-
-
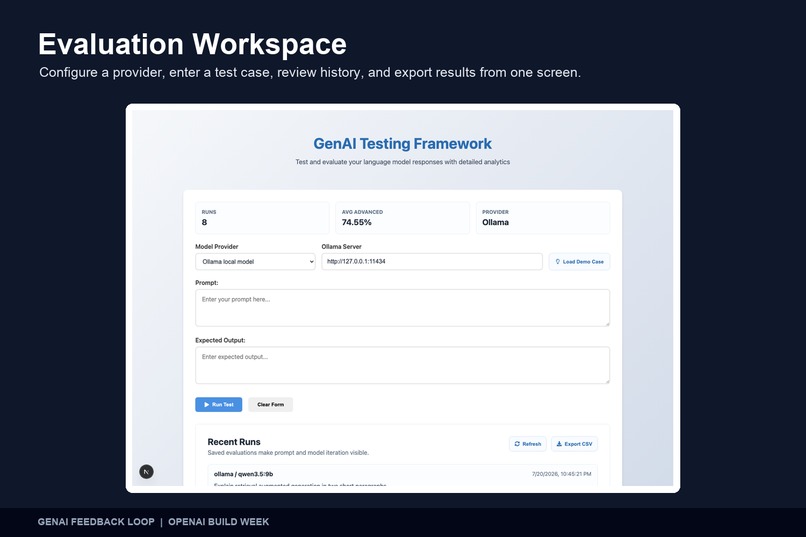
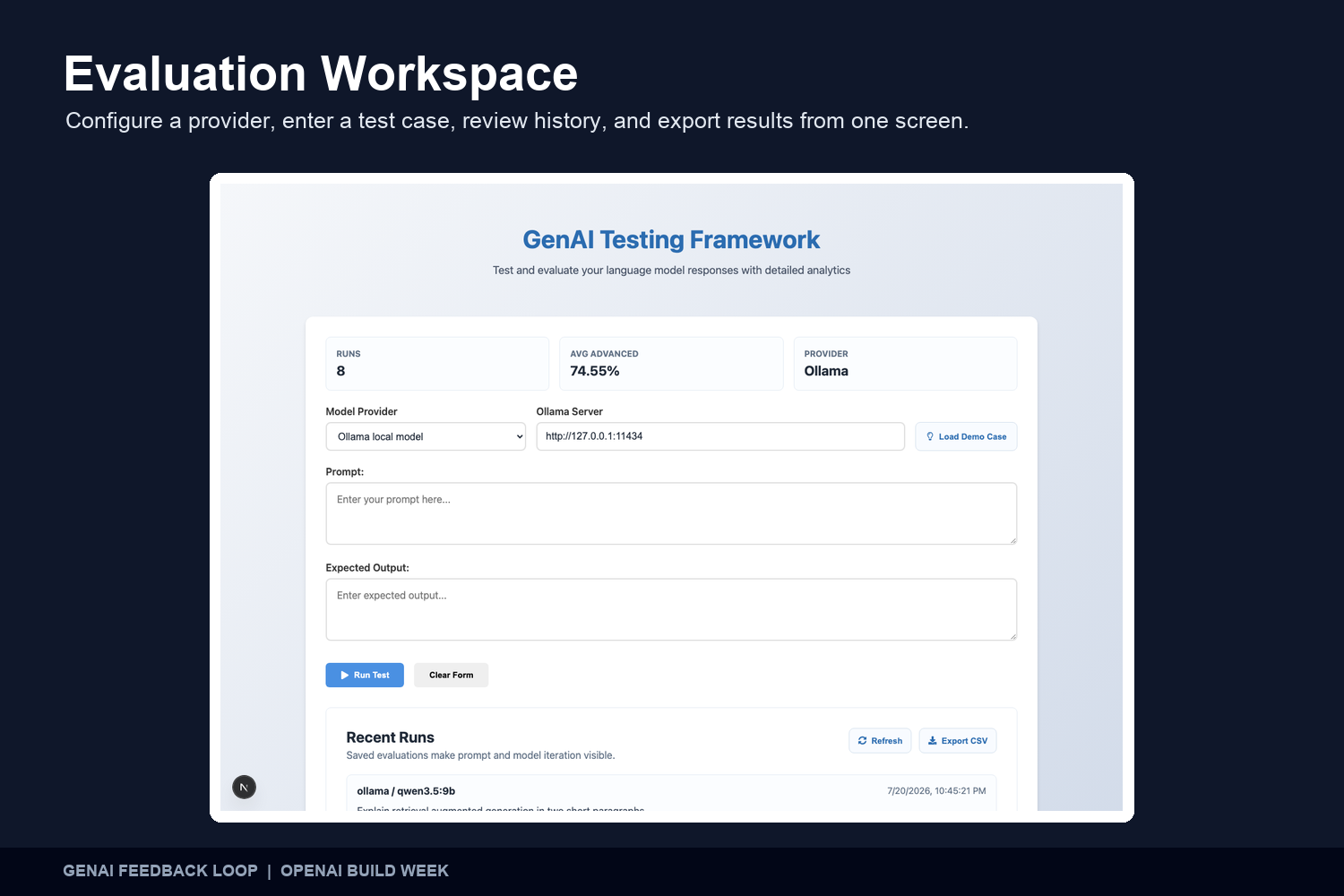
Evaluation Workspace Configure a model, enter a test case, review recent runs, and export evaluation results from one workspace.
