-
-
1
-

2

✨ Gemini Vision-Voice Companion 💡 Inspiration
The vision behind Gemini Vision-Voice Companion was to create a truly hands-free intelligent assistant—one that doesn’t just hear, but also sees and understands the world around the user in real-time. In today’s fast-paced multitasking environment, I wanted to design an AI agent capable of:
Identifying objects instantly
Reading and interpreting documents
Describing surroundings dynamically
All this powered by the cutting-edge Gemini 1.5 Flash model, bridging the gap between human perception and machine intelligence.
🛠️ What It Does
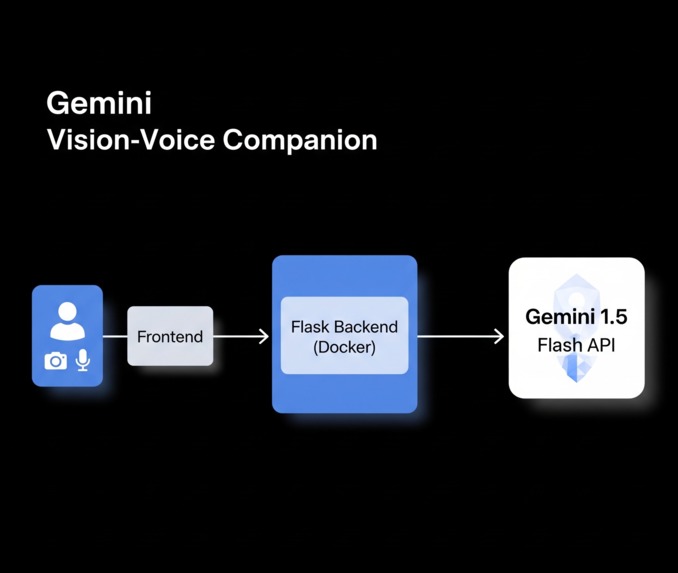
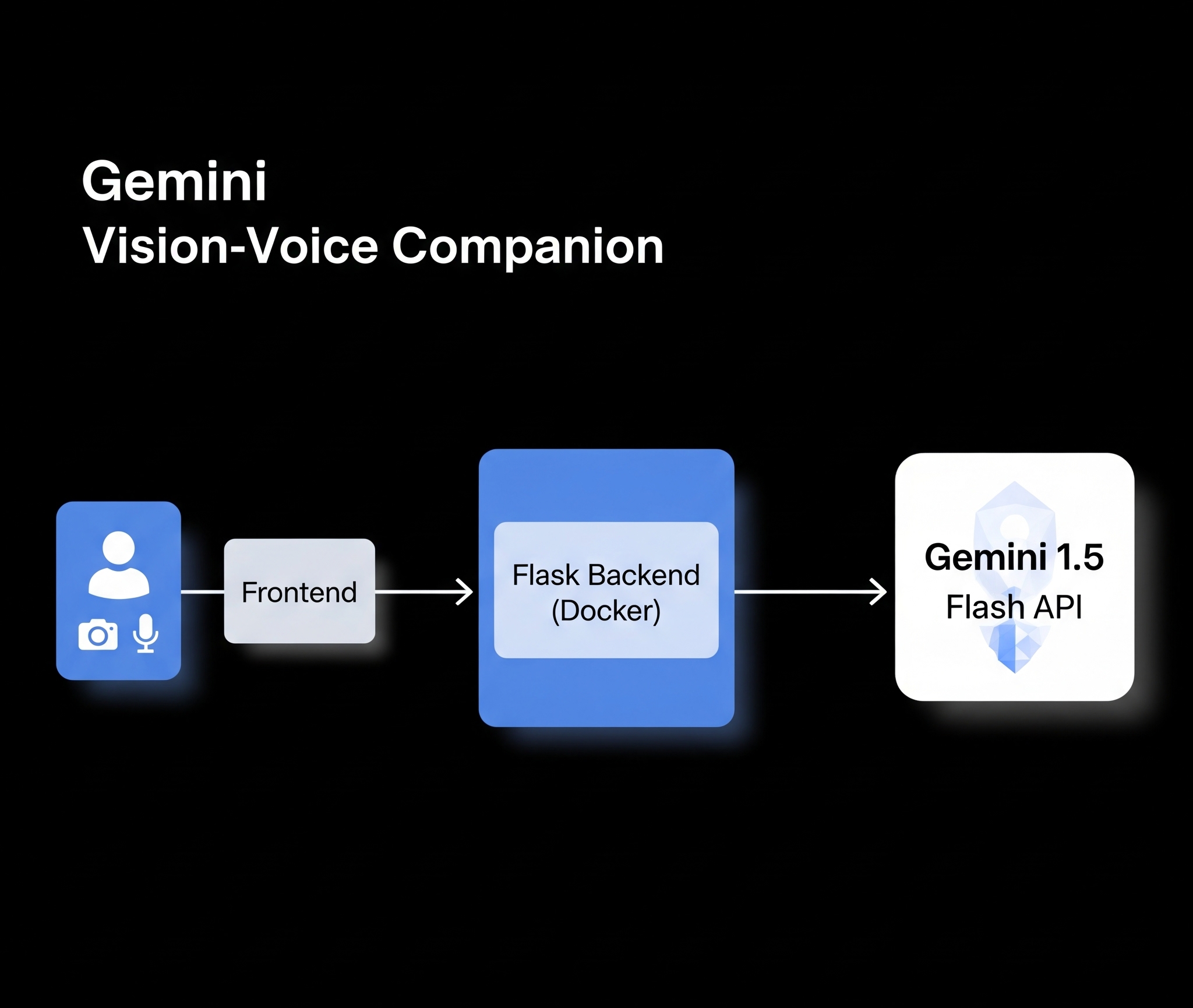
Gemini Vision-Voice Companion is a next-generation multimodal AI agent that combines live camera input with microphone audio to deliver high-speed reasoning and interaction.
Key Capabilities:
🎥 Visual Intelligence: Recognizes objects, explains complex scenes, and reads text in real-time from video streams.
🗣️ Natural Interaction: Users can ask questions naturally; the agent responds with context-aware, intelligent feedback.
⚡ Sub-Second Latency: Powered by Gemini 1.5 Flash, interactions feel like real-time conversation, creating a seamless human-AI experience.
🏗️ How I Built It
I focused on building a robust, cloud-native architecture optimized for speed and scalability:
Backend: Python Flask server handling live media streaming and API integration.
AI Core: Integrated Google Generative AI SDK to leverage Gemini 1.5 Flash for multimodal reasoning.
Containerization: Full Docker deployment ensures a cloud-ready environment on Google Cloud Run.
