-
-
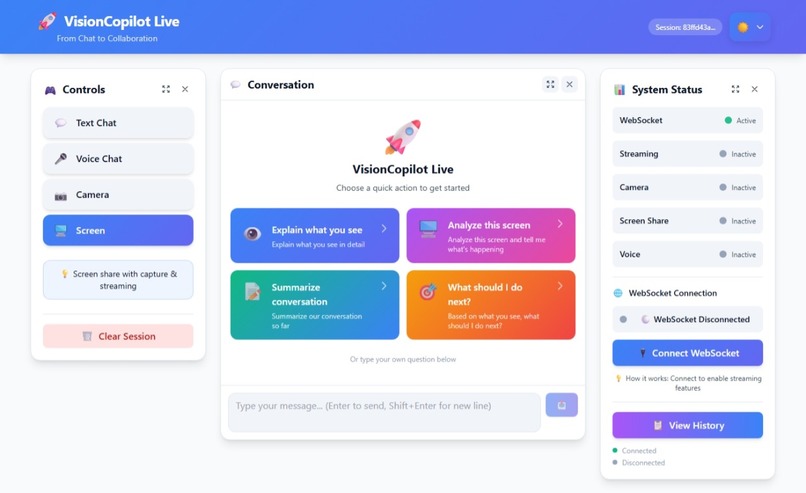
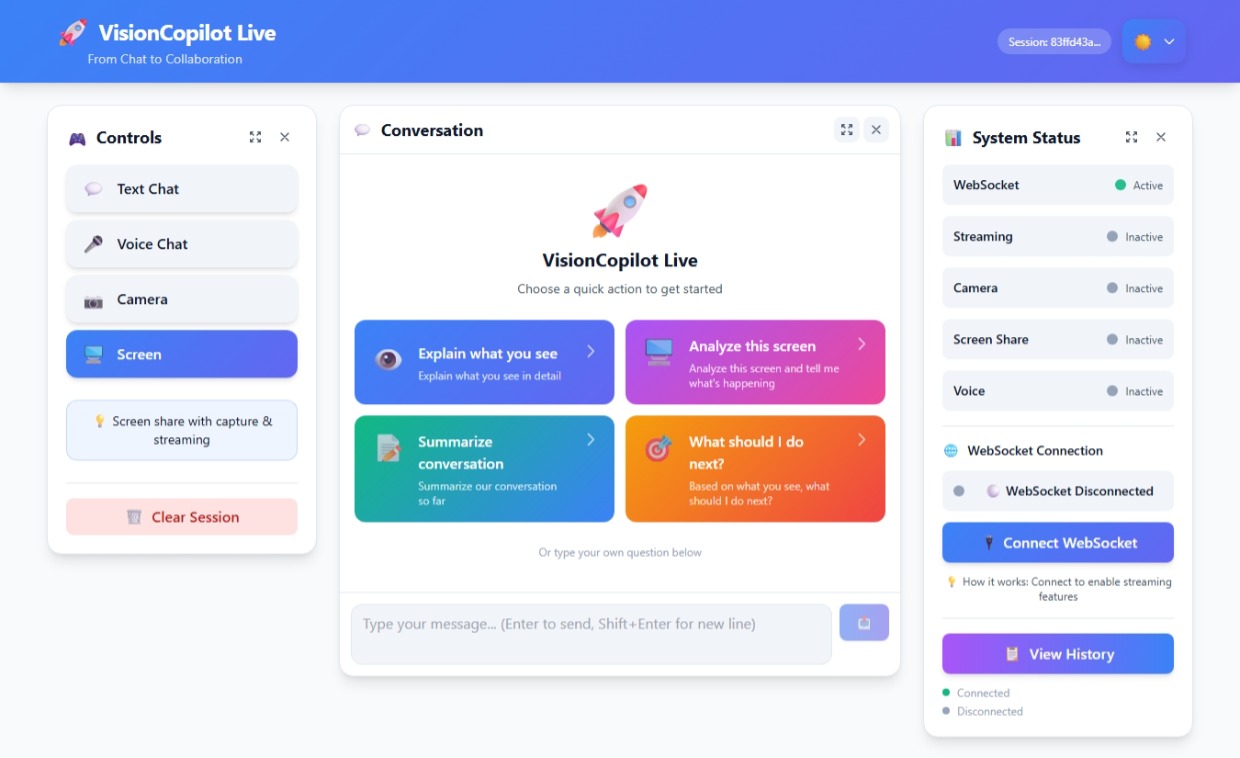
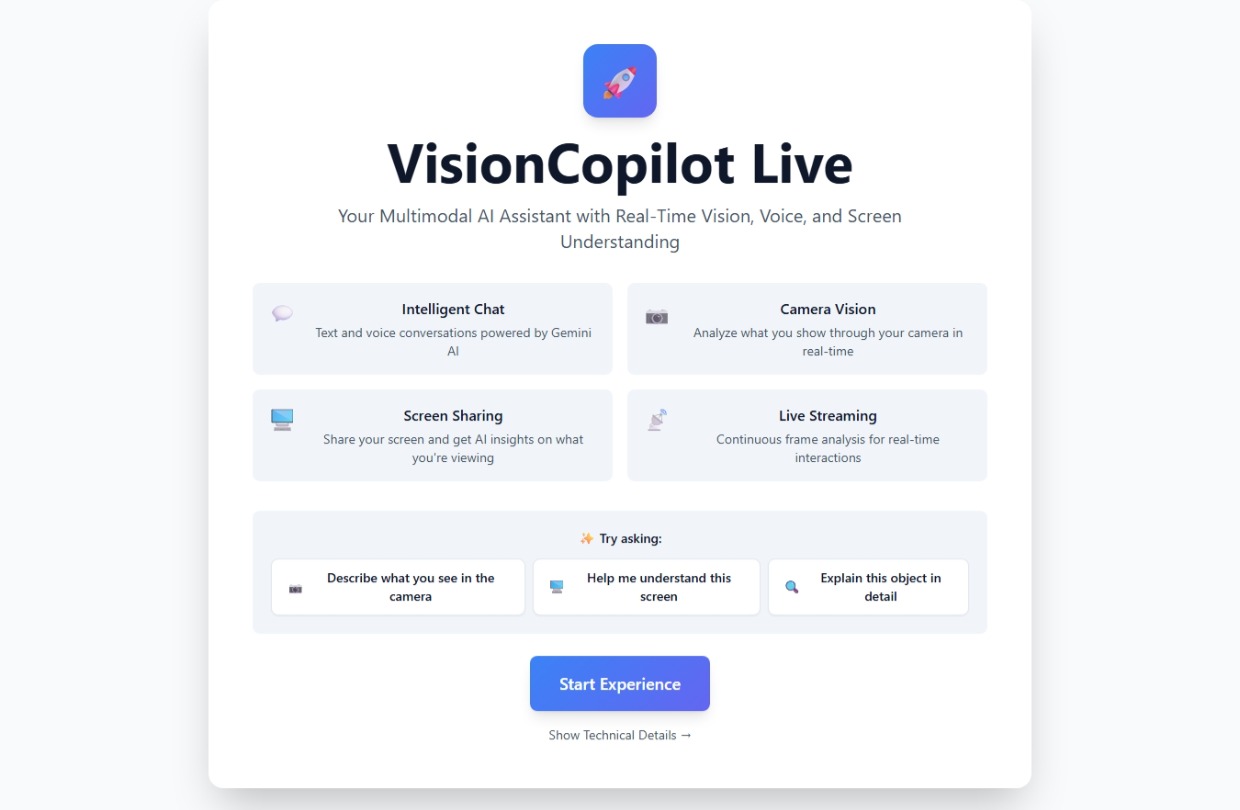
