-
-
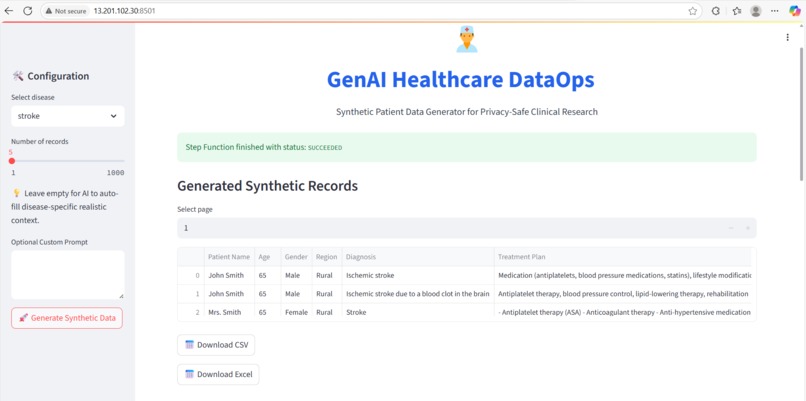
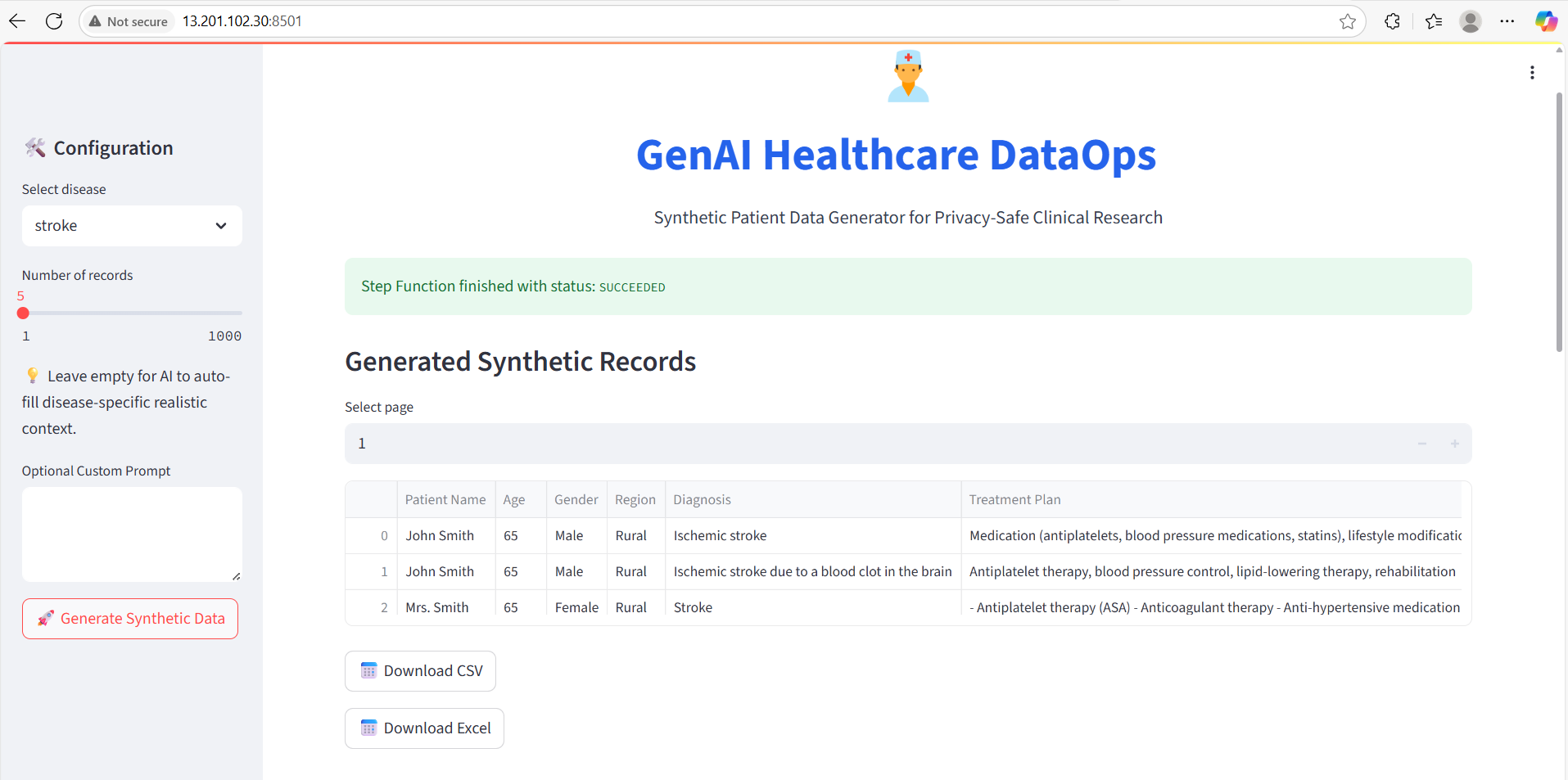
Streamlit UI
-
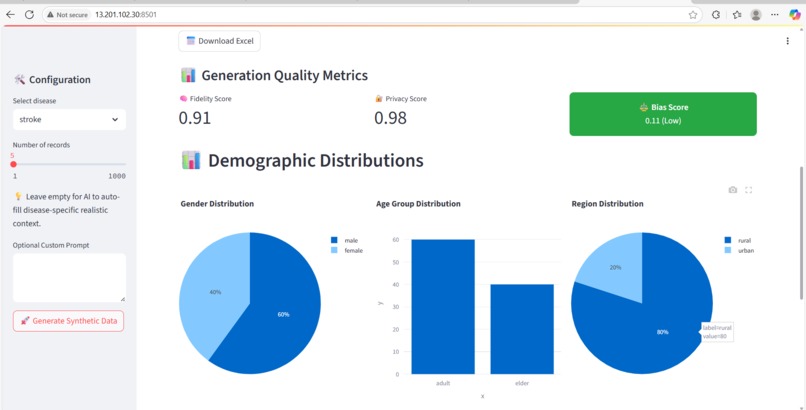
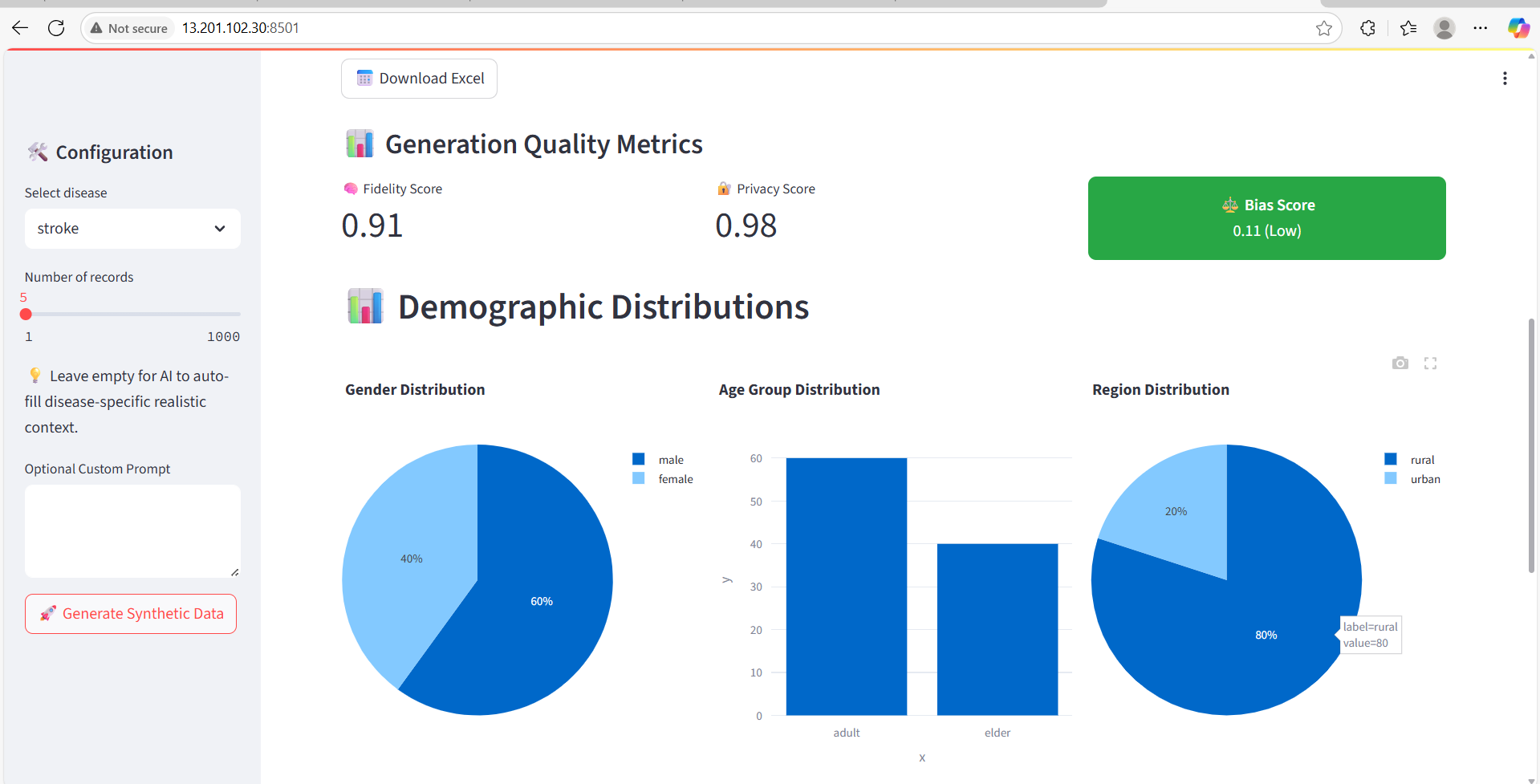
Charts and Metrics
-
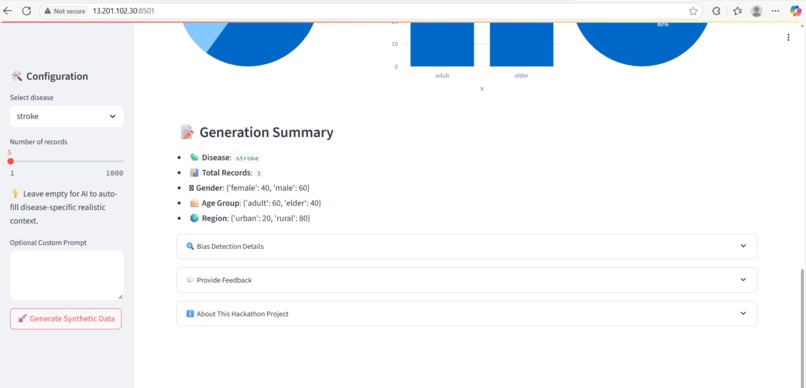
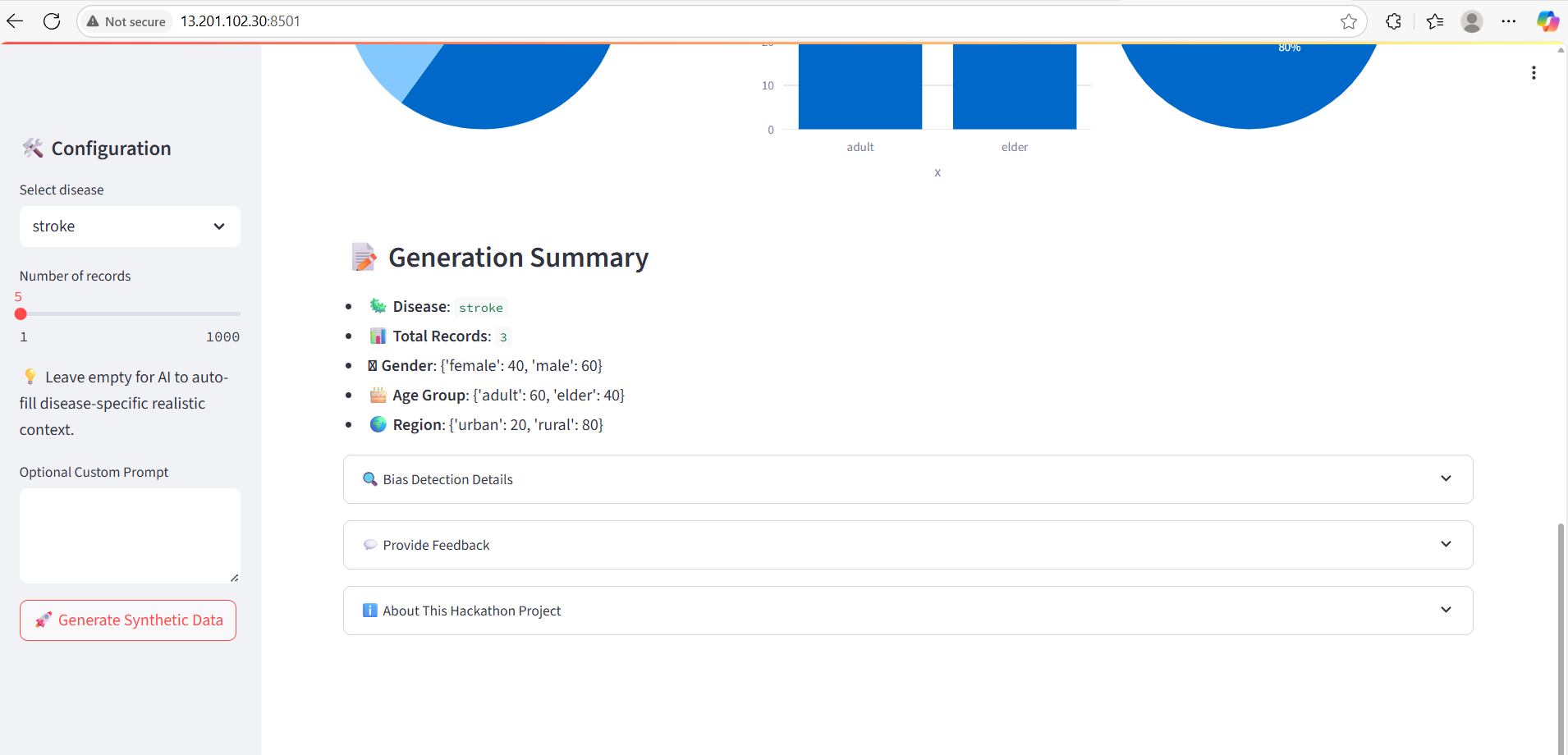
Generated data Summary
-
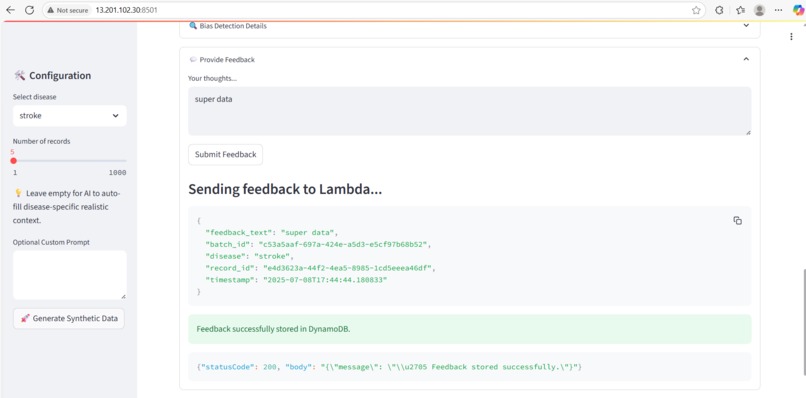
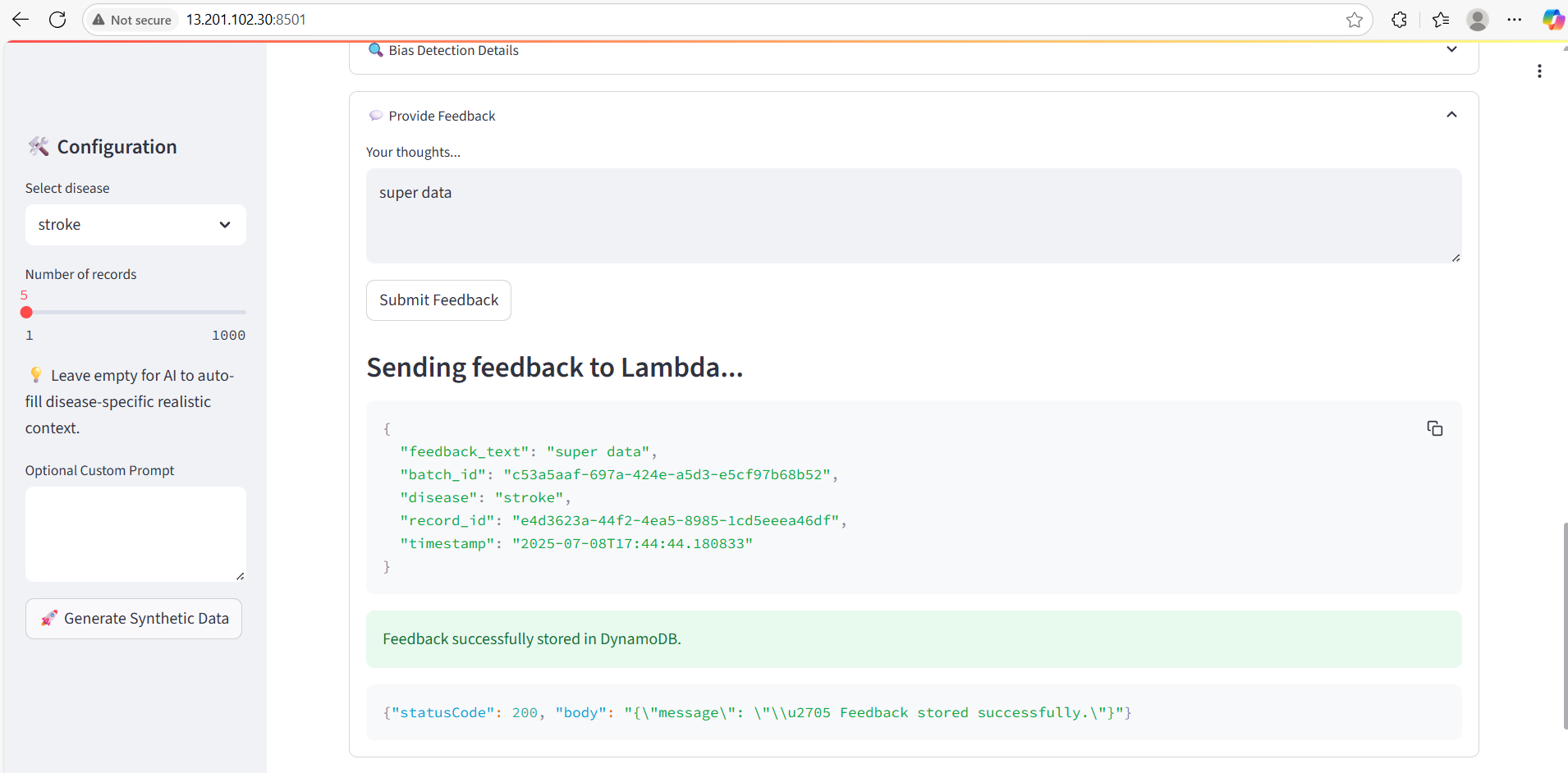
Feedback UI
-
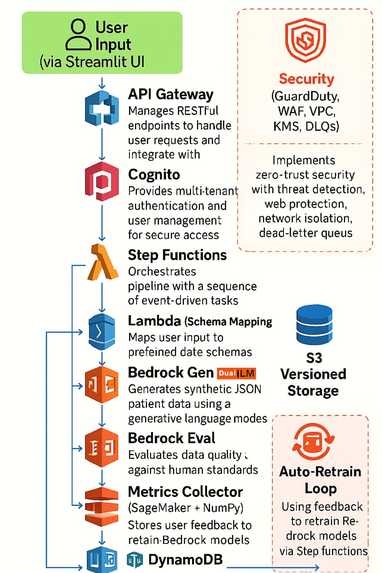
