Inspiration
We live in a world of complex visual data—from circuit diagrams to security feeds. Standard AI tools can "see" objects, but they struggle to reason about them. I wanted to bridge the gap between simple computer vision and deep logical understanding. My goal was to build an agent that acts like an expert consultant: one that verifies its own logic, understands video context, and provides accessible audio feedback.
What it does
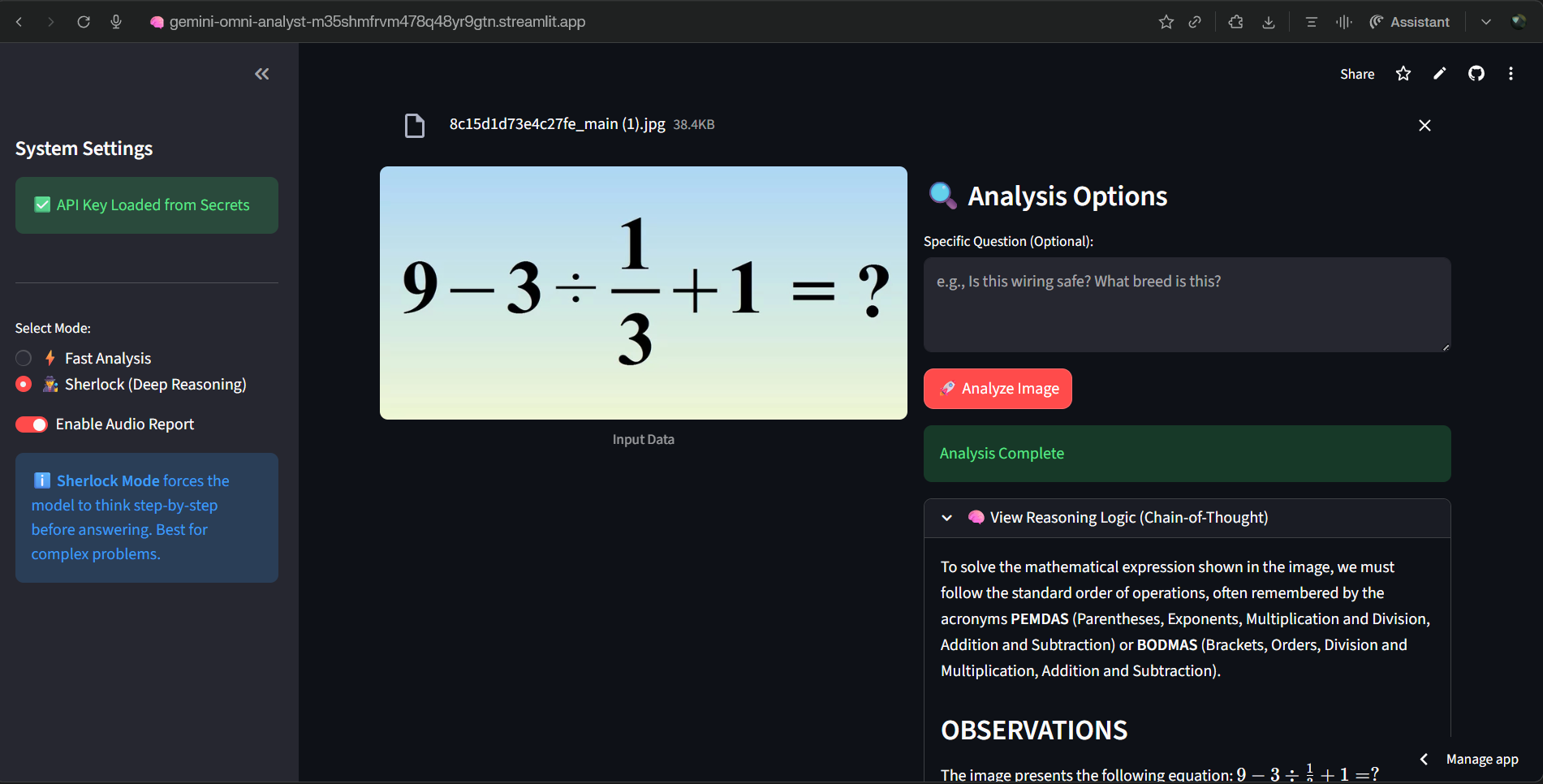
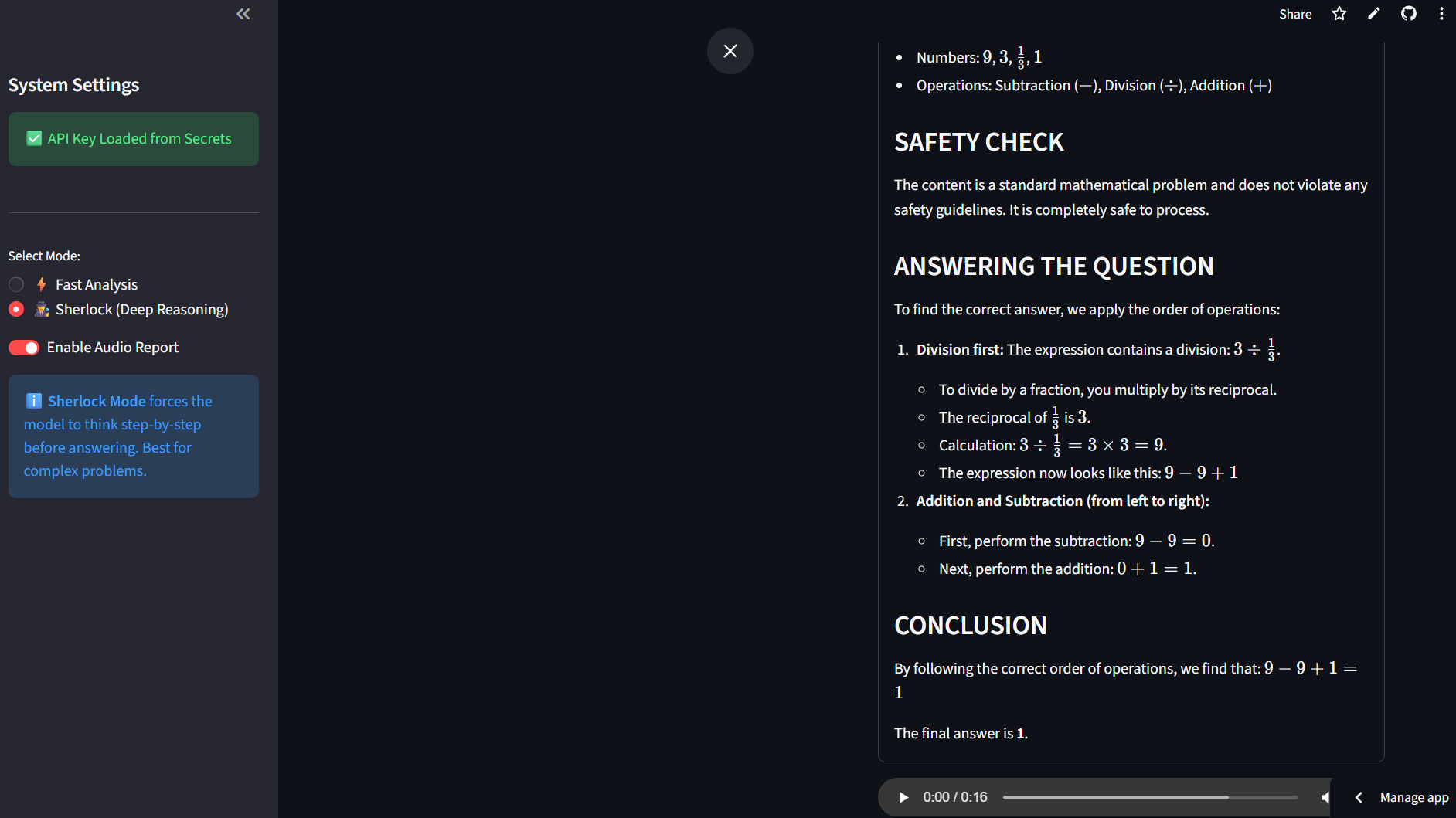
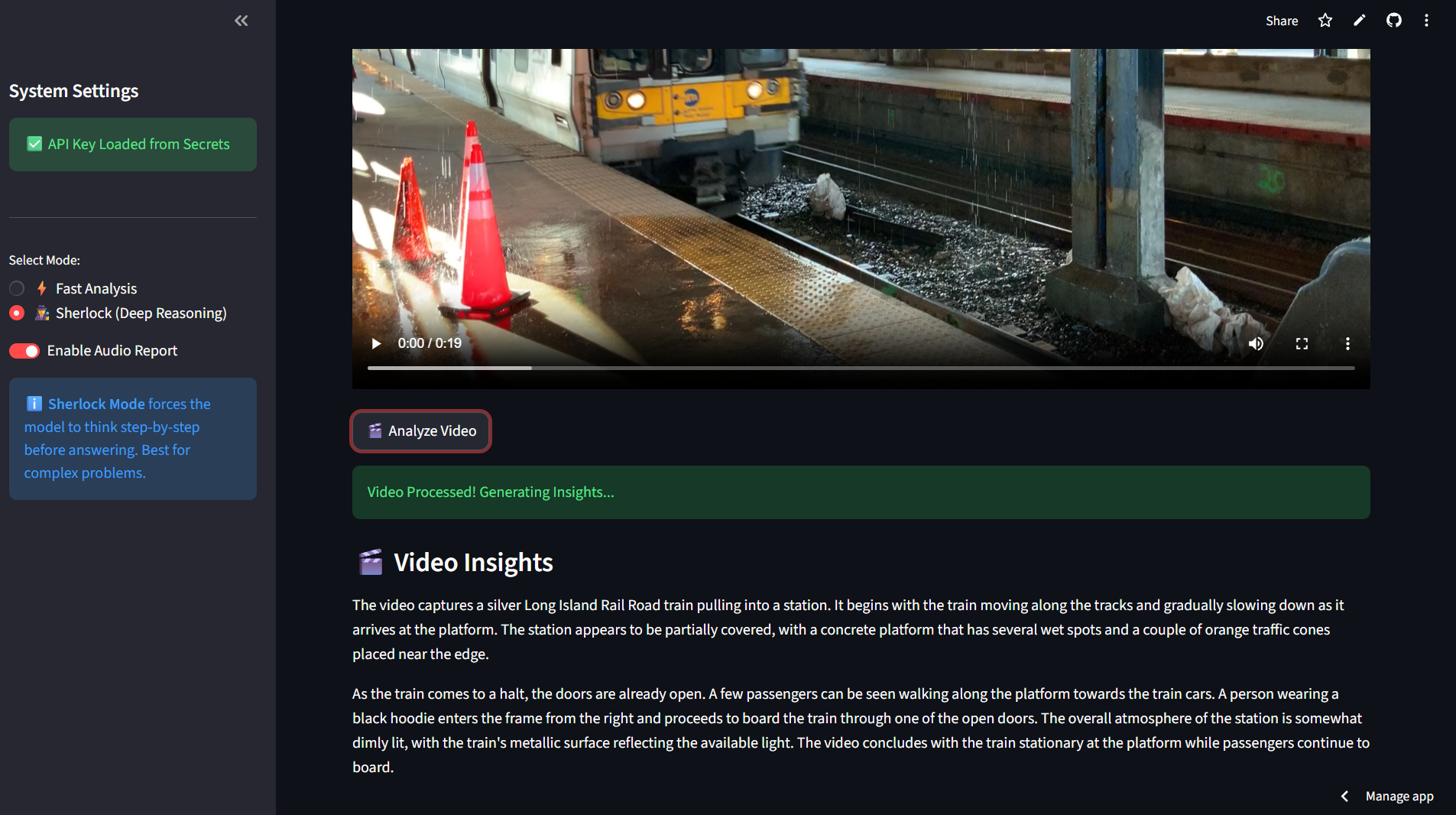
Gemini Omni-Analyst is a multimodel intelligence engine that processes images and video streams to provide deep insights. Sherlock Mode (Chain-of-Thought): Unlike standard chat bots, this mode forces the model to "think before it speaks." It breaks down complex images into observations, safety checks, and logical steps before generating a final answer, drastically reducing hallucinations. Video Stream Understanding:It goes beyond static pixels by analyzing video files to understand motion, temporal context, and evolving events. Hands-Free Accessibility:The app automatically generates audio reports using text-to-speech, making complex data accessible to users in hands-busy environments.
