takes a while. Due to this computational costs, we could only use 113.000 genes and 705.000 relationships between them
What we learned
We've learned how hard is to identify common mutations among people that have a common disease, and how problematic is the fact that many mutations take place in our lifetime, which makes hard to understand if they are directly correlated to the disease or not.
What's next for Gene mutation and its relation to Acquired Haemophilia A
A more thorough study of the provided dataset would be needed to further understand the correlation between gene mutations and the disease.



Log in or sign up for Devpost to join the conversation.