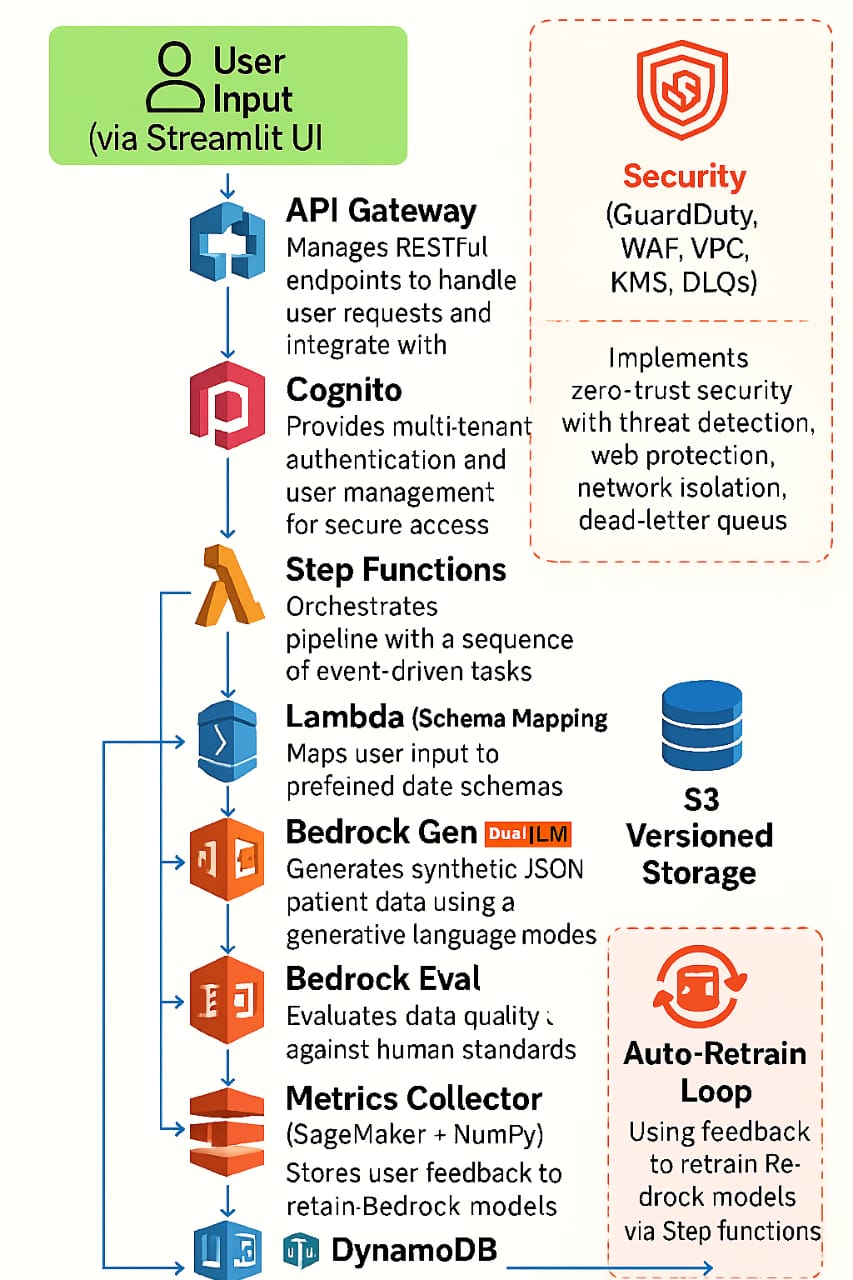
Architecture Diagram
Inspiration
In real-world healthcare AI, access to high-quality, diverse, and privacy-safe patient data is a huge bottleneck. Clinical researchers often lack realistic datasets for training or validating AI models — especially when dealing with rare diseases or strict data regulations like HIPAA.
I was inspired to solve this critical problem by building an end-to-end