Inspiration:-
AI assistants today mostly rely on text-based interaction. However, real-world interaction involves multiple forms of input such as voice, images, and natural conversation. The idea behind Gemini Multimodal Copilot was to build an AI assistant that can understand multiple types of inputs simultaneously.
What it does:-
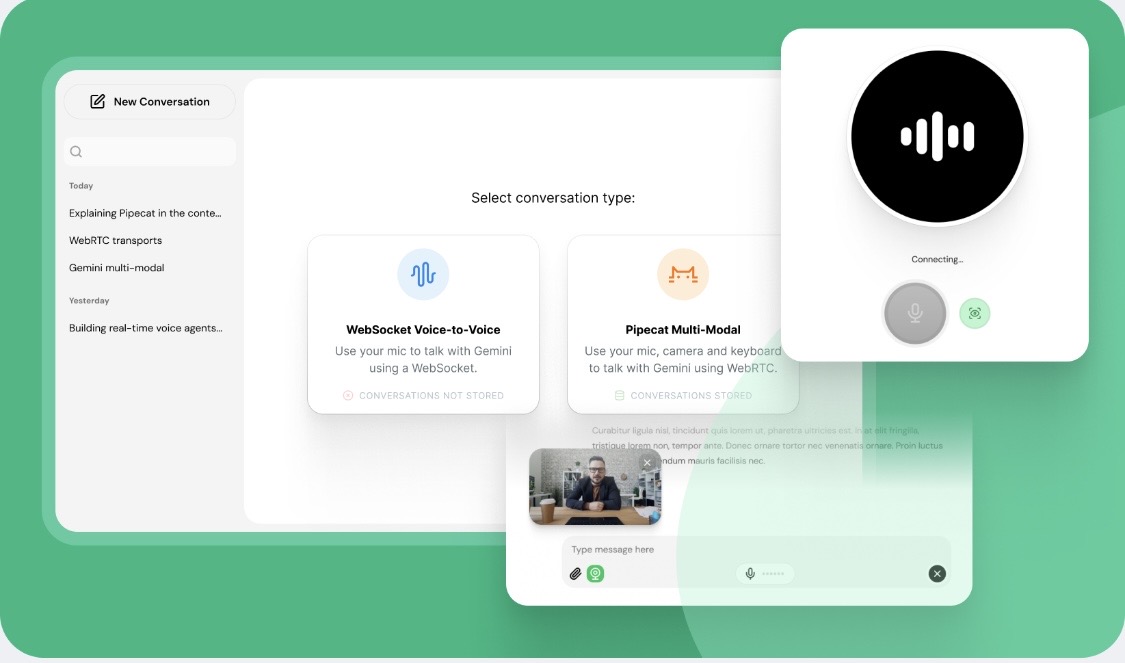
Gemini Multimodal Copilot is an AI assistant powered by the Gemini API that can understand voice, images, and text in real time. Users can interact with the system by asking questions, showing objects through the camera, or speaking to the assistant.
The system analyzes these inputs using Gemini’s multimodal reasoning capabilities and generates intelligent responses.
How we built it:-
The project is built using a client-server architecture. The frontend interface allows users to interact using voice, images, and text. The backend server processes the inputs and sends them to the Gemini API through the Pipecat framework, which enables real-time multimodal communication.
Challenges we ran into:-
Working with multimodal inputs required handling multiple streams such as voice, text, and visual data. Ensuring smooth real-time responses while maintaining low latency was a key challenge.
What we learned:-
We learned how powerful multimodal AI systems can be when different input types are combined. Integrating Gemini with real-time interaction frameworks also gave us insight into building next-generation AI assistants.
What’s next:-
Future improvements include adding more advanced reasoning capabilities, integrating additional sensors, and expanding the assistant to support real-world applications such as education, accessibility, and productivity tools.

Log in or sign up for Devpost to join the conversation.