-
-
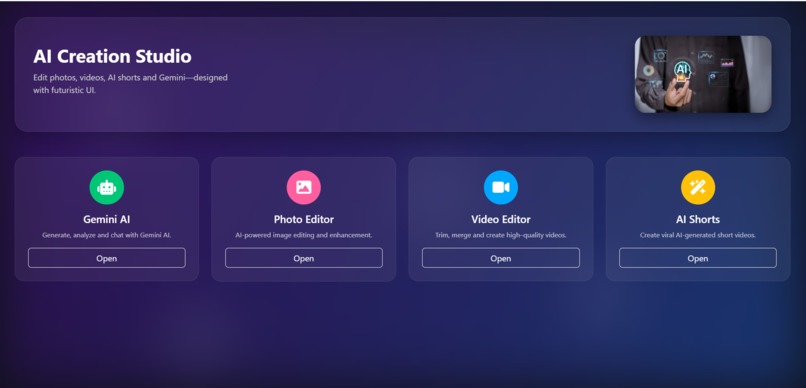
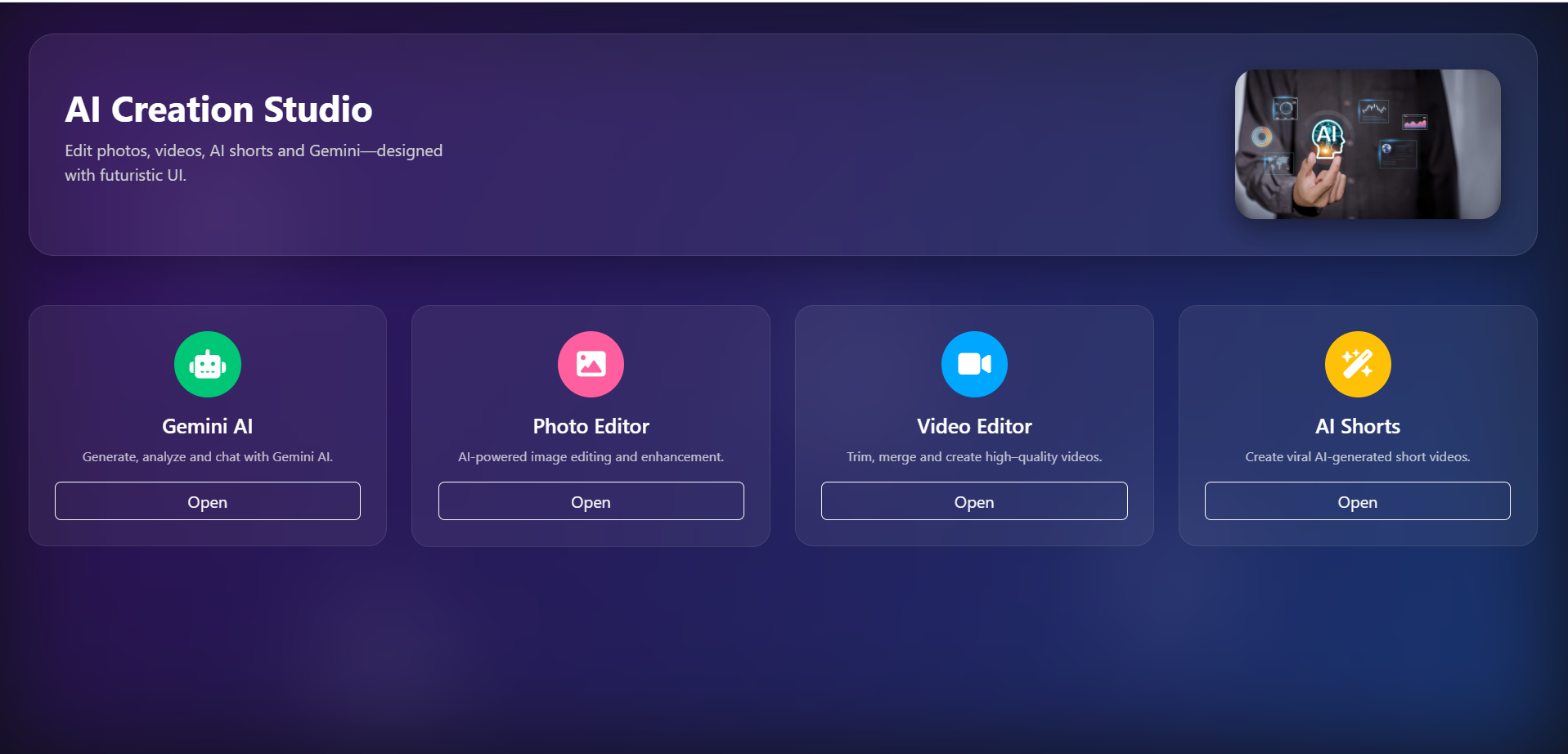
main Dashbord
-
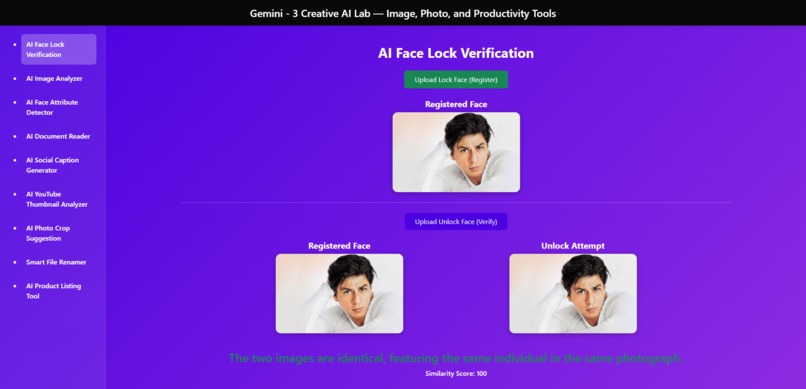
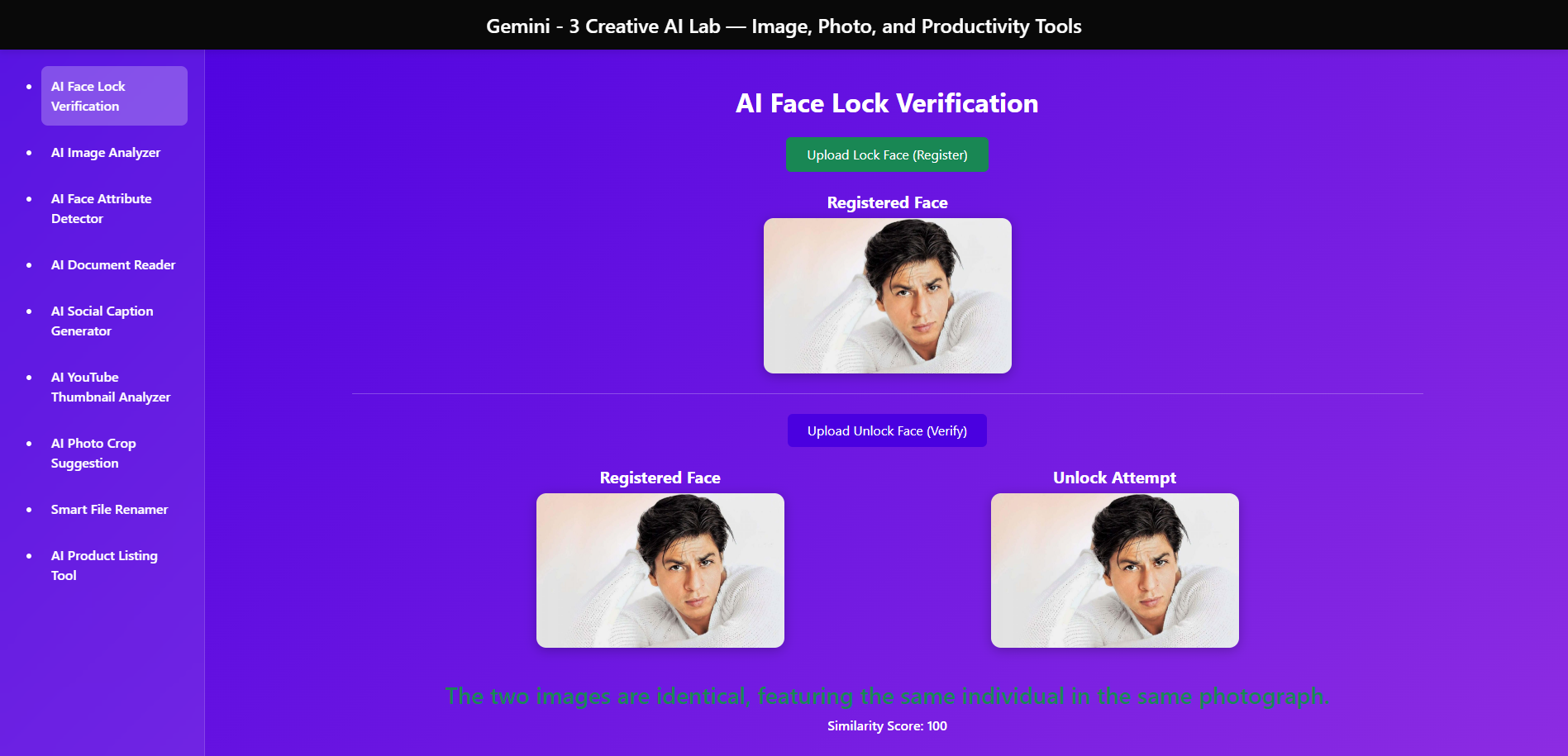
Face Lock
Inspiration
I wanted to build a single platform that shows the real power of Gemini 3—its ability to understand images, documents, faces, and text in one unified model. Most AI apps focus on only one feature, so I decided to create an all-in-one toolkit demonstrating practical, everyday use cases.
What it does
This project is a multi-tool AI productivity suite powered entirely by Gemini 3. It includes:
AI Face Lock Verification – compare two faces with high accuracy
AI Image Analyzer – detect objects, scenes, and insights
AI Face Attribute Detector – extract age, gender, emotions, expressions
AI Document Reader – read PDFs/images and summarize content
AI Social Caption Generator – create captions for posts
AI YouTube Thumbnail Analyzer – analyze thumbnails for engagement
AI Photo Crop Suggestion – suggest smart crop regions
Smart File Renamer – auto-rename files based on content
AI Product Listing Tool – generate product titles, tags, and descriptions
All tools run through a clean Angular UI and a Node.js backend using the Gemini 3 API.