VisionCopilot Dashboard
-
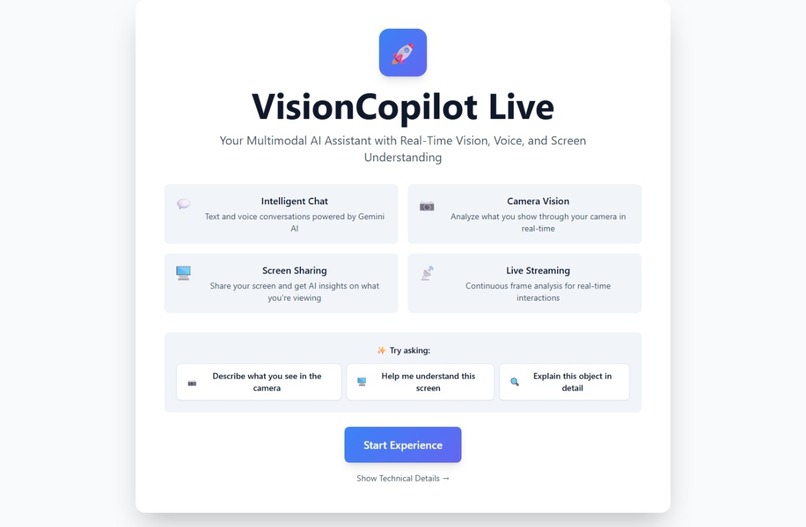
VisionCopilot
-
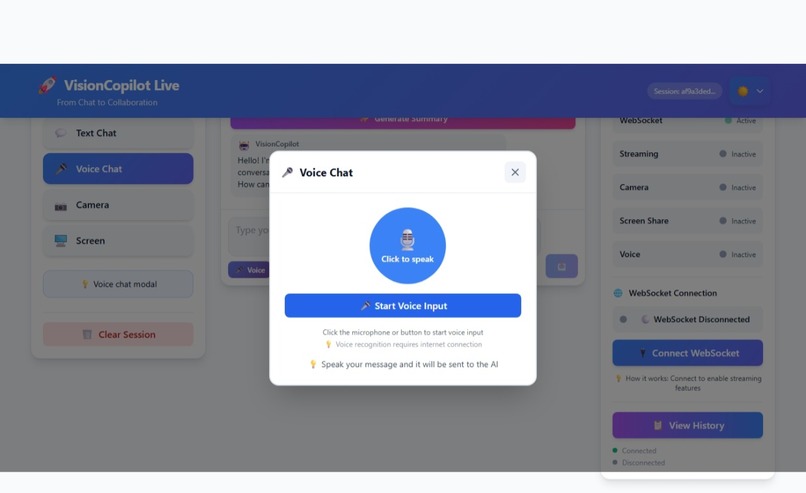
