-
-
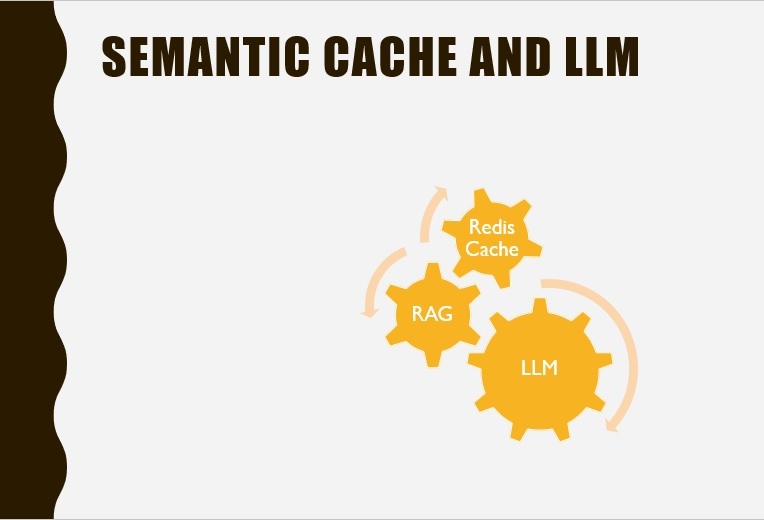
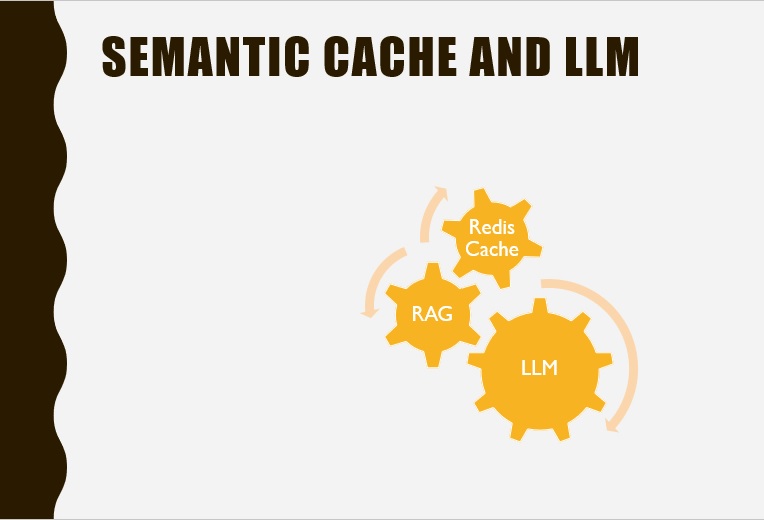
LLM context affinity with Semantic Cache to reduce cost and increase efficiency
Inspiration
Need for consistent and relevant prompt responses reducing cost and increasing efficiency. We achieve same by building affinity of LLM models to context and relevance with the help of vector db.
What it does
Using corpus of past responses, policies and facts, it streamlines responses in conjunction with LLM of your choice and bringing context and relevance in every step.
How we built it
Pipeline of vector db like Redis, embedding query, RAG and LLM engine.
Challenges we ran into
Seeding vector db with known facts, policies and rules.
Making sure responses met our goals and LLM was kept up-to-date.
Which vectordb to pick up?
Accomplishments that we're proud of
Potential use cases in real world e.g Healthcare, Order Processing, Customer Support, Project Management etc.
What we learned
Combination of vector db and LLM is too powerful. We do not have to use tokens for every prompt. Cost can be optimized. Operational efficiency can be enhanced for generic LLM applications.
What's next for GenAI with semantic affinity cache
More corpus data, more use cases, more tuning and adoption of generic LLM to reduce cost while increasing quality of responses at speed.
Built With
- javascript
- llm
- vectordb

Log in or sign up for Devpost to join the conversation.