-
-
UI/UX
💡 Inspiración Guadalajara tiene cientos de cámaras de seguridad activas en todo momento. Sin embargo, cuando ocurre un incidente — un asalto, una pelea, una emergencia médica — el video solo se revisa después. Le llamamos autopsia digital: detallada, precisa, y completamente inútil para la prevención. El problema real no es la falta de cámaras. Las cámaras son pasivas: graban el pasado pero no pueden reaccionar al presente. Al mismo tiempo, los operadores humanos que monitorean esos feeds enfrentan fatiga visual — tras 6 horas continuas mirando 20 monitores, un parpadeo es suficiente para perder un incidente crítico. Nos preguntamos: ¿qué pasaría si pudiéramos darle un cerebro a las cámaras que ya existen?
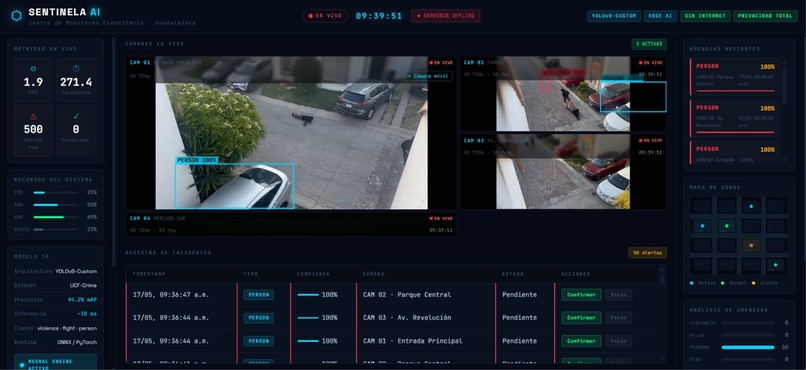
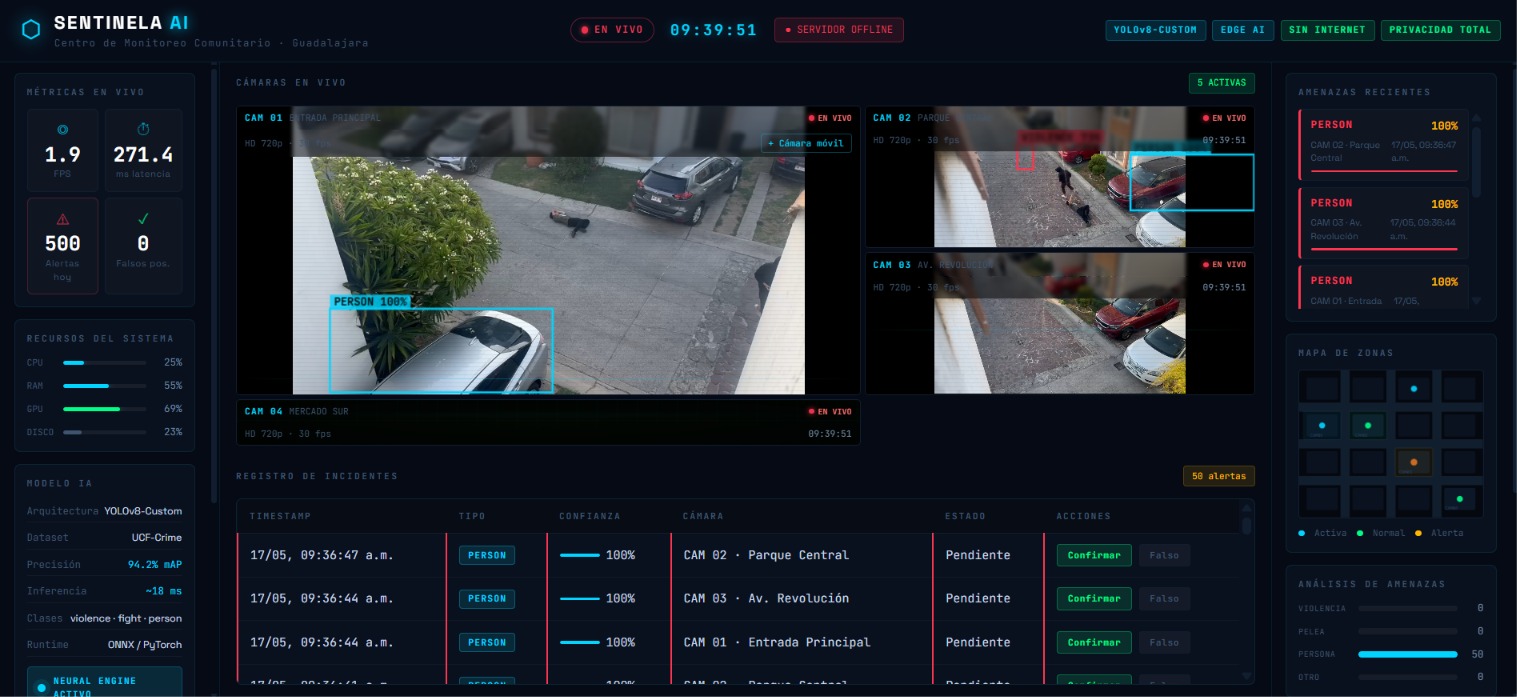
🔨 Lo que construimos Sentinel AI es un motor de inteligencia artificial local que transforma cámaras pasivas en guardianes activos. Corre completamente en hardware existente — sin cámaras nuevas, sin servidores en la nube, sin infraestructura adicional. El sistema opera en un pipeline de cinco etapas:
Ingesta de video — frames de cualquier cámara IP, webcam o stream RTSP entran a OpenCV Inferencia local — un modelo YOLOv8-Medium con fine-tuning detecta eventos de amenaza en tiempo real Motor de decisión — umbrales de confianza determinan la prioridad de la alerta Dashboard del operador — interfaz web en tiempo real con video en vivo, clip previo al incidente, mapa de ubicación exacta y cámaras cercanas Privacidad por diseño — rostros se borran automáticamente antes de guardar cualquier frame; todos los clips se eliminan después de 24 horas
Clases de eventos detectados ClaseDescripciónPrioridadweaponArma de fuego, cuchillo, objeto contundenteAltafightDos o más personas, contacto físico agresivoAltaperson_fallenPersona en el piso, posible emergencia médicaAltacrowd_suspiciousAglomeración >5 personas, movimiento erráticoMediapursuitPersecución activaAltavandalismDestrucción, objeto lanzadoMedia Umbrales de decisión
Confianza > 85% → Alerta inmediata (rojo, sonido) Confianza 60–85% → Alerta moderada (amarillo, revisión manual) Confianza < 60% → Descartado silenciosamente
Regla de oro del diseño: la IA detecta, el humano siempre decide.
⚙️ Cómo lo construimos CapaTecnologíaModelo de IAYOLOv8-Medium, fine-tuned sobre UCF-Crime datasetBackendPython 3.10 + FastAPI (async)Procesamiento de videoOpenCV 4.8 + FFmpegTiempo realWebSocket nativo de FastAPIBase de datos localSQLite con auto-borrado a las 24hDashboard del operadorHTML + Vanilla JS + Leaflet.js (OpenStreetMap)Módulo de privacidadMediaPipe detección de rostros + blur OpenCVEntrada de videoWebcam de laptop / cámara IP / MP4 pre-grabado Todo corre en una sola laptop, sin conexión a internet. La latencia total desde el frame hasta la alerta al operador es menor a 2 segundos.