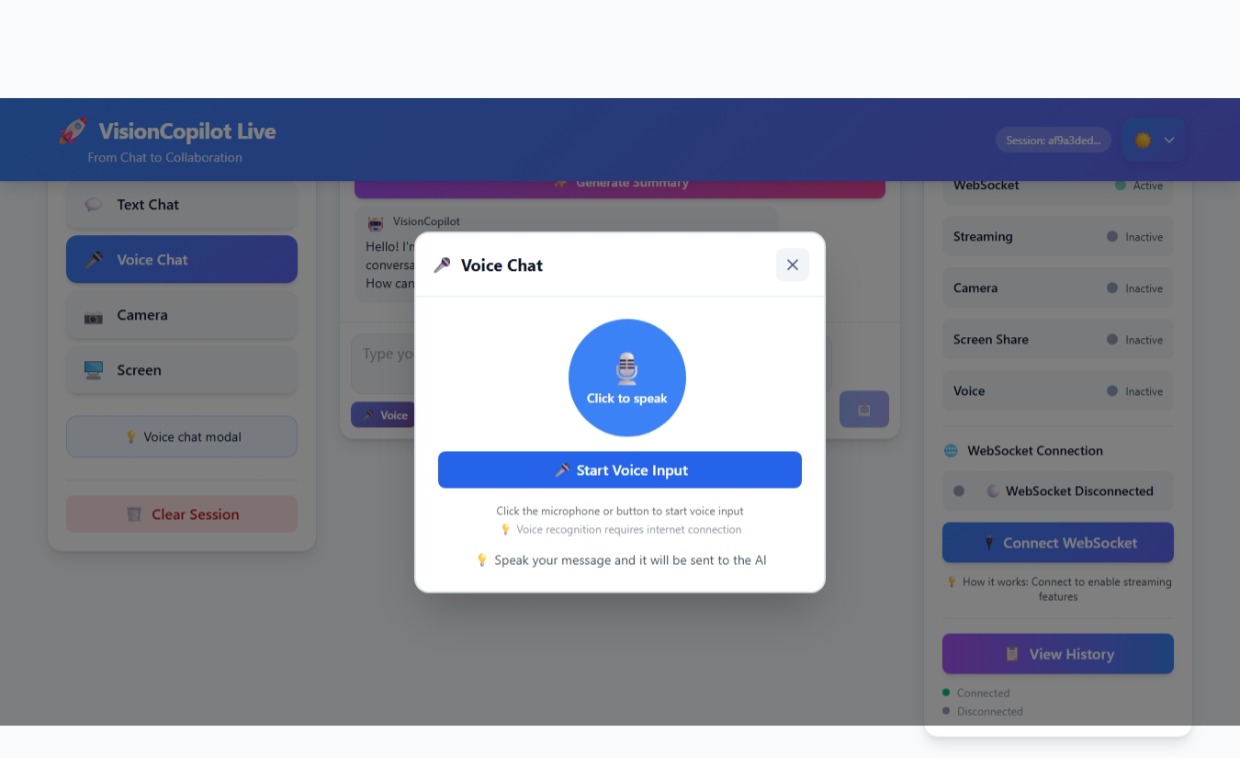
VisionCopilot Voice
-
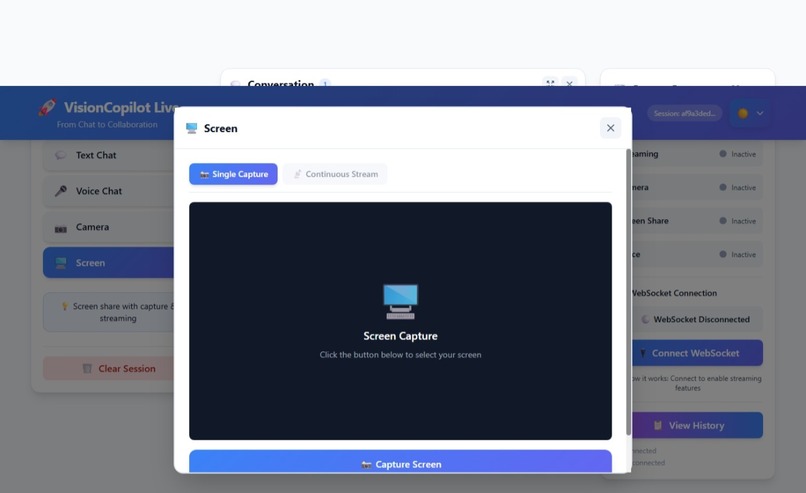
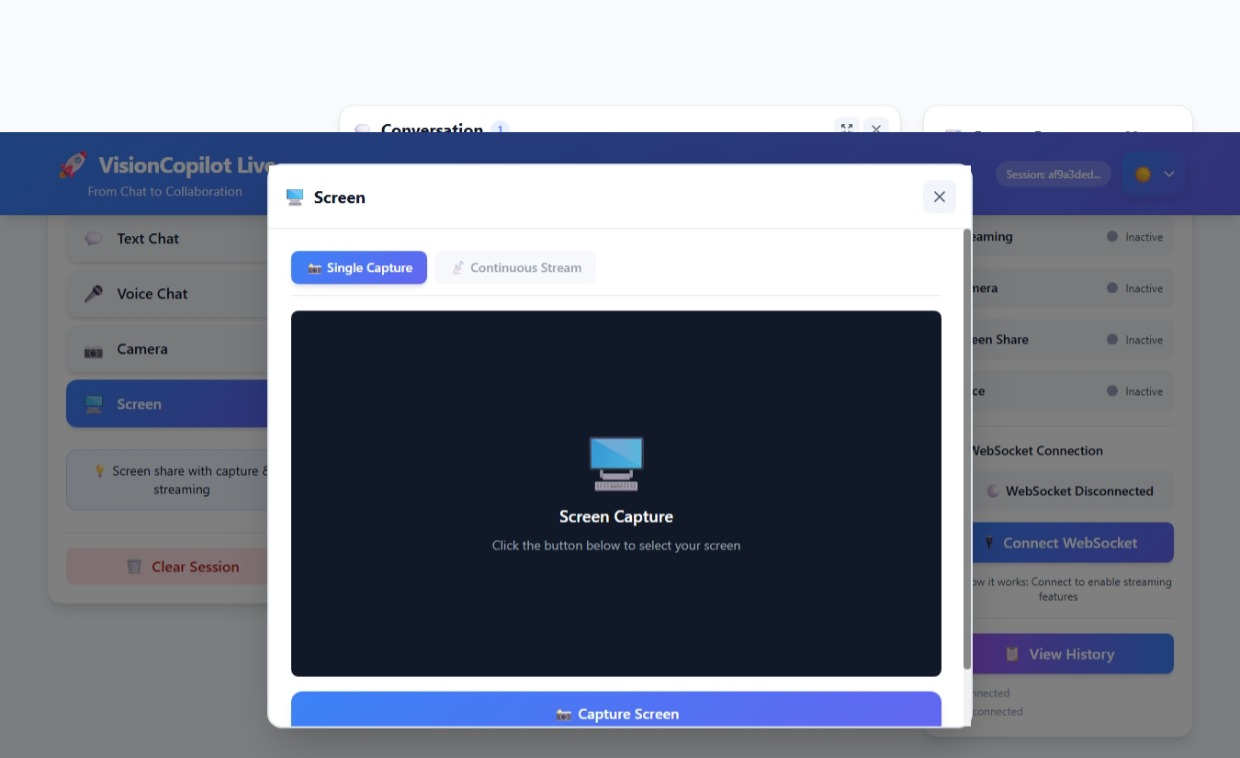
