-
-
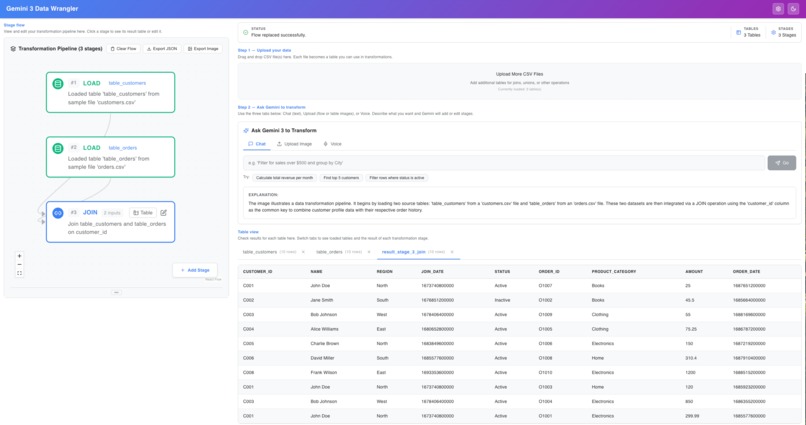
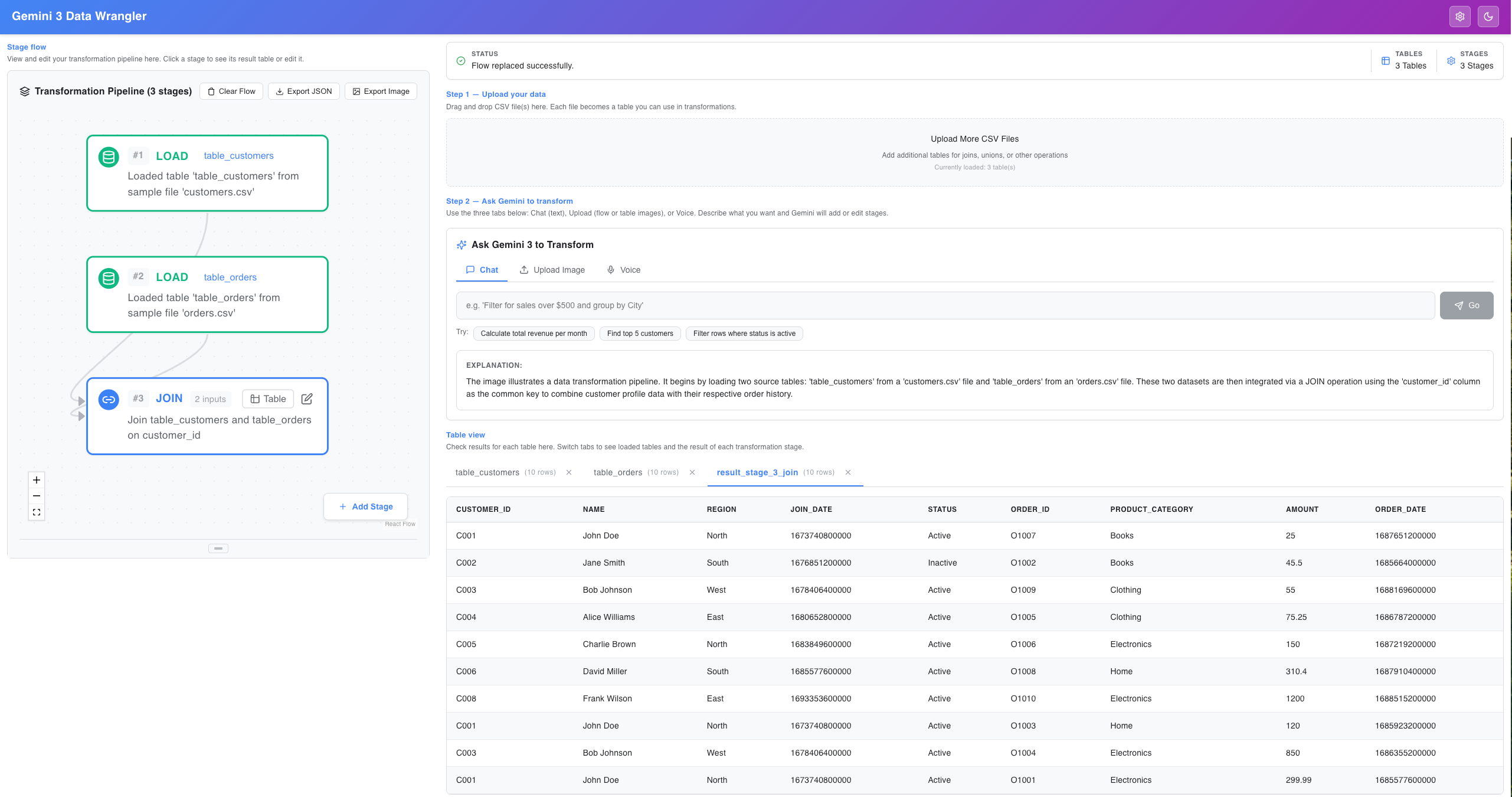
Dashboard
-
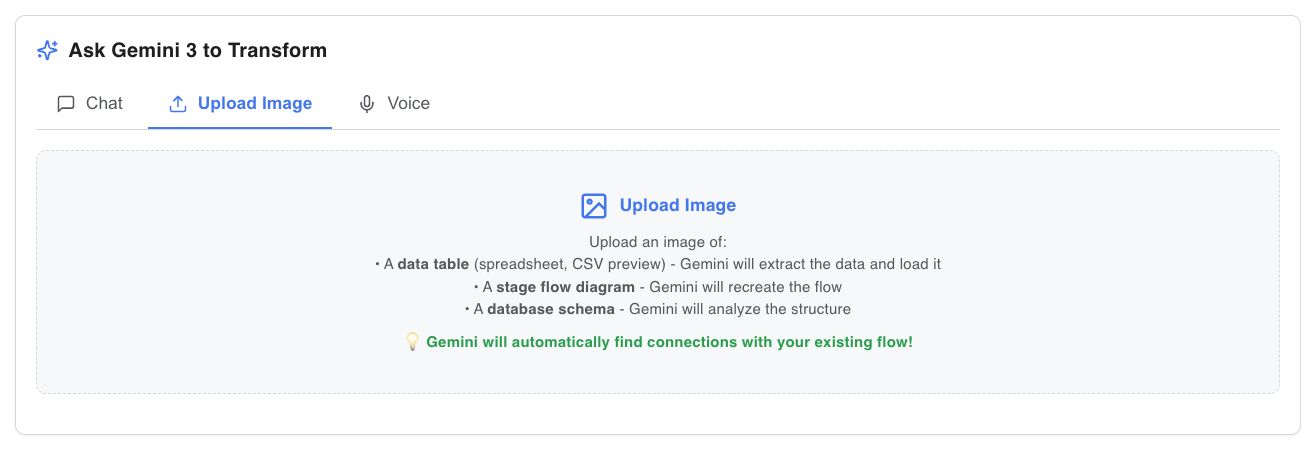
Image message
-
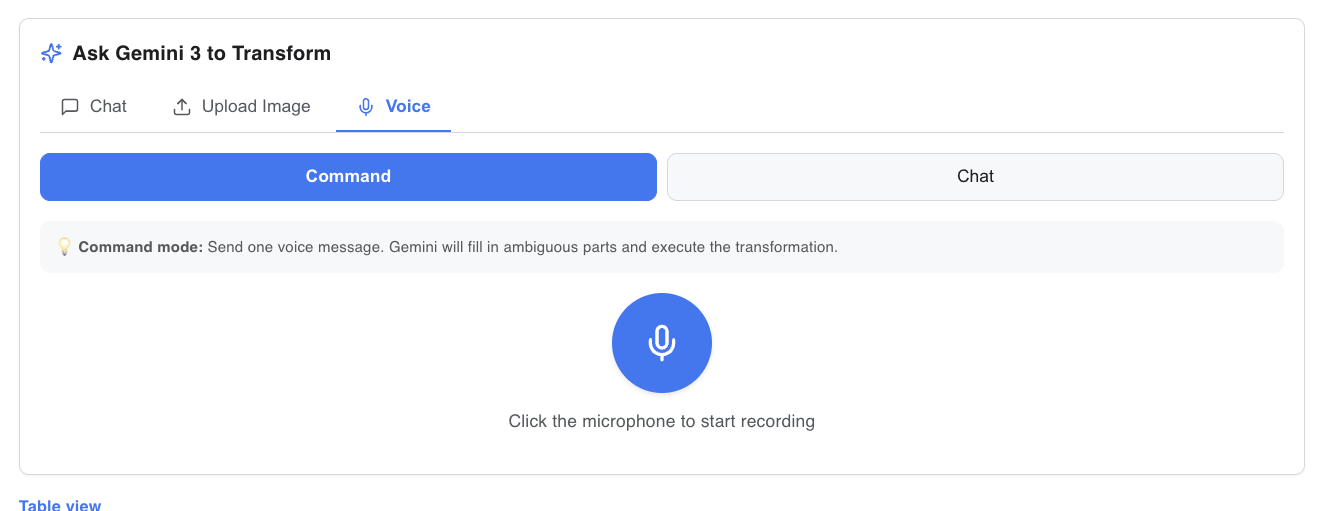
Voice message
-
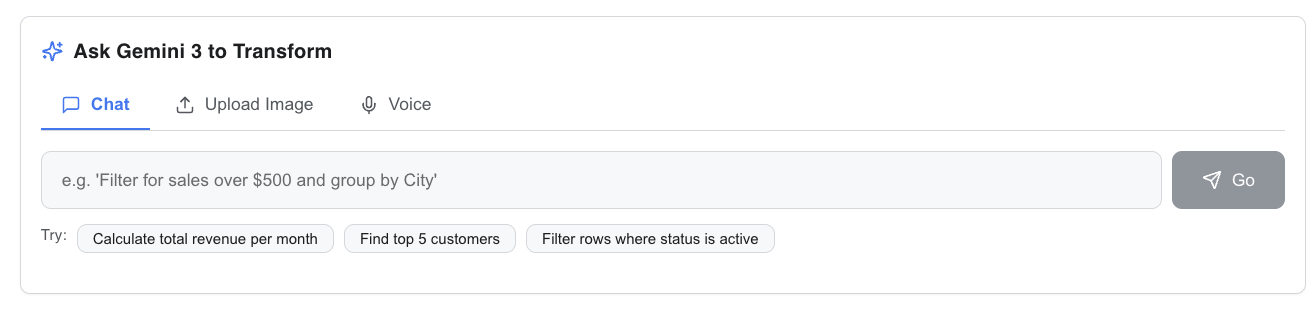
Text message
Inspiration
Data transformation is common in traditional ETL workflows. Data analysts and engineers spend roughly 80% of their time just cleaning data—standardizing date formats, fixing messy state codes, or merging disparate CSVs—and only 20% actually analyzing it. The standard tools (Excel, Python/Pandas, SQL) often have a steep learning curve or are "heavy" to set up.
More importantly, privacy is a massive friction point. Many users are terrified (rightfully so) of uploading sensitive financial or customer data to a cloud-based SaaS just to perform a simple join or filter.
We asked ourselves: What if the AI Intelligence came to the data, instead of the data going to the AI? What if we could build a tool that has the reasoning power of Gemini 3 but executes everything locally on your device?
What it does
Gemini Data Wrangler is a privacy-first, browser-based ETL (Extract, Transform, Load) agent.