-
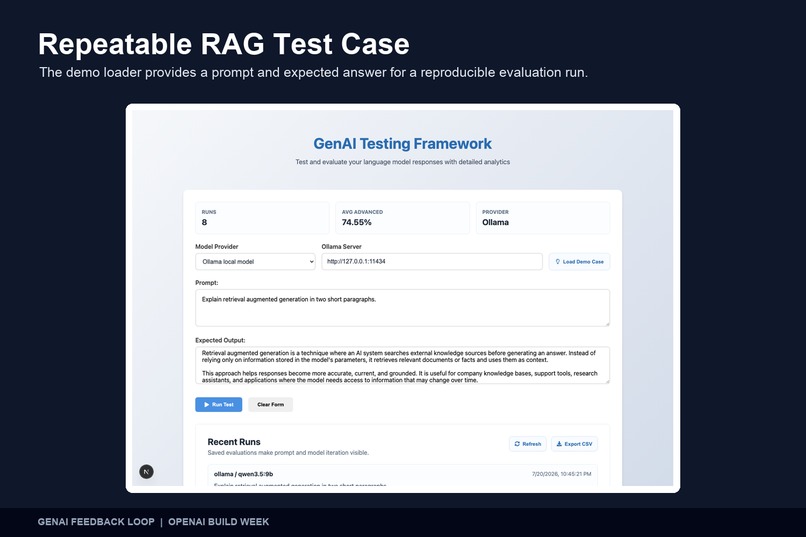
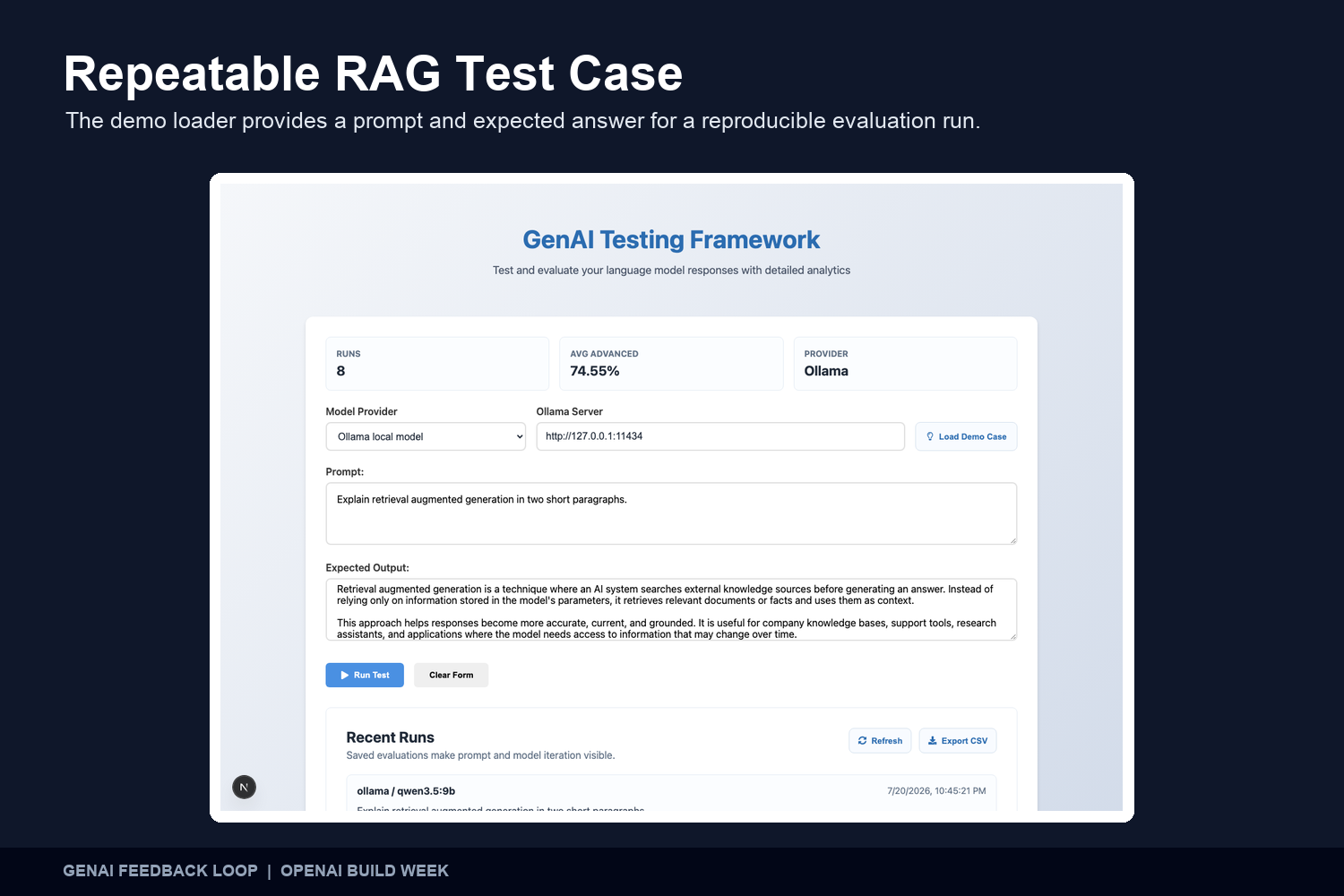
Repeatable RAG Test Case The demo loader provides a RAG prompt and reference answer for fast, repeatable evaluation runs.
-
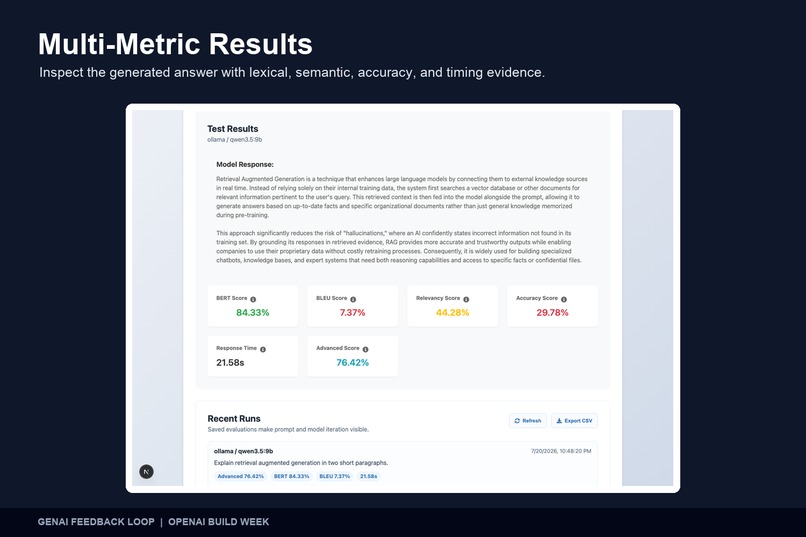
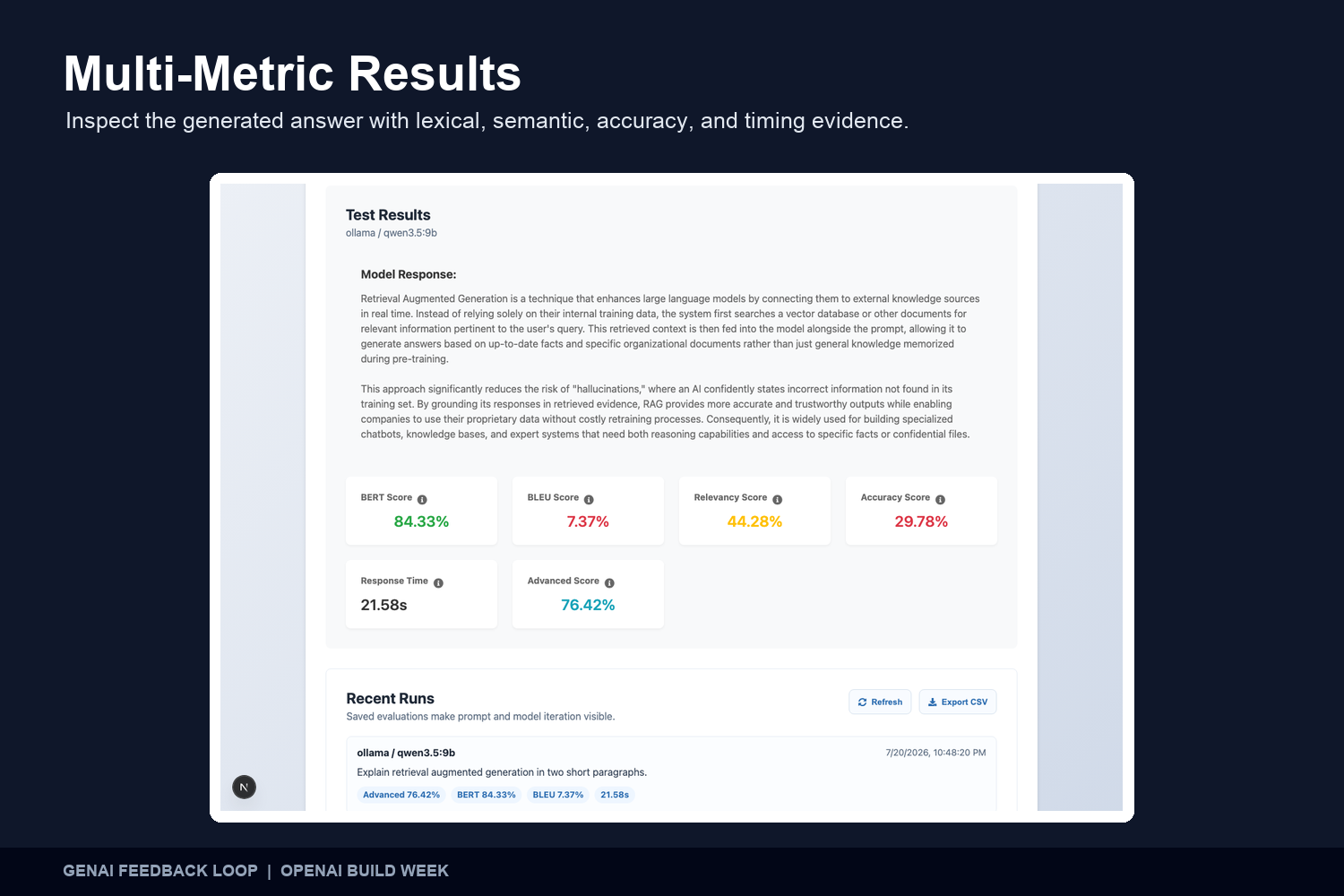
Multi-Metric Results Review each response with BERTScore, BLEU, relevancy, accuracy, semantic similarity, and timing evidence.
-

From Prompt to Evidence Run prompts through local Ollama or GPT-5.6, evaluate them in Flask, then save, review, and export the results.
-

Codex-Accelerated Wf Codex accelerated analysis, implementation, testing, and submission work while we retained the key product decisions


Inspiration
Generative AI applications are easy to prototype, but much harder to evaluate with confidence. A model response may sound convincing while still missing important facts, instructions, or expected behavior. Manually reviewing every response is slow, subjective, and difficult to reproduce.