VisionCopilot Screen
-
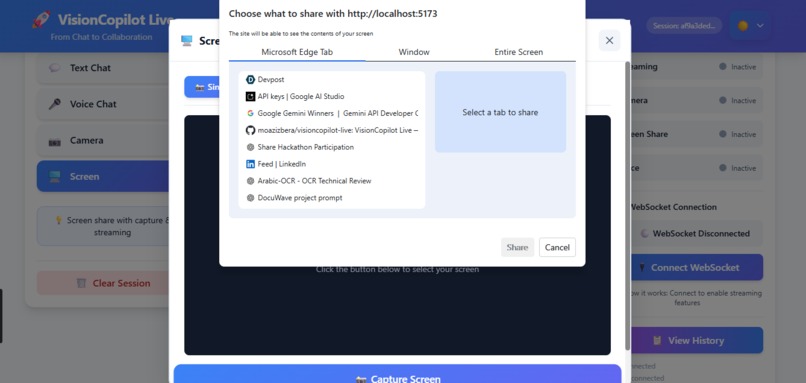
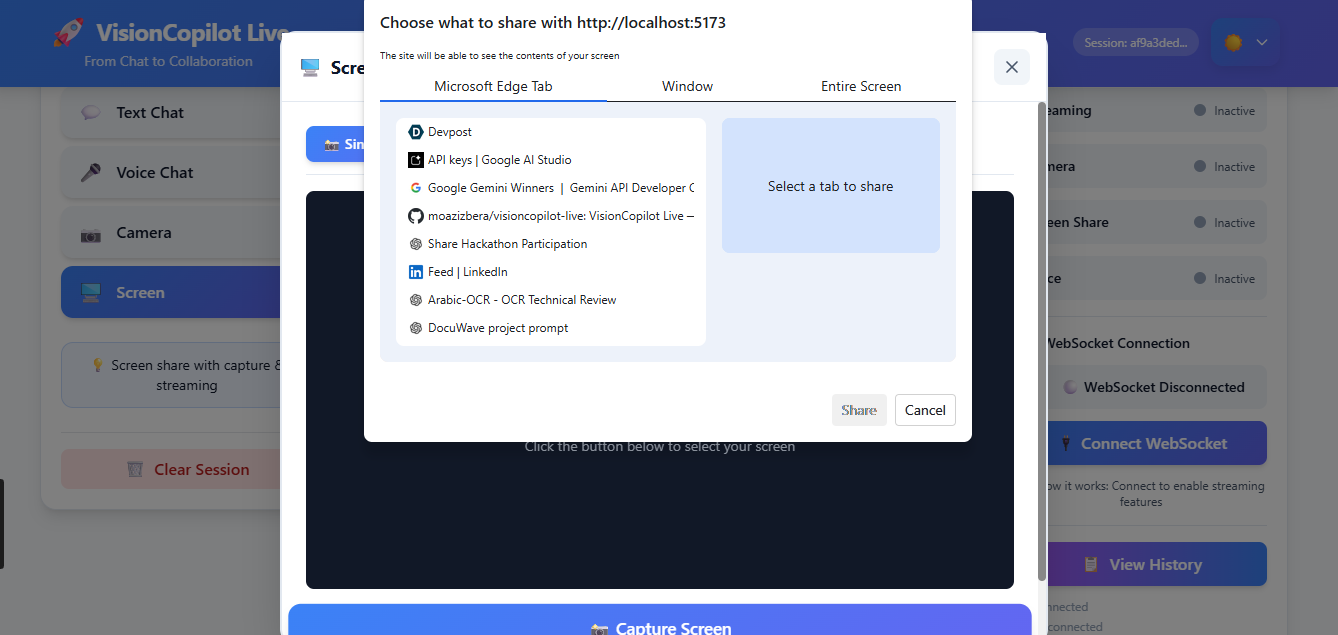
VisionCopilot Screen Sharing
