-
Gaze: Homepage
-
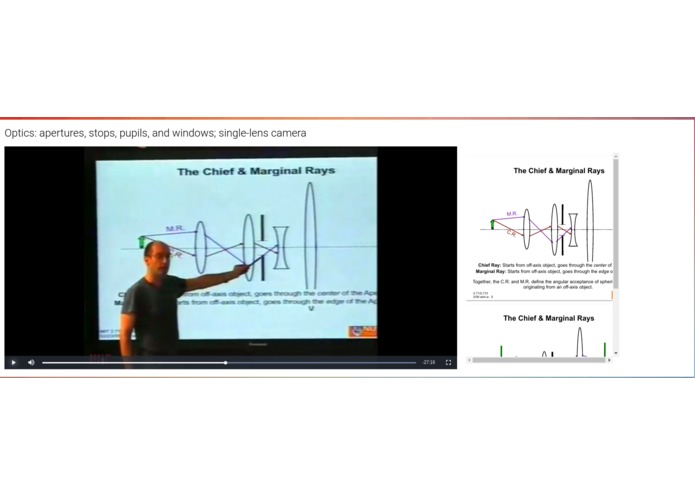
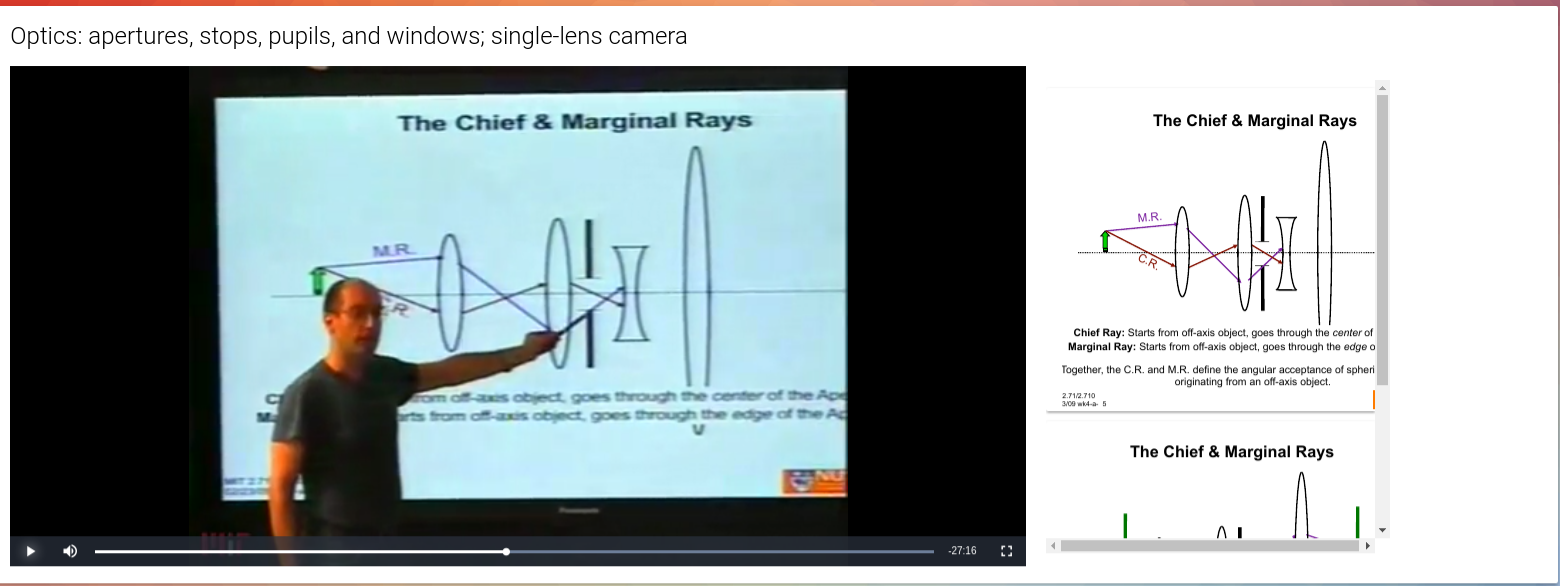
Searching educational lectures by locating timestamps for corresponding lecture slides
-

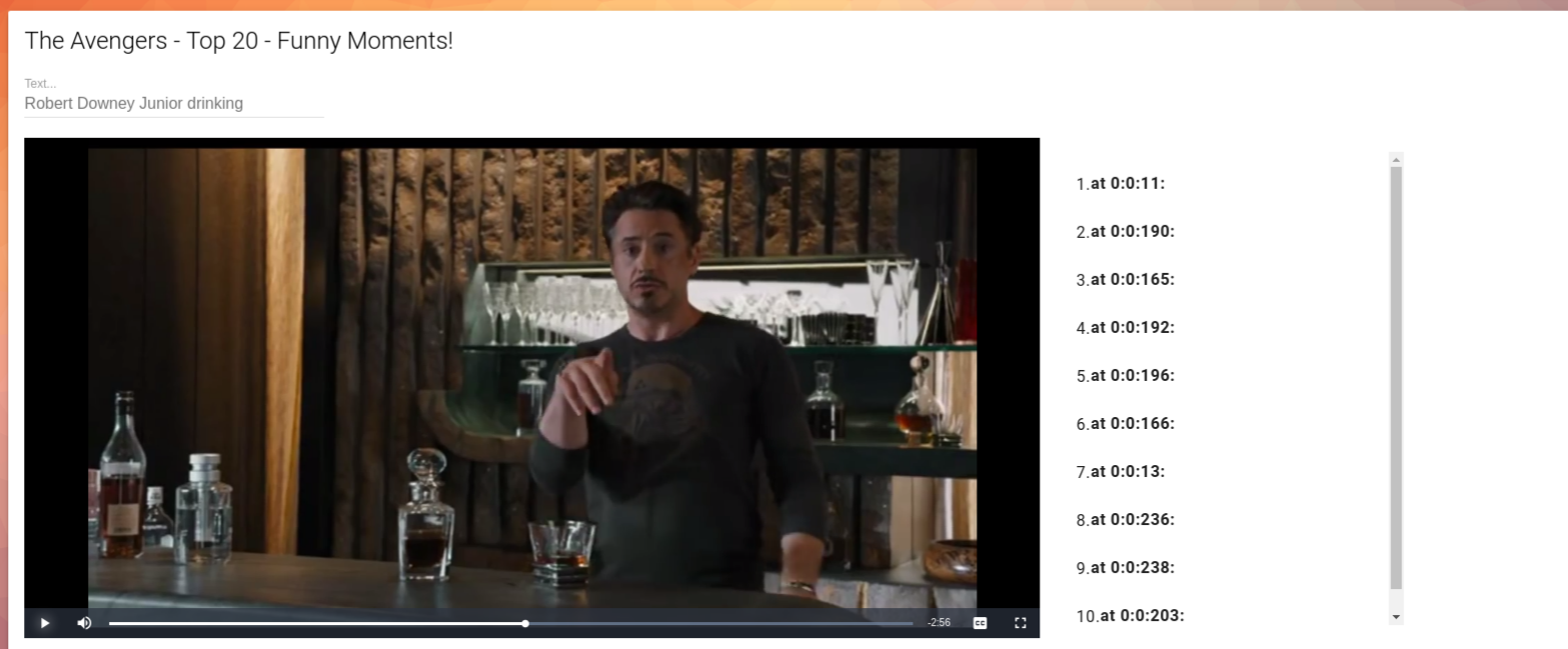