How we built it
Angular frontend for modular UI
Node.js/Express for API routing
Gemini 3 Flash & Pro models for vision, reasoning, and generation
MySQL for user and history storage
Cloud hosting for both frontend and backend Each tool calls Gemini for multimodal understanding and returns structured results to the UI.
Challenges we ran into
Handling large images and base64 conversions efficiently
Optimizing latency with Gemini 3 multimodal
Designing a clean UI for many tools in one place
Maintaining consistency across different AI features
Deploying backend + Angular smoothly for public demo access
Accomplishments that we're proud of
Built an entire multi-tool AI platform in a short time using Gemini 3, integrating vision, text, and document intelligence into one unified product.
Achieved accurate face verification and face attribute detection with real-world images by fine-tuning prompt engineering and preprocessing.
Designed a clean, fast, and responsive UI in Angular that makes switching between 8+ AI tools seamless.
Successfully integrated multiple Gemini 3 endpoints (Flash + Pro) for image understanding, content generation, and complex reasoning.
Overcame technical challenges like handling large image uploads, converting base64 data, optimizing API latency, and stabilizing the Node.js backend.
Created complete, production-ready workflows for image analysis, document reading, caption generation, product listing creation, and more.
Built a tool that is genuinely useful for creators, businesses, students, and developers — not just a demo.
Achieved smooth deployment of both frontend and backend, making the project public, accessible, and easy for judges to test.
Showcased versatile use cases of Gemini 3 that go beyond chat, proving how powerful multimodal reasoning can be in real applications.
What we learned
How to integrate Gemini 3’s multimodal capabilities deeply
Efficient image preprocessing
How to structure scalable endpoints for AI tools
Improving UX for AI-based apps
Building a multi-AI feature product fast using modern frameworks
What's next for Gemini 3 Productivity Toolkit
Adding speech-based tools
Adding real-time video analysis
Expanding face verification use cases
Adding user authentication & saved AI history
Turning the suite into a full developer API


Log in or sign up for Devpost to join the conversation.