-
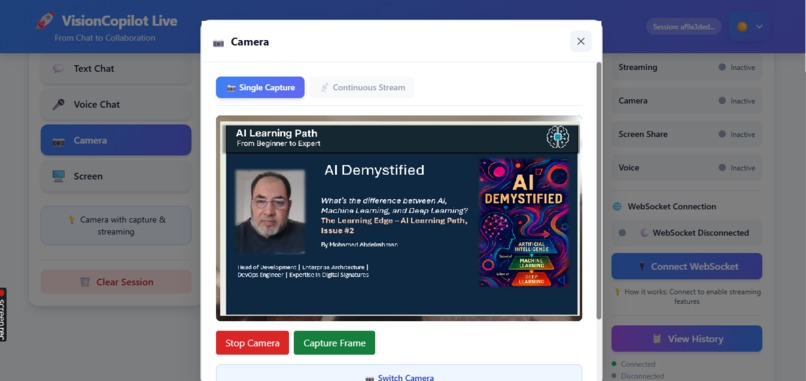
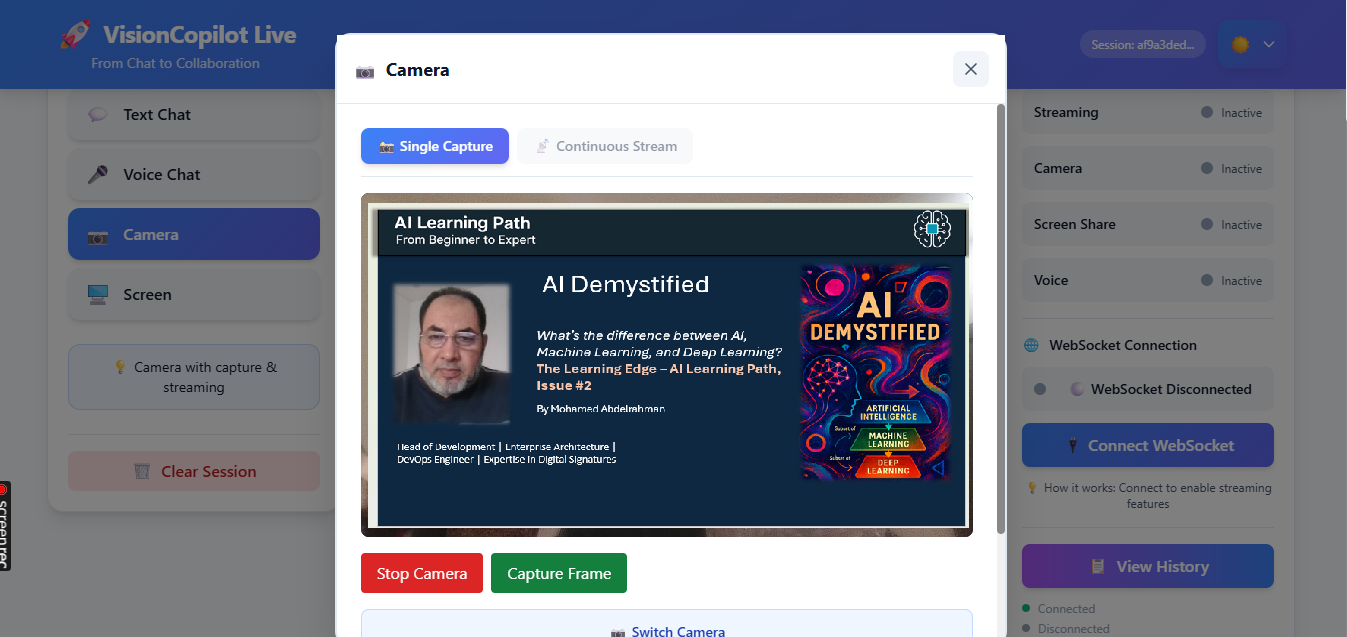
VisionCopilot Camera
-