Frontend: Responsive interface built with HTML5, CSS3, and JavaScript to capture live video and audio.
⚔️ Challenges I Faced
Real-time Multimodal Buffering: Managing simultaneous video and audio streams without lag was critical.
Cloud Deployment Optimization: Keeping the application lightweight while ensuring compatibility across environments required careful Dockerization.
Solution: Optimized frame capture rates, used efficient data pipelines, and leveraged containerized deployment for consistency.
🏆 Accomplishments I’m Proud Of
Successfully integrated real-time video reasoning with vocal interaction.
Built a fully cloud-ready architecture deployable on Google Cloud Run.
Achieved sub-second response latency for a seamless, real-time experience.
📚 Lessons Learned
Gained deep understanding of multimodal AI prompting.
Learned to architect high-performance, real-time AI agents.
Explored the Google Cloud ecosystem and the capabilities of Gemini 1.5 Flash for live, interactive applications.
🌱 What’s Next
The next steps for Gemini Vision-Voice Companion aim to make it a universal assistant:
Local Session Storage: Preserve interactions for smarter, contextual follow-ups.
Real-Time Translation: Break language barriers with instant, multilingual support.
Advanced Object Tracking: Enable continuous environmental understanding for richer interaction.
Specialized Tools Integration: Extend AI capabilities to cover professional and accessibility needs.
Goal: Transform Gemini Vision-Voice Companion into an AI that is truly aware, proactive, and indispensable in daily life.


Log in or sign up for Devpost to join the conversation.