Inspiration
Most assistants are still trapped in text boxes. We wanted an agent that can actually see the interface and execute user intent on real screens.
What it does
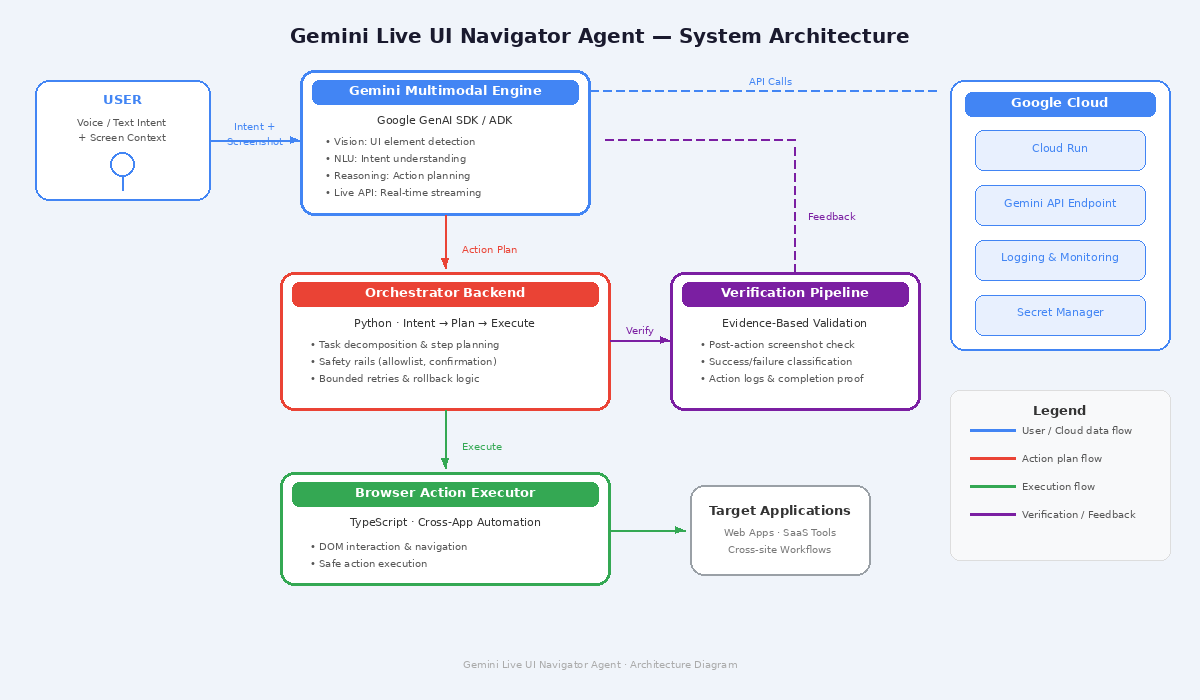
Gemini Live UI Navigator Agent is a multimodal UI operator. It ingests screenshots/screen context, reasons about UI state with Gemini, plans executable steps, performs safe actions, and verifies outcomes with evidence.
How we built it
- Gemini multimodal reasoning layer (Google GenAI SDK / ADK-compatible design)
- Orchestrator backend for intent -> plan -> execute flow
- Browser action executor for cross-site workflows
- Verification pipeline with action logs and completion proof
- Google Cloud deployment path (Cloud Run target architecture)
Challenges we ran into
- Building robust action plans when UI changes dynamically
- Preventing unsafe actions while keeping high task success rate
- Ensuring evidence-based completion (not false-positive success)
Accomplishments that we're proud of
- End-to-end UI navigation loop from visual input to action execution
- Clear safety rails (allowlist, confirmation step, bounded retries)
- Submission-ready architecture aligned with Gemini Live challenge requirements
What we learned
- Multimodal context dramatically improves automation reliability
- Verification and rollback are as important as planning
- Agent UX quality depends on interruption handling and deterministic execution paths
What's next
- Stronger fallback plans for edge-case UI states
- Better real-time interruption handling
- Expanded benchmark tasks and public demo scenarios
Built With
- adk
- browser-automation
- gemini
- google-cloud-run
- google-genai-sdk
- multimodal-ai
- prompt
- python
- typescript


Log in or sign up for Devpost to join the conversation.