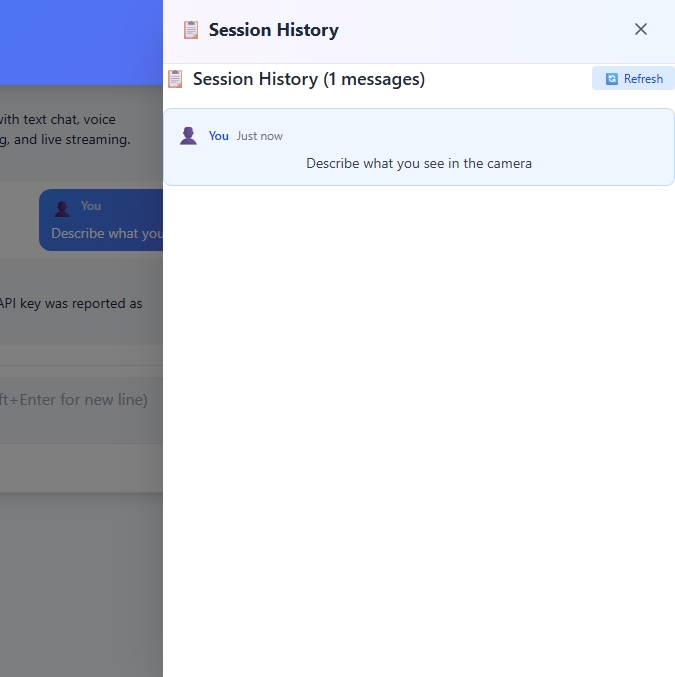
Session History
Inspiration
The way humans interact with AI is still largely limited to typing prompts into chat interfaces. While powerful, this interaction model does not reflect how people naturally communicate or solve problems.