Search audio content and subtitles by specific inputted text queries
-
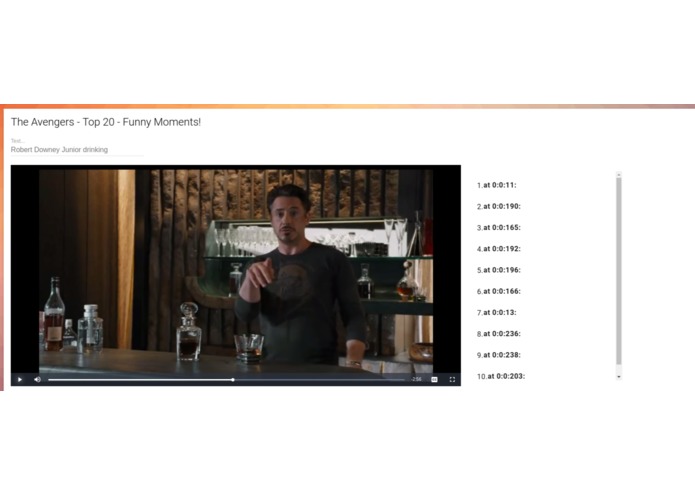
Searching a video for a specific scene: "Robert Downey Junior drinking". Timestamps for matching scenes are displayed.
