-
-
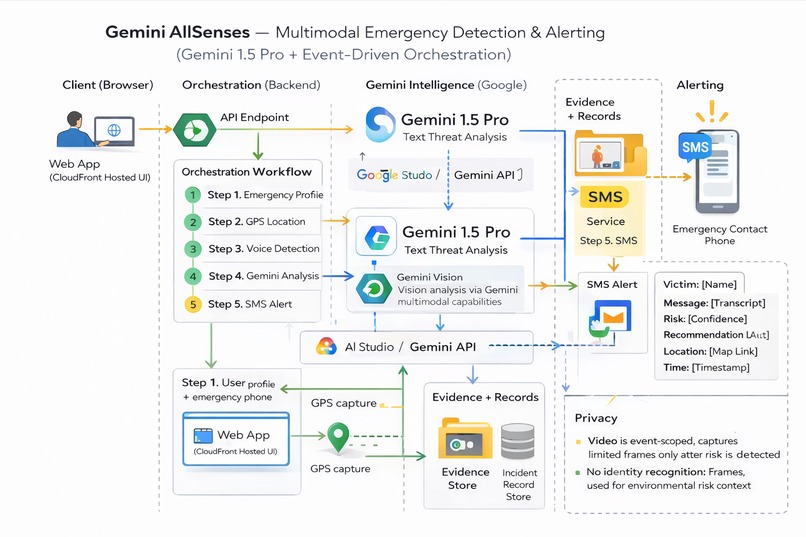
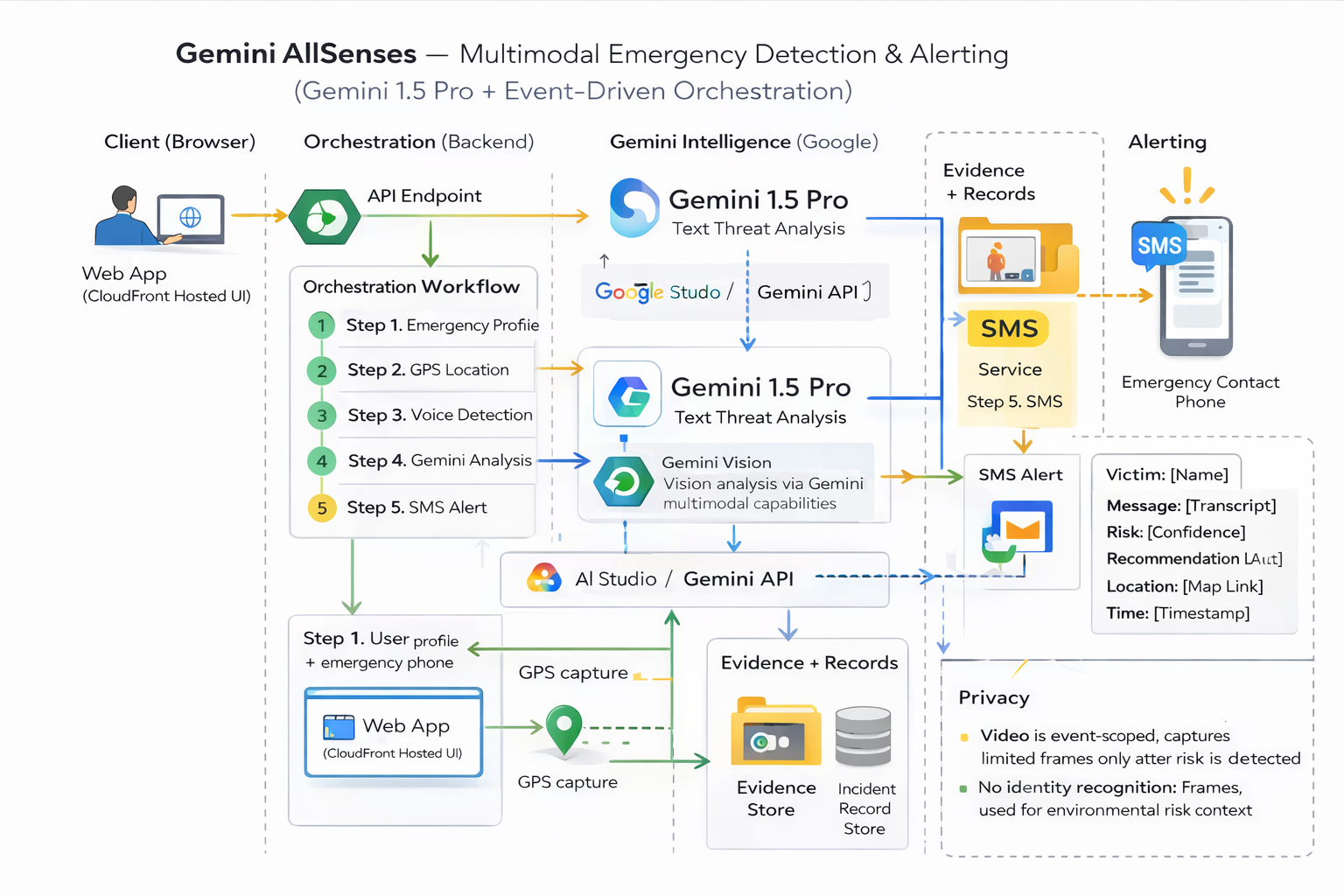
Gemini AllSenses: multimodal emergency detection—profile, GPS, voice, Gemini AI analysis, SMS alerts with full incident context
Inspiration
Personal safety rarely fails because danger is invisible — it fails because
signals are fragmented, subtle, and easy to miss.