We were inspired to build an AI system that behaves more like a real collaborator—one that can listen, observe, and understand context in real time. Modern multimodal models such as Google Gemini 2.5 Flash make it possible to move beyond passive chatbots toward interactive assistants that can process voice, vision, and screen context simultaneously.
VisionCopilot
Live was created to demonstrate what happens when AI is allowed to see what you see, hear what you say, and assist you instantly.
What it does
VisionCopilot Live is a real-time multimodal AI assistant that enables natural collaboration between humans and AI.
The system allows users to interact with AI through multiple modalities at the same time:
• Voice interaction – users can speak naturally and receive streamed responses. • Camera vision analysis – the AI can analyze visual input in real time. • Screen understanding – the assistant can interpret on-screen content and provide contextual guidance. • Live AI streaming – responses are streamed instantly using Google Gemini 2.5 Flash, creating a natural conversational experience.
Instead of asking static questions, users can collaborate with the assistant while working, learning, or solving problems.
How we built it
VisionCopilot Live was designed using a modular, real-time architecture.
Frontend
Built with React and TypeScript
TailwindCSS for responsive UI
WebRTC for media streaming
Web Speech API for voice input
Backend
Python with FastAPI
WebSocket streaming for real-time communication
Multimodal request handling
AI Layer
Integration with Google Gemini 2.5 Flash
Streaming responses for low latency
Context aggregation from voice, camera, and screen data
Infrastructure
Docker for containerized deployment
Cloud-ready architecture compatible with Google Cloud Run
The architecture allows the assistant to process multiple inputs simultaneously and generate contextual responses in real time.
Challenges we ran into
Building a real-time multimodal AI system introduced several technical challenges.
Real-time streaming latency
Maintaining fast responses while processing voice, video, and screen input required careful optimization of WebSocket communication and streaming APIs.
Multimodal synchronization
Combining voice input, visual frames, and screen context into a single coherent request required designing a custom event pipeline.
Frontend performance
Handling live media streams in the browser while maintaining UI responsiveness required careful management of WebRTC streams and React state updates.
Security and reliability
Ensuring proper handling of API keys, environment configuration, and session security was critical to making the project production-ready.
Accomplishments that we're proud of
We are proud of several key achievements in this project.
• Successfully built a real-time multimodal AI collaboration system. • Implemented live AI streaming with extremely low response latency. • Designed a clean and modular architecture suitable for real-world deployment. • Achieved a production-ready repository with strong documentation and developer tooling. • Demonstrated how AI can move from passive chat interfaces to active real-time collaboration.
Most importantly, the project shows how multimodal AI can transform human-AI interaction.
What we learned
This project provided valuable insights into the future of AI systems.
We learned that:
• Multimodal context dramatically improves AI usefulness. • Real-time streaming significantly enhances user experience compared to traditional request-response AI models. • Designing for low latency and asynchronous processing is essential for interactive AI systems. • Developer experience and documentation are critical when building open-source AI projects.
Working with Google Gemini 2.5 Flash also demonstrated how powerful modern AI models can be when integrated into real-time systems.
What's next for VisionCopilot Live
VisionCopilot Live is only the beginning. Future development will focus on expanding the assistant’s capabilities.
Planned improvements include:
• Persistent AI memory for ongoing conversations • Collaborative AI workspaces for teams • Expanded multimodal understanding including documents and applications • Plugin integrations for developer tools and productivity platforms • Edge optimization for faster local processing
Our vision is to evolve VisionCopilot Live into a fully collaborative AI copilot that works alongside users in real-world workflows.
Built With
- docker
- fastapi
- gemini-2.5-flash-api
- google-cloud-run
- python
- react
- tailwindcss
- typescript
- web-speech-api
- webrtc
- websockets


Log in or sign up for Devpost to join the conversation.