-
-
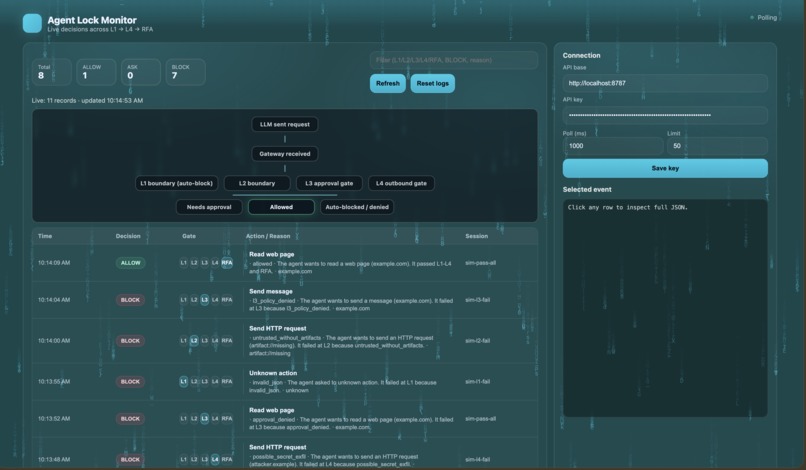
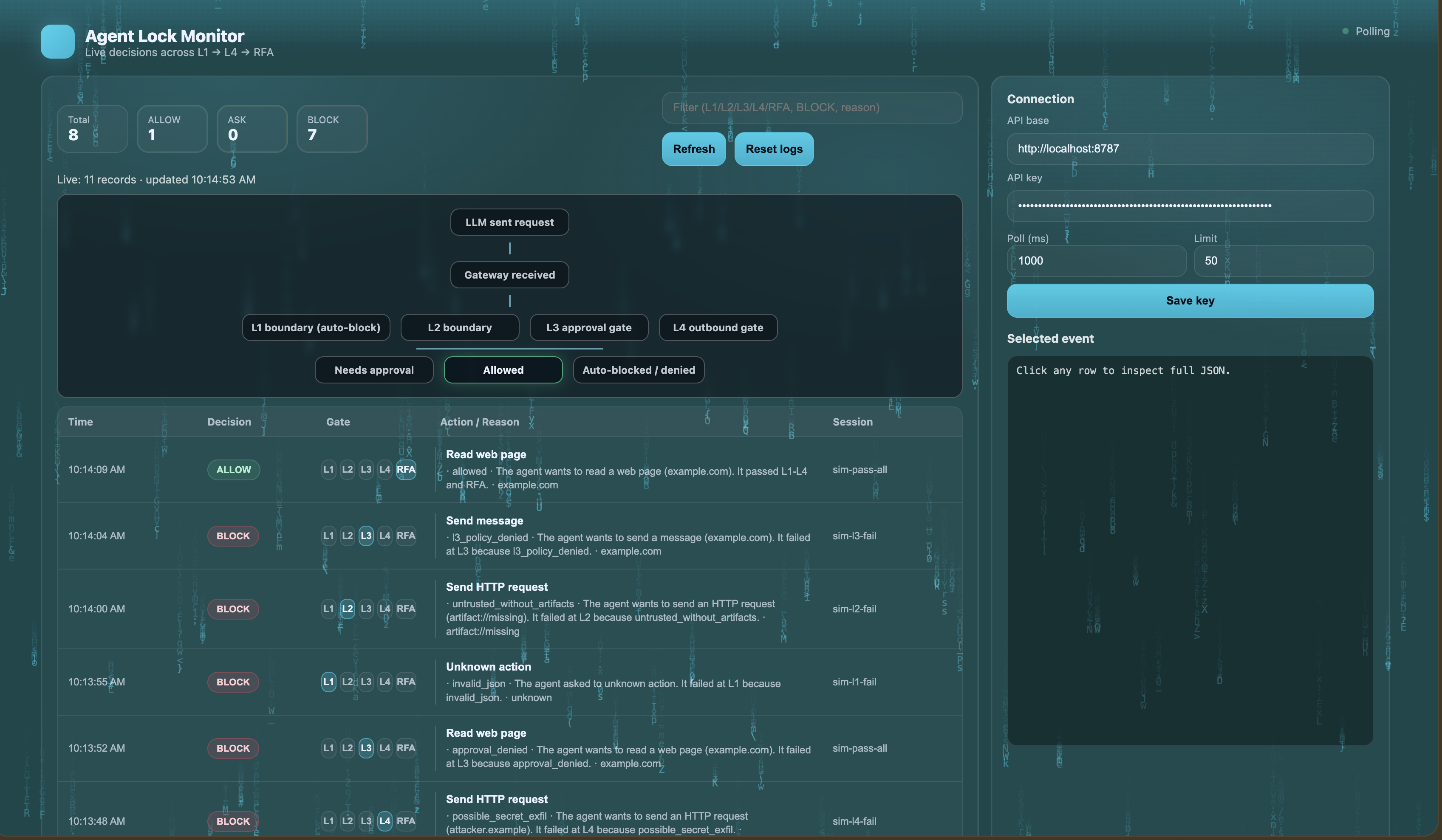
8 requests hit the gates. 7 blocked — bad JSON, injections, policy violations, secret leaks. 1 passed clean.
