-
-
Initial Site
-
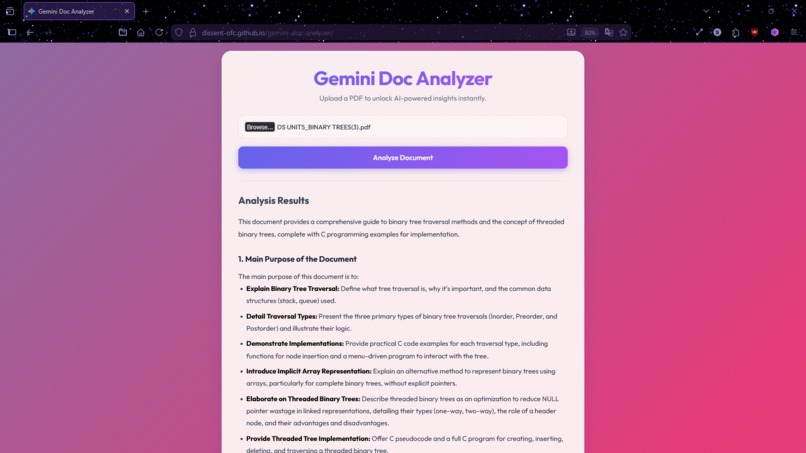
After a file has been uploaded

Inspiration
Most documents that matter the most are also the ones people read the least. Reports are skimmed, contracts are postponed, and research papers are bookmarked "for later" and rarely opened again. The problem is not a lack of information, but the time and effort required to extract meaning from dense, visually complex documents.
I wanted to explore whether modern multimodal AI could reduce this friction. Instead of asking people to read hundreds of lines of text, what if an AI system could see a document the way a human does and summarize it instantly? That question became the foundation of Gemini Doc Analyzer.
What it does
Gemini Doc Analyzer allows users to upload a PDF and receive a clean, structured Markdown summary in seconds. Unlike traditional OCR-based tools, the system processes the document visually, preserving layout, tables, charts, and hierarchical structure.
The output highlights:
- Key insights and conclusions
- Action items and important points
- Structured data from tables and figures
This makes long or complex PDFs immediately understandable and usable.
How It Was Built
The project is composed of a React-based frontend and a FastAPI backend.
On the backend, uploaded PDFs are processed entirely in memory and passed to a multimodal AI model capable of visual document understanding. Instead of extracting raw text alone, the model reasons over the document's layout and structure. The resulting analysis is returned as formatted Markdown.
On the frontend, React renders the Markdown output in real time, allowing users to read, copy, and share insights without leaving the interface. The UI emphasizes clarity and focus, using a glassmorphism-inspired design to keep attention on the content.
Challenges Faced
One of the biggest challenges was ensuring reliable interpretation of complex layouts. PDFs can vary wildly in structure, and maintaining consistency across tables, multi-column text, and embedded graphics required careful prompt design and output validation.
Another challenge was performance. Processing large documents while keeping response times low meant optimizing in-memory handling and minimizing unnecessary transformations.
Finally, presenting AI-generated content in a way that felt trustworthy and readable required multiple iterations on formatting, hierarchy, and phrasing.
What we learned
This project reinforced the importance of treating documents as visual artifacts, not just text blobs. Multimodal models unlock a different class of applications where structure and context matter as much as words.
What's next for Gemini Doc Analyzer
The next phase of Gemini Doc Analyzer focuses on interaction. Rather than stopping at static summaries, the goal is to make documents conversational.
A planned feature is an AI-powered chatbot that allows users to ask follow-up questions directly about their uploaded documents. Instead of rereading or rescanning summaries, users will be able to ask natural questions such as "What are the main risks?" or "Summarize this section in one paragraph" and receive contextual answers grounded in the document.
Beyond text, voice interaction is another major direction. By adding speech input and output, users will be able to talk to their documents and listen to responses, making the tool more accessible and useful in hands-free or mobile scenarios.
Longer-term improvements include richer interactivity with tables and charts, document comparison, and persistent conversational context across sessions. The ultimate goal is to transform static PDFs into dynamic, interactive knowledge sources powered by AI.


Log in or sign up for Devpost to join the conversation.