- Local-First Processing: Users drag & drop massive CSVs, and the data is loaded instantly into DuckDB-Wasm, a high-performance analytical database running entirely inside the browser. Your raw rows never leave your laptop.
- Natural Language ETL: Instead of writing complex SQL or Regex, users simply chat: "Join these tables on email, filter for sales over $500, and group by Region."
- Agentic Reasoning: Powered by Gemini 3, the system doesn't just write code; it plans a pipeline. It intelligently maps fuzzy column names (e.g., mapping
user_idtouid), suggests cleaning steps for dirty data, and auto-generates visualization configs. - Instant Visualization: The app automatically generates the most appropriate charts (Bar, Line, Scatter) based on the transformation results using Recharts.
How we built it
We used a Hybrid Architecture to balance massive intelligence with strict privacy:
- The Brain (Gemini 3 Flash): We use Gemini's advanced reasoning capabilities to understand user intent. We send only the table schema (column names and types) and the user's prompt to the API. Gemini returns a structured JSON plan containing valid DuckDB SQL.
- The Engine (DuckDB-Wasm): We run DuckDB compiled to WebAssembly. This allows us to execute complex SQL queries (Joins, Window Functions, Aggregations) on millions of rows at 60FPS directly in the client.
- The Frontend (React + Vite + TypeScript): A responsive SPA that handles the "Agentic" state. When Gemini suggests a transformation, the UI updates to show the new "Stage" in the pipeline, which the user can manually tweak.
- The Backend (Node.js): A lightweight, secure proxy that handles authentication with Google's Generative AI, ensuring our API keys remain secure while facilitating the schema-only communication.
Challenges we ran into
- The "Hallucination" Problem: Early on, the AI would invent SQL functions that didn't exist in DuckDB. We solved this by feeding Gemini a strict "System Instruction" containing the supported SQL dialect and using Zod schemas to validate the JSON output before execution.
- Browser Memory Limits: WebAssembly has a hard memory cap (typically 4GB). Loading large CSVs as JSON strings would crash the tab. We optimized this by using Apache Arrow for zero-copy data transfer between DuckDB and React, significantly reducing memory overhead.
- Context Window Management: Passing schemas for tables with 100+ columns was tricky. We implemented a summarization step that sends only relevant column statistics (min, max, type) to give Gemini "eyes" on the data shape without exceeding token limits or confusing the model.
Accomplishments that we're proud of
- True Privacy Architecture: We successfully decoupled the logic (AI) from the data (Local). The schema goes up; the SQL comes down; the sensitive data stays put.
- Sub-Second Latency: By leveraging Gemini 3 Flash, the latency between "Asking" and "Seeing the Table Update" is almost instantaneous, making the tool feel like a pair programmer rather than a chatbot.
- The "Self-Healing" Pipeline: If a user's data contains errors (e.g., text "N/A" in a number column) that cause a SQL crash, the agent catches the error and automatically suggests a specific "Filter" or "Cast" stage to fix it.
What we learned
- Agentic UI > Chatbots: Users don't just want a chat window that outputs code blocks. They want the AI to manipulate the UI controls directly. We learned to make Gemini "push" state changes to our React store to add/remove filter cards.
- Wasm is Production-Ready: Running heavy analytical compute in the browser is viable and creates a snappier experience than round-tripping data to a Python backend.
- Structured Outputs are Key: Using Gemini's ability to output strict JSON was critical for integrating the "Brain" with the "UI."
What's next for Gemini Data Wrangler
- Gemini Vision Integration: Allow users to upload a screenshot of a specific chart or report format they need, and have the agent automatically reverse-engineer the SQL pipeline to match it.
- Export to Code: Generate a reproducible Python/Pandas script or a DBT model so users can take their cleaning pipeline from our tool into production.
- Offline Mode: We are exploring Gemini Nano to move even the reasoning step entirely onto the device, achieving 100% offline usage for maximum security.
Built With
- duckdb-wasm
- gemini
- node.js
- react
- typescript

Log in or sign up for Devpost to join the conversation.