-
-
solved cube
Inspiration
For the Gemini Live Agent Challenge, we were tasked with redefining how users interact with AI—stopping typing and starting interacting. I was inspired to create an experience where the AI can "see, hear, and speak" simultaneously, breaking out of the traditional text-based chatbot paradigm. I decided to build The Gemini Rubik’s Tutor, featuring "Cubey," a patient, observant AI who watches you solve a physical puzzle in the real world and coaches you step-by-step through voice.
What it does
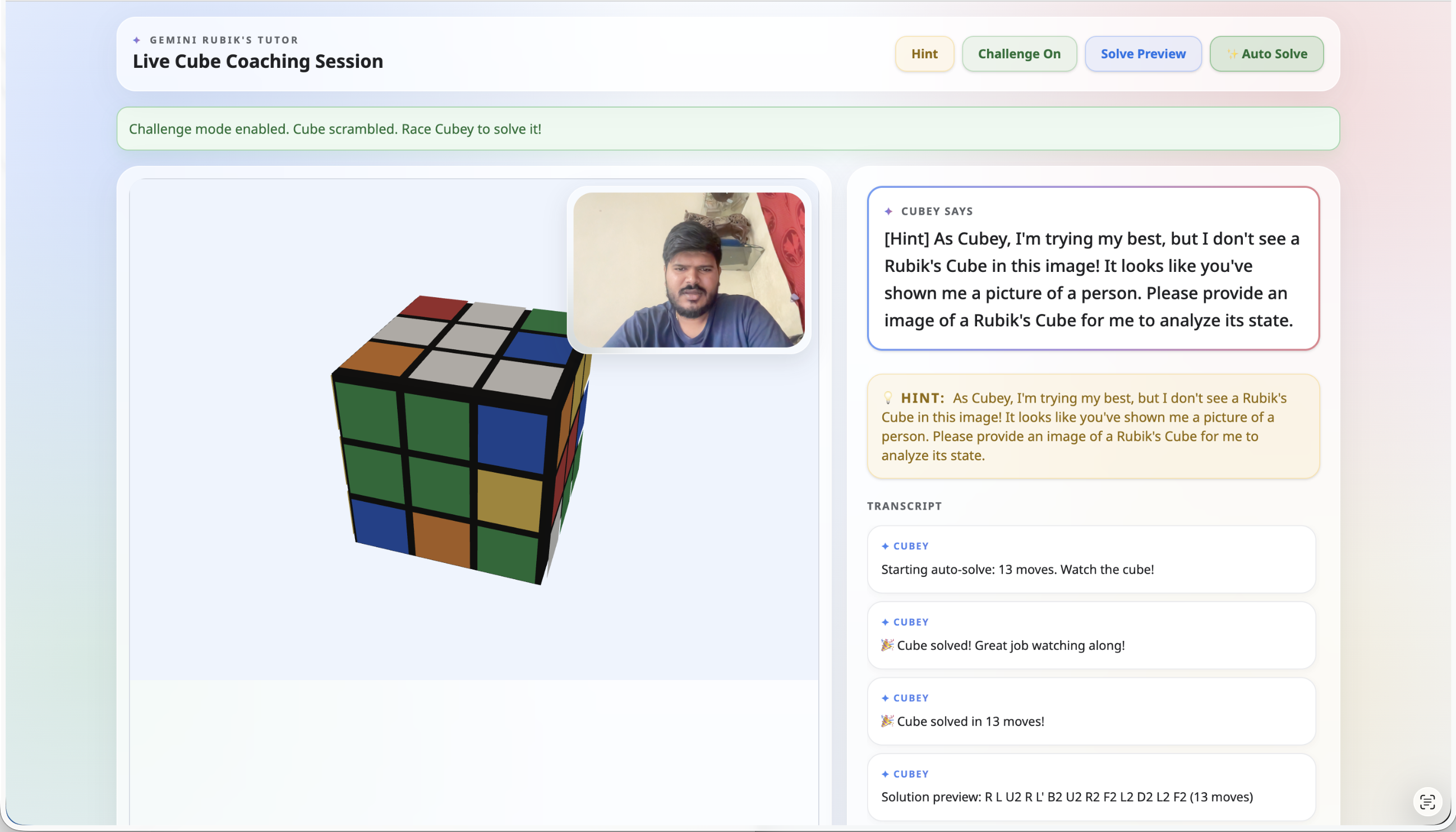
You don't use your keyboard. You use both hands to hold your physical Rubik's Cube. You simply talk to Cubey.
"Cubey, I'm stuck. Where does this red piece go?"
Cubey looks through your camera, verifies the state against its internal Kociemba solver, and responds aloud: "I see it! You're doing great. Turn the top face clockwise towards you."
As it speaks, a beautiful 3D visualization animates the move on your screen.
How we built it (Architecture)
The architecture seamlessly weaves together real-time browser MediaStreams, WebSockets, Google Cloud Run, and the powerful @google/genaiGemini Live API.
The "Eyes" (Real-Time Vision): The React frontend captures the webcam feed and samples the ` "buffer" at ~4 frames per second into compressed "image/jpeg" frames. These are piped over a WebSocket to a Node.js backend, which injects them directly into the active Gemini Live bidirectional stream.
The "Ears & Voice" (Gapless Web Audio): We capture PCM16LE raw audio via the browser's audio context and send it to Gemini constantly. When Gemini responds, our backend forwards the raw PCM stream back to the client, scheduling it on the
AudioContexttimeline for perfectly gapless playback.Anti-Hallucination (Grounding the AI): To prevent the LLM from hallucinating impossible moves, I implemented the Kociemba Algorithm locally. The backend coordinates the detected state with the deterministic Kociemba solver and whispers the absolute ground truth move to Gemini in system prompts, which Gemini then communicates naturally.
Challenges we ran into
Gapless Audio Buffering: Real-time speech from Gemini arrives in small PCM chunks. We learned that using standard HTML5
<audio>tags caused stuttering, forcing us to use the browserAudioContextfor flawless playback.WebSockets on Serverless: We learned that Vercel Serverless Functions do not natively support stateful WebSockets. This requirement forced us into a split-monorepo design—putting the frontend on Vercel/GitHub Pages and orchestrating the WebSocket backend securely on Google Cloud Run.
Accomplishments that we're proud of
Implementing a fully real-time Live API application that eliminates the keyboard entirely.
Successfully routing audio and video streams simultaneously over WebSockets without overwhelming the connection.
Completely eliminating AI "hallucination" in puzzle-solving by rigidly grounding Gemini's outputs in a local solver.
What we learned
When you combine real-world physical object manipulation with low-latency audio and vision, an LLM stops feeling like a "bot" and starts feeling like a localized, aware assistant. The future of interaction is hands-free, continuous, and "live"!
Findings & Data Sources
Vision Limitations vs Ground Truth: We found that depending solely on visual frame ingestion (
image/jpegat 4 fps) to completely understand the mathematical state of a Rubik's cube led to LLM hallucinations, as small lighting changes could distort color perception. To fix this, we heavily utilized the Kociemba Two-Phase Algorithm repository as our data source to maintain a local ground truth matrix, feeding this structured data to Gemini as context alongside the visual feed.Data Privacy: No persistent user data is recorded. Images processed by Gemini are done ephemerally via
wsstreaming protocols in the live connect session.
Built With
- gemini-live-api
- google-cloud-run
- google-genai-sdk
- node.js
- react
- terraform
- three.js
- websockets

Log in or sign up for Devpost to join the conversation.