In real emergencies, distress may surface as a short message, a change in voice tone, an unexpected sound, or a fleeting visual cue captured at the wrong moment. Often, the person at risk cannot safely speak, type, or interact with an app at all.
Through earlier explorations of safety-focused AI systems, we identified a recurring design gap:
The moments of highest risk are often the moments when users are least able to interact.
Silence does not indicate safety. In many real-world scenarios, silence itself is a critical signal.
This reality became impossible to ignore after encountering a powerful
investigation by :contentReference[oaicite:0]{index=0}
that examined Uber’s sexual-assault problem:
https://www.nytimes.com/video/business/100000010323329/ubers-sexual-assault-problem.html
The investigation revealed how warning signs often appeared before incidents escalated—missed signals, fragmented context, and moments where intervention could have mattered, but no system was capable of listening across all channels at once.
That article opened our minds to the scale of this problem and exposed a critical limitation of traditional, interaction-dependent safety systems.
Gemini AllSenses
Gemini AllSenses was created to address this gap by enabling AI systems to reason across multiple modalities — text, audio, and visual context — and support human safety precisely when traditional mechanisms break down.
It is designed for the moments when users cannot press a button, speak a word, or ask for help—yet are still sending signals that matter.
What it does
Gemini AllSenses is a real-time, multimodal AI guardian for human safety.
The system detects potential distress by correlating text, audio, and visual signals, instead of relying on a single trigger. It evaluates cross-modal alignment to infer situational risk using:
- Text signals — emergency keywords and abnormal message patterns
- Audio signals — non-verbal sounds and environmental anomalies
- Visual context — short, privacy-preserving video frames
Overall risk is inferred as a fusion of modality-specific evidence:
$$ \text{Risk}_{total} = f(\text{Audio}, \text{Text}, \text{Vision}) $$
Event-Scoped Video Intelligence
Video is not always on.
The visual component activates only after an emergency risk threshold is detected. When triggered, the system captures 1–3 short video frames to provide minimal contextual evidence.
These frames are analyzed exclusively for environmental risk indicators, such as:
- Low visibility or darkness
- Isolation or confinement
- Abrupt movement or instability
- Disruptive environmental conditions
No biometric identification is performed. Individuals are not recognized or tracked.
This approach maximizes situational awareness while minimizing data collection and privacy risk.
How we built it
Gemini AllSenses was rebuilt from the ground up using a Gemini-first, multimodal architecture, optimized for event-driven safety reasoning rather than passive monitoring.
Key design principles:
Multimodal fusion over single triggers
Each modality contributes partial evidence; risk is inferred from alignment, not isolation.Explainability by design
Each safety assessment includes structured reasoning, confidence levels, and modality-specific findings.Minimal and proportional data capture
Video frames are captured only when risk is detected and only in the smallest form needed.Human-in-the-loop orientation
Outputs are designed to assist trusted contacts or responders — not to automate irreversible actions.
The system leverages Gemini 3 for multimodal reasoning and produces structured outputs suitable for downstream alerts and notifications.
Challenges we ran into
Balancing safety with privacy
We had to design a video system that provides meaningful context without continuous monitoring or identity recognition.Multimodal alignment complexity
Combining partial, asynchronous signals from text, audio, and vision required careful orchestration to avoid false positives.Latency and reliability
Emergency systems must respond quickly and consistently, even when some signals are missing or degraded.Explainability requirements
Safety decisions must be transparent and understandable, not opaque model outputs.
Accomplishments that we're proud of
- Built a fully multimodal safety system using Gemini 3
- Designed event-scoped video intelligence instead of always-on surveillance
- Achieved explainable, confidence-aware safety assessments
- Maintained a privacy-first architecture while increasing situational clarity
- Delivered a working, end-to-end prototype suitable for real-world safety scenarios
What we learned
- Silence is often the strongest safety signal
- Multimodal reasoning dramatically reduces false assumptions compared to single-signal systems
- Video is most valuable when used sparingly and intentionally
- Explainability is essential for trust in safety-critical AI
- AI safety systems must support humans, not replace judgment
What's next for Gemini AllSenses — multimodal AI guardian for human safety
Next steps include:
- Expanding multimodal confidence calibration
- Improving robustness across diverse environments
- Enhancing responsible alerting workflows for trusted contacts
- Further refining privacy guarantees and data minimization
- Exploring additional real-world safety use cases where user interaction is limited
Gemini AllSenses demonstrates how multimodal AI can support human safety when people cannot speak for themselves.
Built With
- ai-safety
- amazon-dynamodb
- amazon-sns
- api-gemini
- artificial-intelligence
- aws-cloudformation
- aws-lambda
- cloud-computing
- event-driven-architecture
- expplainable-ai
- google-gemini
- multimodal-api
- python
- rest-api

Log in or sign up for Devpost to join the conversation.