GenAI DataOps platform using the AWS ecosystem. Our goal: enable hospitals and AI labs to prototype, test, and retrain models without ever using real patient data.
🛠️ How I Built It
I used Amazon Bedrock (Titan) to generate synthetic patient records — structured with disease, age, gender, region, and treatment plans.
A full Step Functions pipeline orchestrates:
Schema mapping (age/gender/region realism)
Bedrock generation
Lambda evaluation of bias, fidelity, privacy
Streamlit powers the UI with charts, metrics, download support, and feedback submission.
Feedback is stored in DynamoDB, preparing for future fine-tuning workflows.
I built everything using serverless AWS services with secure IAM role delegation.
⚔️ Challenges I Faced
🌐 Handling Bedrock throttling for larger record batches — I built a retry mechanism to ensure success and set a sweet spot for demo scale (18–20 records).
🔐 Understanding and integrating IAM, Cognito, Lambda roles as first-time AWS developers.
🧪 Debugging Lambda payloads across the Step Function state transitions (stringified vs. JSON).
💬 Making the feedback-to-retrain loop meaningful and properly stored in DynamoDB.
💡 What I Learned
Working with serverless cloud orchestration at scale: Step Functions + Bedrock + Lambda is powerful when combined.
The importance of prompt engineering in medical text generation.
Designing for bias detection and demographic realism in GenAI workflows.
Using realistic distributions (CDC/WHO) made a huge difference in data quality and evaluation.
Built With
- amazon-cloudwatch
- amazon-cognito
- amazon-dynamodb
- amazon-web-services
- amazonbedrock
- amazonstepfunction
- eventbridge
- iam
- python
- s3
- streamlit

Log in or sign up for Devpost to join the conversation.