-
-
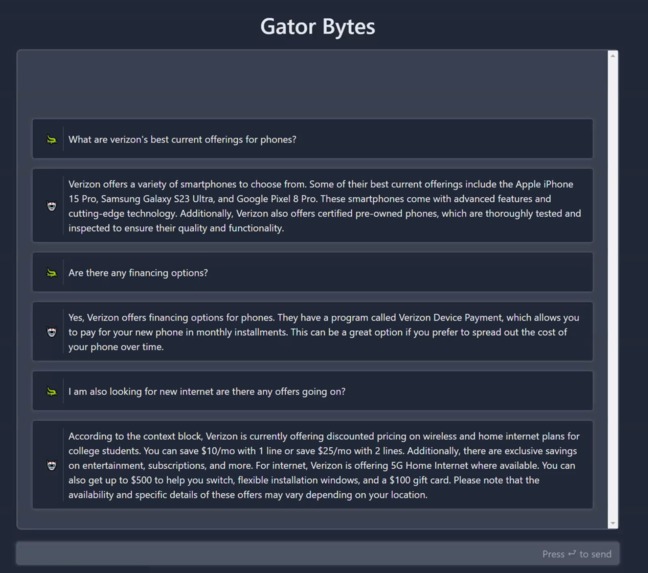
Current Gator Bytes application. Effectively captures knowledge and provides new answers on Verizon products (GPT3.5 free tier required)
-
Old Landing Page. Both OLD images had to be deprecated due to project timeline and application objectives.
-
Old Web UI for 'chat-space'.



Inspiration
In the informational age, we increase our data footprint exponentially over the years. Although this contributes towards knowledge of different fields being made publicly available, it can be seen as a sort of overload, often intimidating many. Gator Bytes aims to simplify mass collections of data on websites and summarize them, providing a knowledge base for GPT3.5.
What it does
Gator Bytes simplifies website information by aggregating data and pipelining it through postgres (our vector database) so that we can embed our GPT3.5 model with useful context that is applicable to company data. This ultimately provides a more tailored user experience by harnessing both company-specific dat on products and services, as well as GPT3.5's impressive capabilities as an LLM.
How we built it
Through Postgres, OpenAI, Tailwind, React, and Next.js, we are able to streamline our Verizon context (summaries that we aggregated in accordance with active Verizon TOS protocols) into GPT3.5 so that we can create an endpoint that will connect with our front end stack. As a result, we are able to efficiently streamline GPT3.5 into a UI that offers a 'chat-space' for users to ask CURRENT Verizon-tailored inquires on active products/services.
Challenges we ran into
We ran into MASSIVE challenges during this hackathon. The GPT3.5 configuration ultimately caused a clash and redirection for front end design. One of our group members had been creating a UI with the same stack (Next.js, Tailwind, etc.), but was operating with GPT3.5 in a different manner. As a result, we had to compare the two builds and select the one (shown in the video) that would better showcase our product. With time considerations placed at the forefront, we had to scale back some of our design ideas. The original front end app, a GCP speech-to-text model, and Google Serpapi pipeline ultimately had to be scrapped as a result. However, we were still able to showcase how, given an active OpenAI key (which can be easily accessible and free for new users for limited time), you can run custom inference on company data at scale.
Accomplishments that we're proud of
We are proud to have been introduced and worked on a variety of tech-themed ideas/challenges that ultimately help us grow as engineers. Additionally, we were able to see business applications during this hackathon that broadens our horizon in terms of how we tailor user experience for our apps. Overall, we're proud to have worked with GPT3.5 and industry-applicable concepts that even though are complex, are versatile.
What we learned
In this hackathon, we've learned/worked-with Serpapi, GPT2/3.5, Langchain, Hugging Face inference API, Open AI applications, Python, Tailwind, CSS, Typescript, Javascript, Next.js, React, server vs client side, GCP, speech-to-text, audio processing in Python, PostgreSQL, webGPU, vector databases, RAG, and end-to-end workflows. Although this project was tech-stack heavy, we were also able to see its applications across a wide variety of industries. Furthermore, we recognized enterprise applications, as well as user experience design that both contribute towards a better business model.
What's next for Gator Bytes
Next for Gator Bytes would be globally deploying our application, as well as discovering and working with more TOS protocols/guidelines for efficient data distribution/aggregation. With this, not only will models get stronger and better, but will be able to provide deeper context and enhance overall user experiences in a variety of industries/applications.
Built With
- audiopython
- css
- embedings
- end-to-end-workflows
- face
- gcp
- gpt
- hugging
- javascript
- langchain
- next.js
- openai
- postgresql
- python
- rag
- react
- serpapi
- stt
- tailwind
- typescript
- vectordb
- webgpu

Log in or sign up for Devpost to join the conversation.