Inspiration
Most AI assistants today rely mainly on text input. However, real-world human interaction involves multiple senses such as speech, vision, and context. With the rise of powerful multimodal AI models like Gemini, it is now possible to create agents that can interact with users in a more natural and intuitive way. The inspiration behind this project was to explore how an AI assistant could simultaneously hear, see, and speak, enabling real-time interaction using voice commands and visual understanding through a camera. Our goal was to build a system where users could talk to an AI assistant and show objects through their webcam, allowing the AI to analyze the scene and respond intelligently.
What it does
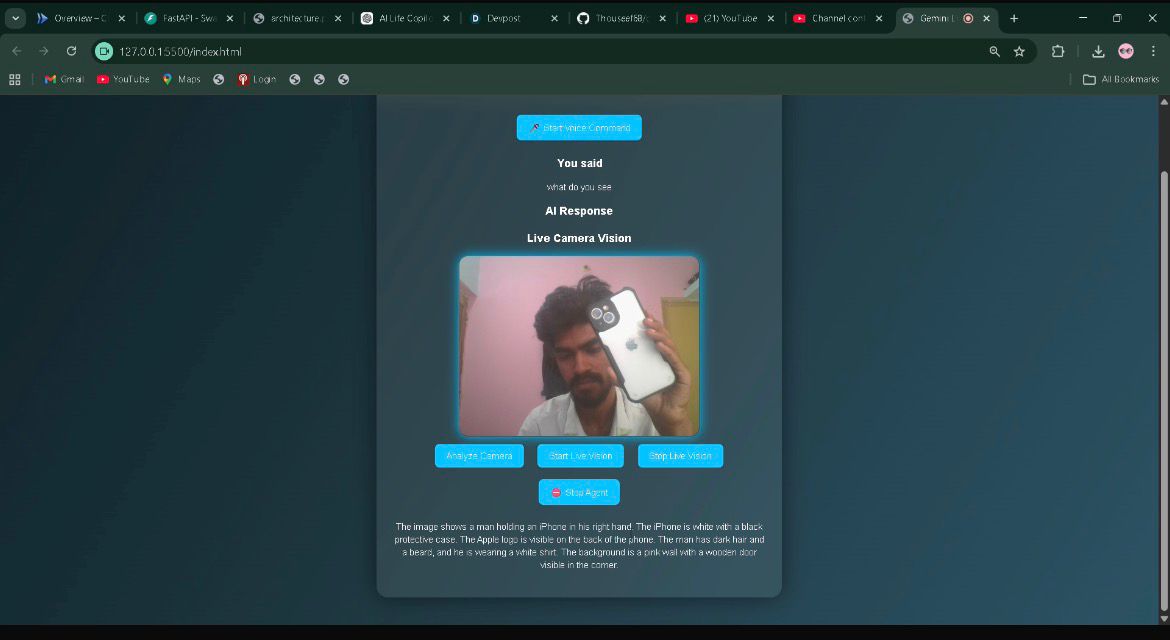
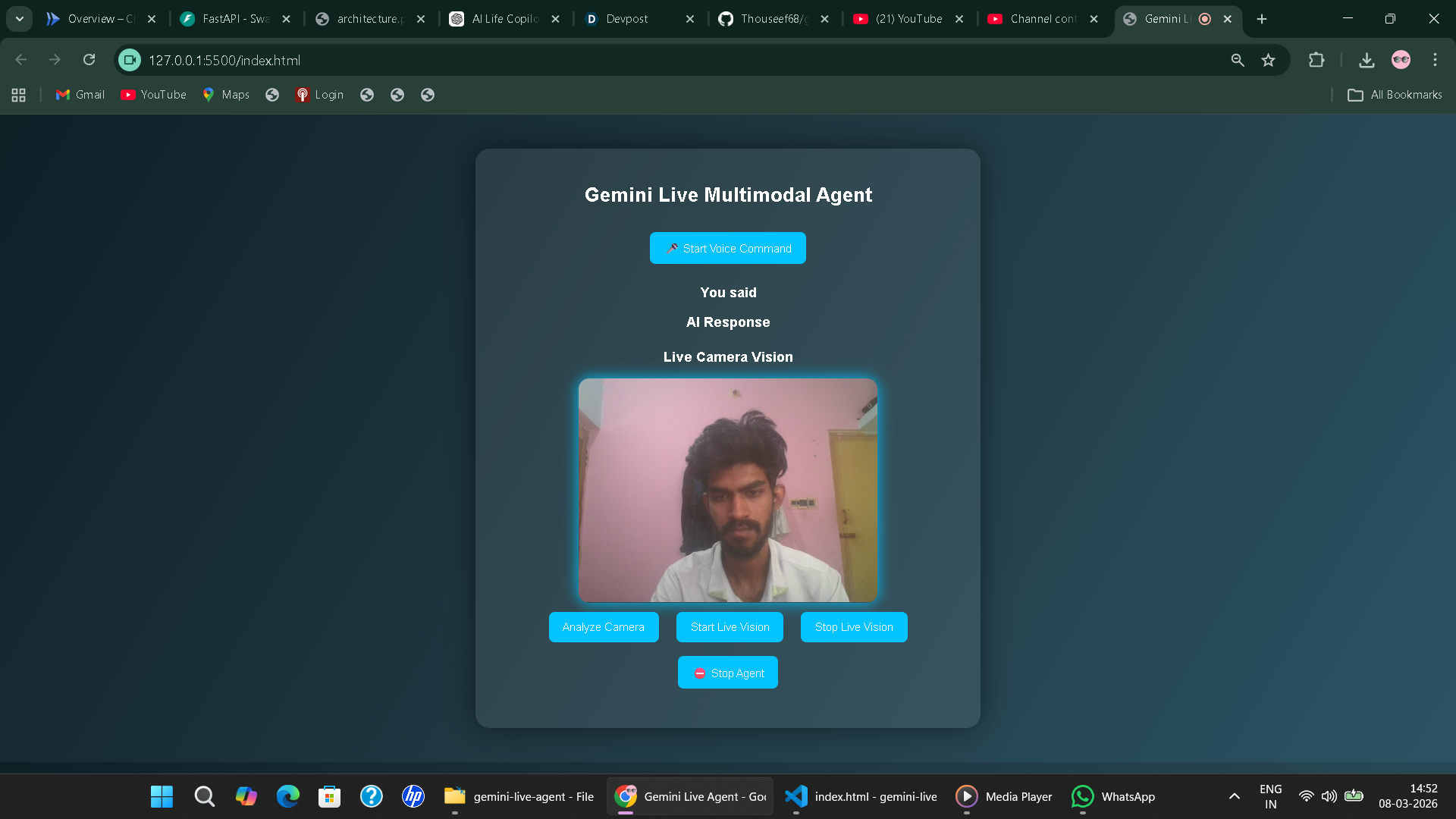
Gemini Live Multimodal Agent is an interactive AI assistant that can:
- Listen to voice commands using browser speech recognition
- Analyze live camera input using Gemini vision capabilities
- Generate intelligent responses using Gemini
- Speak responses back to the user
- Continuously analyze scenes through a live vision mode
For example, a user can ask:
"What do you see?"
The system captures a frame from the webcam, sends it to Gemini for visual understanding, and then provides a spoken explanation of the scene.
This creates a seamless multimodal AI experience where users can interact with the assistant naturally through both voice and visual input.
How we built it
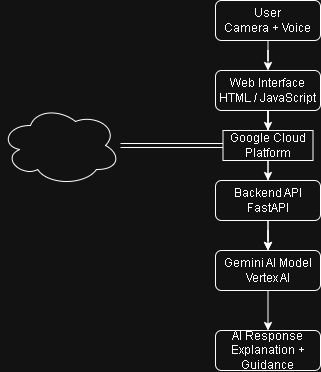
The system consists of a web-based frontend and a cloud-based backend.
Frontend
The frontend was built using HTML and JavaScript and runs directly in the browser. It uses several browser APIs to enable real-time interaction:
- Web Speech API for voice recognition
- Speech Synthesis API for spoken responses
- Web Camera API for capturing images from the webcam
These components allow users to interact with the AI agent using voice and live camera input.
Backend
The backend was developed using FastAPI (Python) and deployed on Google Cloud Run.
The backend processes requests from the frontend and communicates with the Gemini model through Vertex AI.
There are two main processing flows:
- Voice queries are sent to Gemini to generate intelligent responses.
- Camera frames captured from the webcam are analyzed by Gemini for image understanding.
