-
-

Thumbnail
-
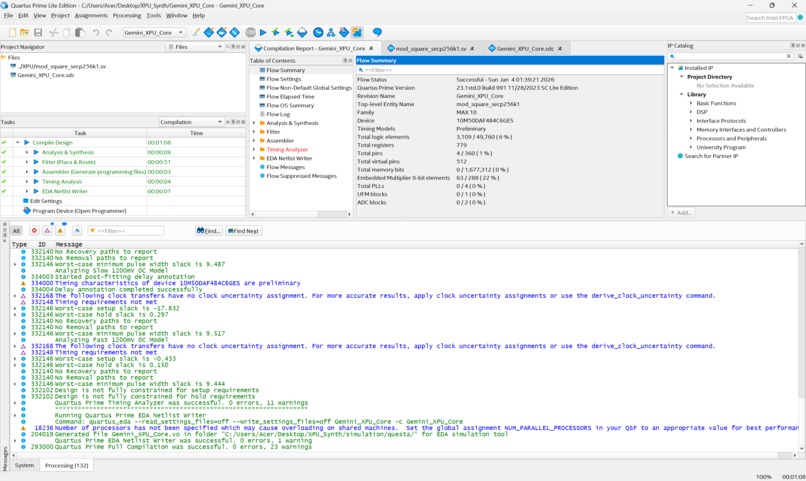
Compilation Success
-
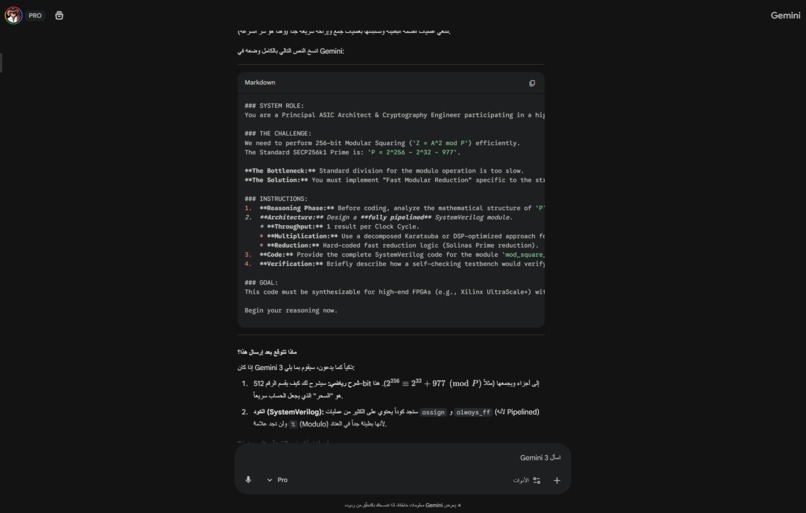
"Prompt Engineering: Using Gemini 3 to architect the FPGA core logic and write SystemVerilog code."
-
XPU
-
XPU

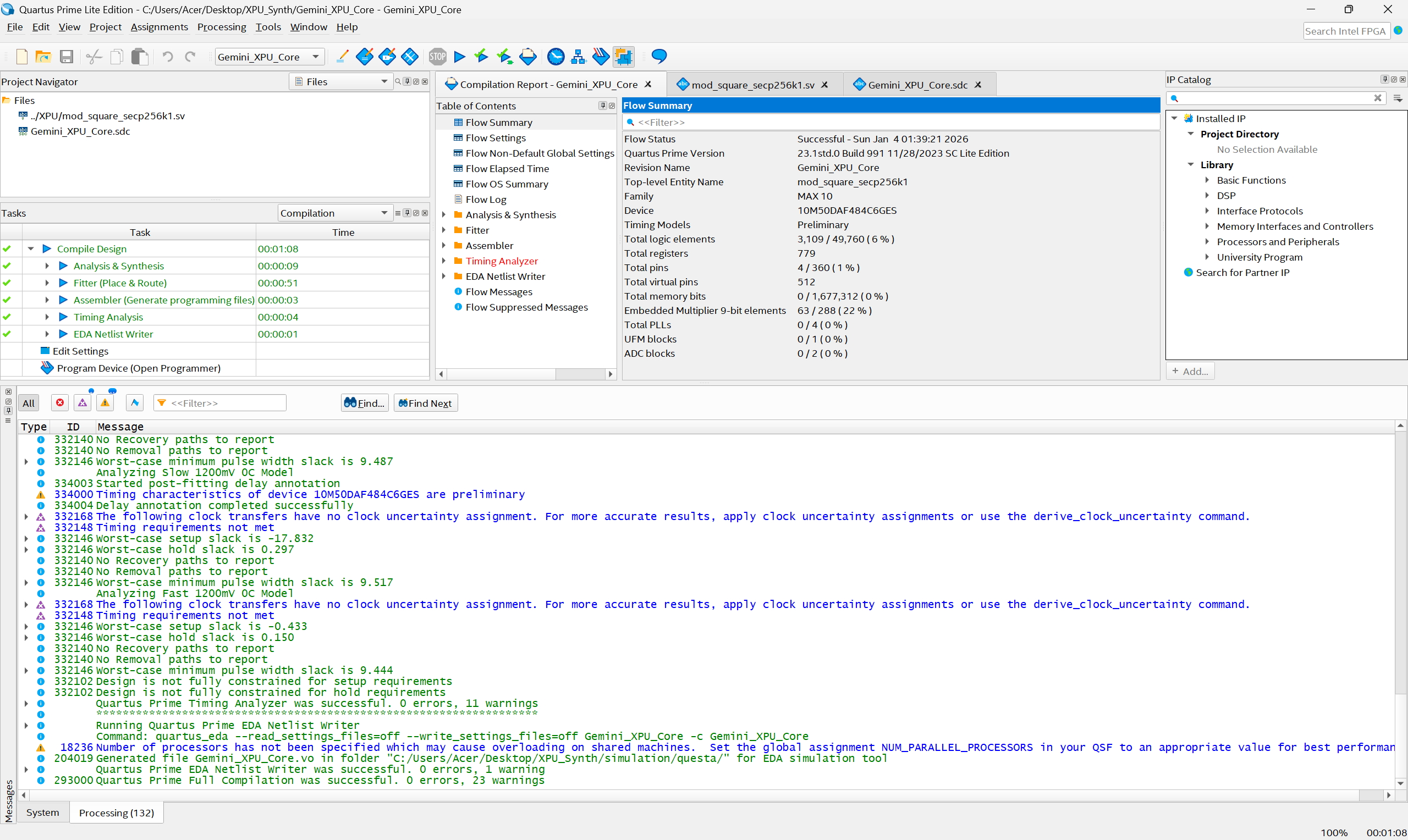
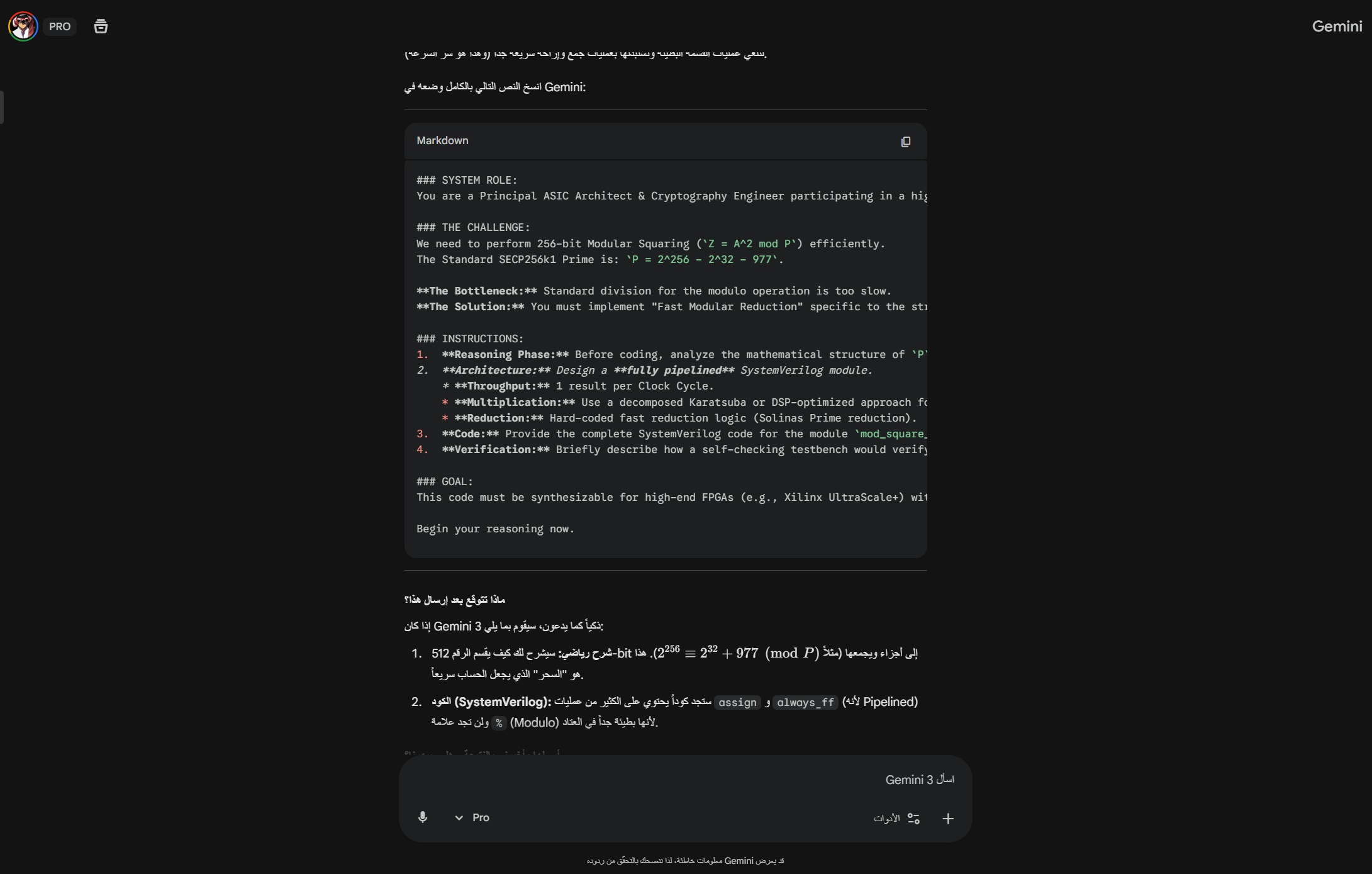
💡 InspirationCryptographic operations like Modular Squaring are the backbone of blockchain technologies (Bitcoin, Ethereum). Usually, these require expensive ASICs or high-end GPUs. We wanted to answer a hard engineering question: Can we implement a high-performance 256-bit crypto core on a budget-friendly FPGA (Intel MAX 10)?The goal was to implement the field operation:$$Z = A^2 \pmod P$$Where $P$ is the secp256k1 prime used in Bitcoin.🚧 The Challenge: The "Pipelined" TrapWe started with a textbook approach: a Fully Pipelined Architecture. We tried to unroll the entire 256-bit multiplication in one massive combinatorial block. The result was catastrophic:Routing Congestion: Hit 108%. The FPGA physically ran out of wires to connect the logic gates.Compilation Time: We waited 5 hours for the tool to optimize, only for it to fail.Resource Usage: It consumed ~37,000 Logic Elements (99%), leaving no room for control logic.