We created GenAI Feedback Loop to give developers a more systematic way to test prompts and model outputs. Instead of relying on intuition or a single score, the application compares a generated response with an expected answer and presents several complementary evaluation signals.
Our goal was to make AI evaluation practical: simple enough to run locally, transparent enough to understand, and flexible enough to compare both local and hosted models.
What It Does
GenAI Feedback Loop provides a single workflow for running and reviewing LLM evaluations.
A developer enters a prompt and an expected response, selects a model provider, and runs the test. The application generates a response, measures it against the reference answer, stores the result, and displays the response alongside its evaluation metrics.
The application supports:
- Local models through Ollama
- GPT-5.6 through the OpenAI Responses API
- Configurable Ollama server settings
- Request-scoped OpenAI API keys that are not stored in evaluation history
- Recent evaluation history
- CSV export for offline analysis
- A built-in demonstration case for repeatable testing
The evaluation pipeline combines several signals:
- TF-IDF relevancy: Measures lexical relevance using term weighting and cosine similarity.
- Edit-distance accuracy: Measures how closely the generated text matches the reference at the character and word level.
- BLEU: Evaluates overlapping words and phrases between the generated and expected responses.
- BERTScore: Measures contextual semantic similarity using transformer embeddings.
- Sentence-transformer similarity: Provides an additional sentence-level semantic comparison.
- Response timing: Records total response time and model processing time.
No individual metric provides a complete definition of quality. Together, these measurements help developers identify whether a response is lexically similar, semantically aligned, efficient, or drifting away from the expected behavior.