The AI response is then returned to the frontend and spoken back to the user.
Challenges we ran into
One of the main challenges was integrating multiple input modalities in real time. Coordinating voice input, camera capture, AI processing, and speech output required careful synchronization between the frontend and backend.
Another challenge was deploying the backend service on Google Cloud Run and ensuring reliable communication between the frontend and the Gemini model through Vertex AI.
Handling continuous live vision while avoiding overlapping speech responses also required additional logic to manage the system smoothly.
Accomplishments that we're proud of
We successfully built a fully functional multimodal AI agent capable of interacting with users through both voice and vision in real time.
The system integrates several technologies including browser APIs, FastAPI, Google Cloud Run, and Gemini through Vertex AI.
We are proud that the project demonstrates how modern AI models can power real-time interactive systems that feel more natural than traditional text-based interfaces.
What we learned
During the development of this project we learned how to integrate multimodal AI capabilities using Gemini and how to deploy scalable backend services using Google Cloud Run.
We also gained experience working with browser APIs for speech recognition, speech synthesis, and webcam interaction to create real-time AI applications.
This project helped us better understand how multimodal AI systems can combine voice, vision, and reasoning to create more intelligent and interactive user experiences.
What's next for Gemini Live Multimodal Agent
Future improvements could include:
- Adding conversational memory so the AI can remember previous interactions
- Improving the user interface with richer visual feedback and animations
- Supporting mobile devices and cross-platform interaction
- Adding object detection and scene tracking for more advanced visual understanding
- Expanding the agent to assist with real-world tasks based on what it sees
We believe multimodal AI agents will play a major role in the future of human-AI interaction, and this project is a step toward that vision.
Built With
- fastapi
- html
- javascript
- python
- speech-synthesis
- web-speech-api
- webcam-api


Log in or sign up for Devpost to join the conversation.