How we built it
I built the application using Python and Streamlit for the frontend interface.
The Brain: The core is powered by Google's Gemini 1.5 Pro / Gemini 3 models via the google-generativeai SDK.
The Logic: I implemented a custom prompt engineering architecture that injects "reasoning constraints" into the model, forcing it to output a structured internal monologue (the "Sherlock" feature) before the final response.
The Senses: I used Pillow for image processing and gTTS (Google Text-to-Speech) to convert the AI's insights into spoken audio files on the fly.
Challenges we ran into
The biggest challenge was handling Multimodal State Management. Streamlit re-runs the entire script on every interaction, so maintaining the "memory" of the uploaded video and the AI's previous reasoning steps required careful session state management. I also faced API quota limits when testing the advanced video reasoning, which forced me to optimize the token usage and implement robust error handling (as seen in my demo!).
Accomplishments that I'm proud of
I am most proud of the "Sherlock Mode." Seeing the AI actually correct itself during its internal reasoning process—catching safety risks in a wiring diagram that a standard model might have missedwas a breakthrough moment. I'm also proud of going from a local Python script to a fully deployed cloud application in just one hackathon sprint.
What we learned
I learned that Prompt Engineering is actually Logic Engineering. You can't just ask an AI to "be smart"; you have to structure its thinking process. I also mastered the importance of securely managing API keys using secrets, ensuring my code on GitHub remained clean and safe.
What's next for Gemini 3: Omni-Analyst
The next step is Real-Time Webcam Analysis. I want to enable a "Live Mode" where the AI watches a camera feed and calls out safety hazards or instructions in real-time. I also plan to add PDF/Document support to make it a truly "Omni" analyst for any type of data.
Built With
- generative-ai
- google-gemini-api
- gtts
- python
- streamlit



Log in or sign up for Devpost to join the conversation.