-
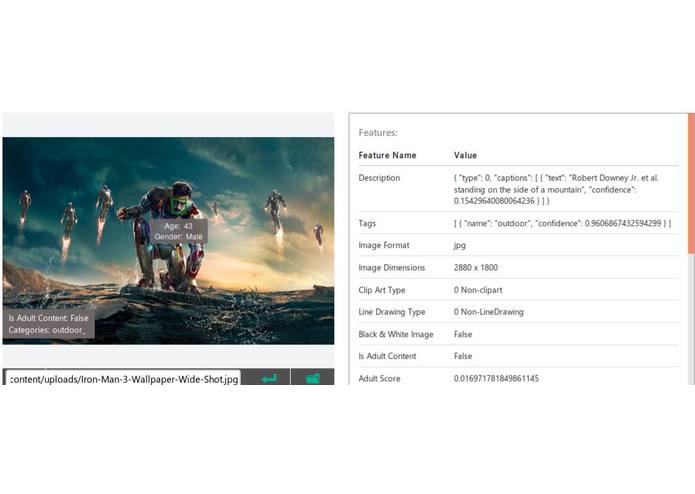
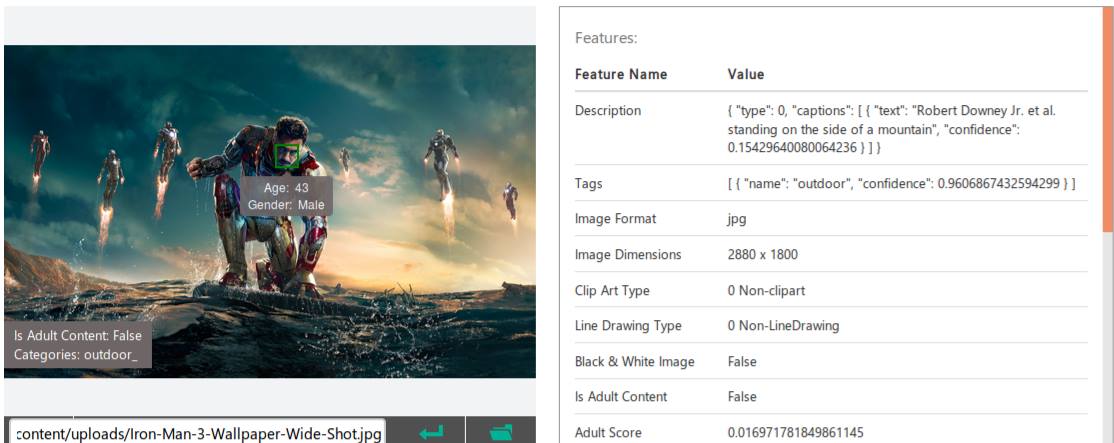
"Behind the scenes": Scene screenshot analysis done through Microsoft's Cognitive Services
-
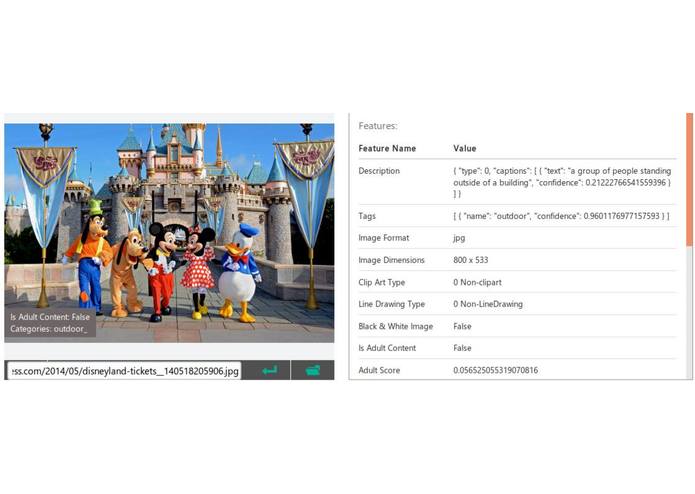
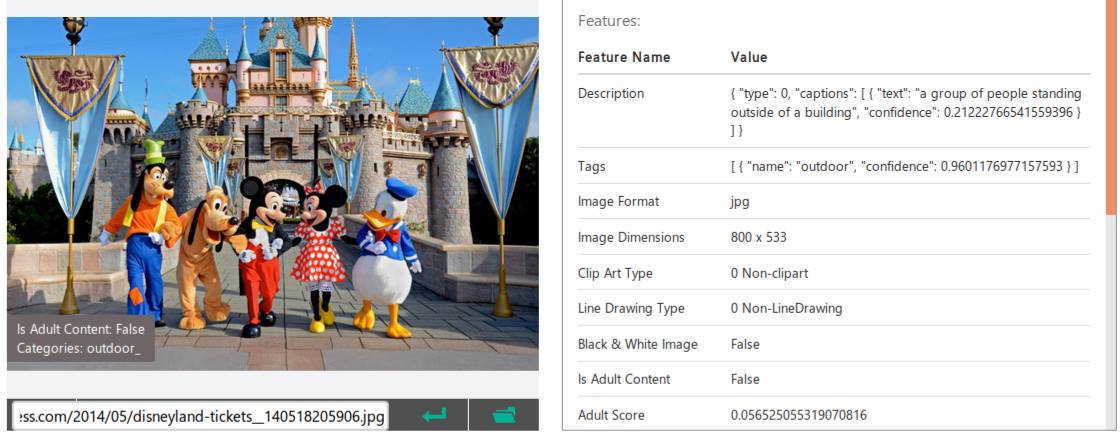
"Behind the scenes": Scene screenshot analysis done through Microsoft's Cognitive Services
-
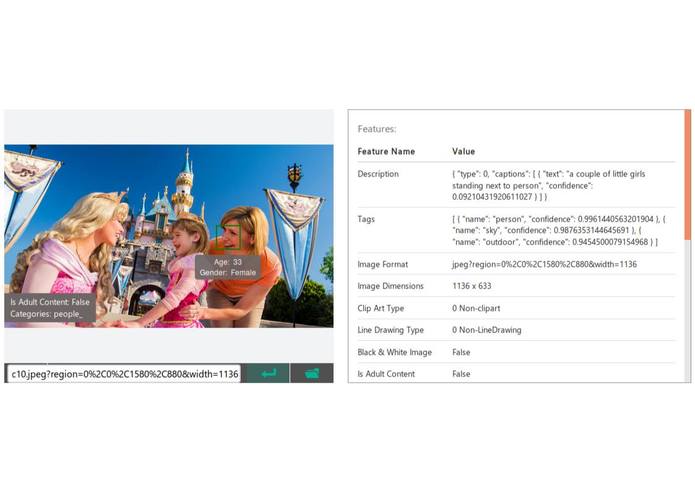
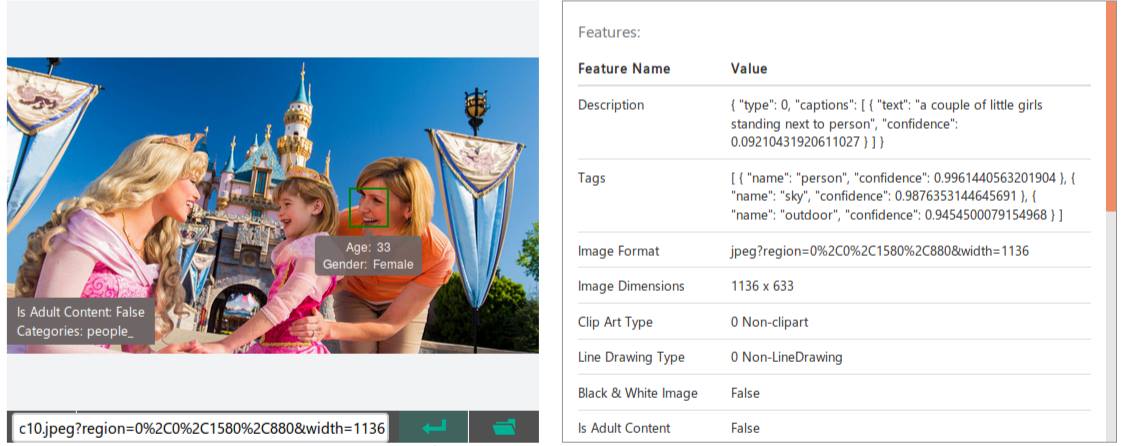
"Behind the scenes": Scene screenshot analysis done through Microsoft's Cognitive Services
-

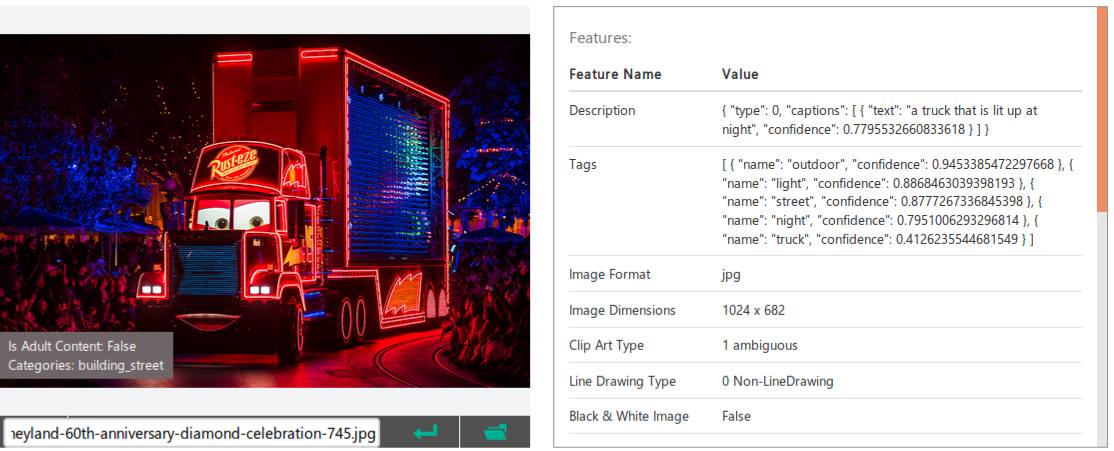
"Behind the scenes": Scene screenshot analysis done through Microsoft's Cognitive Services


Inspiration
Deep learning as a tool can have a huge impact in the media industry. With visual and audio content taking over 70% of the internet, people often struggle with navigating through un-organized media content. Our goal is to transform cluttered video content into a simplified and streamlined navigating experience.
What it does
Gaze organizes un-organized videos to help the user interpret and navigate visual information. It allows the user to 1) search video content by specific inputted text queries, 2) search educational lectures by locating timestamps for corresponding lecture slides 3) search audio content and subtitles by specific inputted text queries.
How We Built It
First, we split the video into smaller scenes by creating an average brightness histogram and calculating entropy. Scenes were distinguished and determined by substantially different histogram and entropy results. Once scenes were separated, we sent two frames from each scene to Microsoft's Cognitive services to get a highly contextual description of the scene. Iterating through each description and clustering keywords into a giant bucket, we were able to provide the users a platform to navigate through a media content with accuracy and ease.
Challenges I ran into
We were limited to a low-end CPU from Azure, so video processing time took around 50ms per frame, with around 90,000 frames per clip.
What's next for Gaze
Lots of sleep and tourism.




Log in or sign up for Devpost to join the conversation.