How We Built It
The frontend is built with Next.js and React, providing a responsive interface for entering test cases, selecting a model provider, reviewing results, loading demo data, and exporting evaluation history.
The backend uses Flask and SQLAlchemy. It handles model requests, calculates evaluation metrics, validates failures, stores successful results, and exposes the history API.
We use SQLite as the default database so the application can run without additional database setup. MySQL remains supported through the configurable DATABASE_URL setting.
For model inference, the application supports two paths:
- Ollama provides a private, local-first workflow using models such as Llama 3.2.
- The OpenAI Responses API makes GPT-5.6 available as an optional hosted model.
The evaluation layer uses scikit-learn, NLTK, BERTScore, sentence-transformers, and edit-distance techniques.
How Codex Accelerated Our Workflow
Codex was our engineering collaborator throughout OpenAI Build Week. We used one primary Codex thread from the initial repository audit through implementation, debugging, verification, documentation, and demo production.
Codex helped us:
- Trace the complete Next.js, Flask, database, and model request flow
- Replace hardcoded settings with environment-based configuration
- Introduce a configurable provider layer for Ollama and the OpenAI Responses API
- Make SQLite the default while retaining optional MySQL support
- Add evaluation history, CSV export, and a built-in demo case
- Improve model-call error handling so failed requests are not saved as scored results
- Upgrade dependencies and resolve frontend audit findings
- Run backend checks, production builds, and end-to-end evaluations
- Prepare the README, submission narrative, and narrated demonstration
This compressed several normally separate architecture, implementation, testing, and documentation passes into one continuous and reviewable workflow.
Codex accelerated execution, but we made and approved the key decisions:
- Product: Use several evaluation signals instead of presenting one score as ground truth.
- Engineering: Preserve a local-first Ollama workflow while adding GPT-5.6 as an optional provider.
- Setup: Use SQLite by default for reproducibility while retaining MySQL support.
- Security: Keep interface-provided API keys request-scoped and out of stored history.
- Design: Keep test input, execution, results, history, and export within one scan-friendly workflow.
Challenges We Ran Into
One challenge was balancing evaluation depth with local performance. BERTScore and sentence-transformer models provide useful semantic measurements, but they introduce larger dependencies and first-run model downloads.
Another challenge was interpreting multiple metrics responsibly. Lexical overlap may be low even when two answers have similar meanings, while semantic similarity can be high despite missing an important detail. We therefore designed the results as a collection of evidence rather than a single pass-or-fail score.
The original project also assumed a specific MySQL installation and hardcoded local services. Making the application reproducible required separating configuration from source code, introducing SQLite defaults, and preserving compatibility with the existing database option.
Model-provider failures created another important challenge. A failed request should not be treated as a poor-quality model response, so the backend now returns clear errors instead of storing misleading evaluation results.
Accomplishments That We're Proud Of
- Combined lexical, structural, semantic, and performance measurements in one evaluation workflow
- Added both local Ollama models and GPT-5.6 without sacrificing the local-first experience
- Reduced setup friction with SQLite and example environment files
- Added persistent history and CSV export for repeated testing
- Kept OpenAI API keys out of stored evaluation records
- Produced a reproducible demo flow and validated the application end to end
- Used Codex across the complete development lifecycle while retaining clear human ownership of product decisions
What We Learned
We learned that evaluating generative AI requires multiple perspectives. A response can be semantically correct without closely matching the reference wording, or it can repeat the expected vocabulary while missing the intended meaning.
We also learned that evaluation results are most useful when they support investigation rather than pretend to provide an absolute judgment. Developers need to see the generated answer together with the metrics and understand why the signals may disagree.
Finally, we learned how effectively Codex can connect repository analysis, implementation, debugging, testing, and documentation. Its greatest impact was not generating isolated code snippets, but maintaining context across the complete workflow and helping us reach a tested result faster.
What's Next for GenAI Feedback Loop
Our next priorities are:
- Batch evaluation for prompt and test suites
- Side-by-side comparison across local and hosted models
- Saved evaluation suites with reusable acceptance thresholds
- Additional metrics such as ROUGE and configurable model-based grading
- Better visualizations for historical performance
- Automated reports for sharing evaluation results
- Team workspaces and collaborative review
- Continuous evaluation integration for application development pipelines
The long-term goal is to turn GenAI Feedback Loop into a practical testing environment where teams can measure changes, compare models, and improve AI behavior with evidence rather than intuition.
Built With
- ai-evaluation
- bertscore
- codex
- flask
- generative-ai
- gpt-5.6
- hugging-face
- llm
- natural-language-processing
- next.js
- openai
- python
- rag
- react
- sqlite


Log in or sign up for Devpost to join the conversation.