-
-
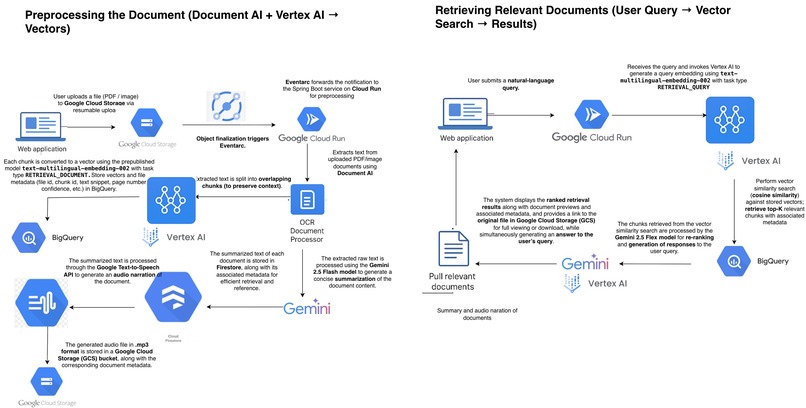
Architectural Diagram

Inspiration
In today’s digital-first world, individuals and organizations store countless documents—certificates, passports, medical records, contracts, and more—across cloud drives, emails, and local folders. While storage is easy, finding the right document at the right time remains a major challenge.
What it does
The AI-Powered Personal Document Assistance System allows users to securely upload private documents (PDFs and images) and later retrieve relevant content using natural language queries ,with summarization and audio narration.
How we built it
Built entirely on Google Cloud Platform (GCP), the system leverages **Document AI, Vertex AI, Gemini-2.5-flash Model, Cloud Run, Firestore, Text-to-Speech API and BigQuery **to perform intelligent text extraction, embedding, and retrieval through vector similarity search, re-ranking of chucks, Summarization and audio narration.
This architecture ensures data privacy, scalability, and multilingual adaptability by leveraging Google’s advanced AI models and server-less infrastructure.
Challenges we ran into
1) One of the key challenges was designing the event-driven architecture that connects the entire pipeline - from the document upload web application, to the Google Cloud Storage bucket, through EventArc triggers, and finally to Spring Boot microservices deployed on Cloud Run ** for document processing. The microservice extracts text using **Document Al OCR, performs context-preserving chunking with overlaps, and passes each chunk to the pretrained text-multilingual- embedding model for vector generation. and passing raw text to Gemini-2.5-flash model for summary, Text-to-speech to audio narration EventArc internally uses Pub/Sub for event transportation. When an event is published, the subscriber (Cloud Run service) is expected to acknowledge it within roughly 10 seconds. If no acknowledgment is received, Pub/Sub retries the event, which initially caused duplicate processing for the same document.
To solve this, we implementeda deduplication mechanism based on the Cloud Event ID (ce-id) found in the event header. Since EventArc assigns a unique ce-id per event, even during retries, each incoming request's ID was stored in Firestore. If a retry with the same ce-id appeared, the system detected it as a duplicate and returned a success response immediately, preventing redundant document processing.
2) While using the Document Al (Document OCR Processor) Inference API to extract raw text from PDFs, I discovered that each API call can process only up to 15 pages at a time. For larger PDFs, this required splitting the document into batches of 15 pages per request and then merging the extracted text results. To automate this, I used the iTextPDF API to split PDFs efficiently into 15-page chunks before processing.
3) While working with the pre-published Vertex Al model text-multilingual-embedding, I encountered a request limit of 20,000 tokens per API call. To handle this efficiently, the raw text extracted from documents via Document OCR was divided into chunks of up to ** 1,024 characters, with a 200-character overlap to preserve context.** Each API request processed 50 such chunks, ensuring we stayed within the token limit while maintaining contextual accuracy.
4) Storing the vector embeddings generated for each text chunk in BigQuery's vector-supported tables and implementing cosine similarity queries to perform efficient semantic searches.
5) .We implemented a resumable upload for large files to a GCS bucket. Initially attempting a direct client-side JavaScript implementation, we encountered Cross-Origin Resource Sharing (CORS) issues. The solution involved a hybrid approach: a Spring Boot backend service securely acquired the session URL (the upload URL), and the frontend then chunked the file data, sending 5 MB segments sequentially to this URL. We managed the upload flow by handling the 308 (Incomplete) and 200 (Success) response codes to ensure successful completion.
6)Integrating with Gemini-2.5-flash model for re-ranking ,Answer the user queries and Google Text-to-Speech AP for audio narration.
Accomplishments that we're proud of
Delivered a complete, end-to-end application built on an event-driven architecture, fulfilling the initial design vision. *The system provides fast and highly accurate retrieval of relevant documents from natural language queries, resulting in significant time savings for both individuals and organizations. *
What we learned
1)Designing and implementing event-driven architectures utilizing various Google Cloud services Cloud RUN. 2)Developing and integrating a Retrieval-Augmented Generation (RAG) model pipeline. 3)Using Java client libraries to interface with Google Cloud AI/ML APIs. 4)Implementing Single Sign-On (SSO) for secure user authentication. 5)Mastering cosine distance for performing highly effective semantic/similarity search. 6)Deploying containerized applications efficiently on Google Cloud Run. 7)Managing and querying vector data and file metadata using Google BigQuery's vector support capabilities."
What's next for GCP-AI Document Intelligence System
Secure User Collaboration: Implement a document sharing mechanism to foster secure knowledge exchange between users. Broader File Support: Increase the utility of the system by rapidly adding support for additional document types beyond PDFs and images." Interactive Chat Interface on Particular document
Built With
- artifact-repository
- cloud-build
- cloudrun
- docker
- documentai(ocr)
- eventarc
- firestore
- gemini-2.5-flash
- google-bigquery
- google-cloud
- google-oauth2.0
- html5
- java
- javascript
- springboot
- text-multilingual-embedding-model
- text-to-speech
- tymeleaf
- vertexai



Log in or sign up for Devpost to join the conversation.