🧗 Retos Entrenar un modelo justo con datos imperfectos. El UCF-Crime dataset es footage de vigilancia real que carga sus propios sesgos demográficos. Medimos explícitamente la variación en tasa de detección por género y condiciones de iluminación, y fijamos una diferencia máxima aceptable del 3% entre grupos. Equilibrar sensibilidad contra falsos positivos. Un sistema que genera alarmas falsas constantemente destruye la confianza del operador muy rápido. Implementamos un cooldown de 2 minutos por cámara y tipo de evento, y los tres niveles de umbral en lugar de un trigger binario. Nuestro objetivo: menos del 5% de falsas alarmas en un turno de 8 horas. Privacidad como restricción dura, no como ocurrencia tardía. Decidimos desde el inicio que los rostros nunca se guardarían — ni temporalmente. El paso de anonimización corre dentro del pipeline antes de que cualquier frame llegue a la base de datos, lo que añade complejidad arquitectónica pero hace la garantía de privacidad incondicional. Demo en vivo bajo presión. Una inferencia de YOLOv8 en directo puede fallar silenciosamente si el modelo no dispara en el momento indicado. Construimos un simulate_camera.py de respaldo que reproduce un video pre-grabado de incidente, desacoplando el éxito del demo del rendimiento en vivo del modelo.
📚 Lo que aprendimos
El fine-tuning por dominio importa mucho. Nuestro modelo entrenado sobre footage de vigilancia supera con margen al checkpoint genérico de YOLOv8 para esta tarea específica. El UCF-Crime dataset fue la clave. Edge AI no es una limitación — es una ventaja. Procesar localmente da menor latencia, privacidad más sólida y despliegue posible en zonas sin internet confiable. El humano en el loop es técnicamente más inteligente. Cada acción del operador — confirmación o descarte de falso positivo con su causa — se convierte en dato etiquetado que mejora el modelo. El loop de retroalimentación se compone con el tiempo. Diseñar para el operador, no para el demo. La jerarquía visual del dashboard — alertas grandes y prominentes, grid de cámaras secundario — viene de pensar en la carga cognitiva durante un turno real de seguridad, no durante 5 minutos de presentación.
🚀 Lo que sigue La arquitectura escala linealmente: una laptop maneja 2–3 cámaras; un servidor mid-range maneja una ciudad completa. El mismo software, el mismo modelo, las mismas restricciones éticas — solo más instancias corriendo en paralelo. El costo de añadir inteligencia a una red de cámaras existente se aproxima a cero.
El futuro de la seguridad pública no es gastar millones instalando más cámaras. Es darle un cerebro a las mil millones de cámaras que ya tenemos.



Log in or sign up for Devpost to join the conversation.