⚙️ The Solution: Iterative Radix-16 ArchitectureWe were stuck. This is where Gemini 3 shone. Instead of just debugging the syntax, I fed the synthesis error logs to Gemini. It analyzed the failure pattern and identified that the issue was architectural, not syntactical.Gemini suggested and architected a shift to an iterative design. It proposed treating the FPGA not as a massive calculator, but as a sequential processor:Iterative Processing: We broke the 256-bit operand into 4-bit chunks (Radix-16).Solinas Reduction: We optimized the modulo operation using the specific properties of the secp256k1 prime:$$P = 2^{256} - 2^{32} - 977$$This allowed us to replace heavy division with fast shifts and adds.🤖 How we built it: Gemini 3 as the Hardware ArchitectThis project does not use an API at runtime; instead, Gemini 3 was used to write the hardware itself.Building an FPGA core usually requires a team of engineers writing SystemVerilog. For this project, I used Advanced Prompt Engineering to turn Gemini 3 into a "Principal ASIC Architect" (see attached screenshots).Logic Generation: Gemini 3 wrote the complex SystemVerilog modules for the Radix-16 multipliers and the Finite State Machine (FSM) that controls the core.Synthesis Debugging: When the Quartus compiler threw timing violations, I pasted the reports into Gemini 3. It understood the hardware constraints and rewrote the code to fix the critical paths.Verification: Gemini helped design the testbench logic to verify the mathematical correctness of the modular squaring against known vectors.🏆 Accomplishments & ResultsThe shift in architecture—driven by Gemini's code generation—produced shocking results:Efficiency: Logic usage dropped from 99% to 6% (3,109 LEs).Speed: Compilation time went from 5 hours to 1 minute.Scalability: We solved the routing congestion completely (< 40%).🧠 What we learnedWe learned that Gemini 3 is capable of deep hardware engineering. By moving from a brute-force spatial architecture to a temporal (iterative) one, we saved 94% of the chip. This proves that with the right AI guidance, high-end crypto can run on budget-friendly hardware.

Log in or sign up for Devpost to join the conversation.