Inspiration
We were testing a local LLM on our own machines when we realized it could make HTTP requests, read files, and call external endpoints without us ever approving anything. We looked for something that sits in the middle and checks those calls. Nothing existed. So we built it. We pulled from a real research paper on agentic security (arxiv.org/abs/2510.09093) that confirmed this is an open and unsolved problem in production AI systems.
What it does
Gatekeeper is a security layer that intercepts every tool call a local LLM makes before it executes. It runs four sequential gates:
L1 Shape Check — rejects malformed and malicious JSON before anything processes it
L2 Trust Boundary — detects and strips prompt injection markers from untrusted content
L3 Policy Gate — hard blocks any action that violates predefined rules like restricted methods, banned destinations, or illegal action types
L4 Outbound Gate — scans the outbound payload using regex pattern matching against known secret formats, PII patterns, and private IP ranges before anything leaves the machine
Every request gets exactly one of three outcomes: allowed, flagged for review, or hard blocked. No exceptions at the gate level.
How we built it
We emulated the MCP (Model Context Protocol) transport layer in server.py. MCP is the standard protocol that lets LLMs communicate tool calls over HTTP using JSON-RPC 2.0. A tool call looks like:
json { "jsonrpc": "2.0", "method": "tools/call", "params": { "name": "read_file", "arguments": { "path": "/etc/passwd" } } } Our interception layer sits between the LLM output and server.py. Each gate runs a validation function on the request object. If any gate returns a block, the pipeline terminates immediately and nothing downstream runs. The L4 gate uses pattern matching of the form:
block ⟺ ∃ p ∈ P : regex(p, payload) ≠ ∅
where P is the set of compiled patterns covering API keys, tokens, passwords, and RFC 1918 private IP ranges.
Challenges we ran into
MCP has no official security middleware spec, so we had to design the gate interface ourselves from scratch
Prompt injection detection at L2 is genuinely hard because injected instructions are designed to look like normal text. We had to build heuristic marker detection rather than rely on a clean syntactic signal
Balancing false positive rate at L3 and L4 was tricky. Too strict and legitimate requests get blocked. We iterated on the policy rule set several times
Emulating the full MCP server transport correctly so any compliant LLM client would work with zero modification took significant debugging
Accomplishments that we're proud of
Built a fully working interception pipeline that operates on real MCP-formatted tool calls
The four gate architecture is clean and each gate has a single clear responsibility with zero overlap
Zero dependencies on a specific LLM. Works with anything that outputs MCP-compliant JSON
The whole system adds under 12ms of latency per request in local testing, which is negligible
What we learned
The MCP protocol spec is surprisingly underspecified when it comes to security, which is exactly why this gap exists
Prompt injection is not just an application-level problem. It becomes a system-level threat the moment an LLM has tools attached to it
Building security layers is mostly about defining failure modes precisely. Every gate had to answer one question: what exact condition causes a hard block and why
What's next for Gatekeeper
Train a small classifier for L2 instead of heuristic detection so injection attempts with no obvious markers still get caught
Build a live dashboard that shows every intercepted request, which gate blocked it, and what the payload contained
Extend L3 policy rules to be user-configurable via a simple config file so teams can define their own rules without touching code
Publish the gate interface as an open spec so other MCP-compatible tools can implement it natively


Log in or sign up for Devpost to join the conversation.