
🗂️ MEMO
Memory. Enterprise. Made Observable.
Team Lowkey | WeHack 2026 | CBRE Intelligent Memory Systems Challenge
Inspiration
Picture a property manager at CBRE. They've been chatting with an AI assistant all morning lease terms, compliance clauses, tenant escalation policies, building maintenance rules. The conversation is long, detailed, thorough.
Then they ask: "Can the tenant on Floor 4 sublease without approval?"
And the AI confidently says yes.
But the policy says no.
The AI didn't lie. It just forgot. The ground truth the actual lease document, the actual policy got buried too far back in the context window. So it filled the gap with a guess, and the guess sounded completely reasonable.
That's the problem. The longer the conversation, the further the AI drifts from what's actually true. In real estate, in legal, in compliance that drift is dangerous. MEMO was built to stop the drift.
What It Does
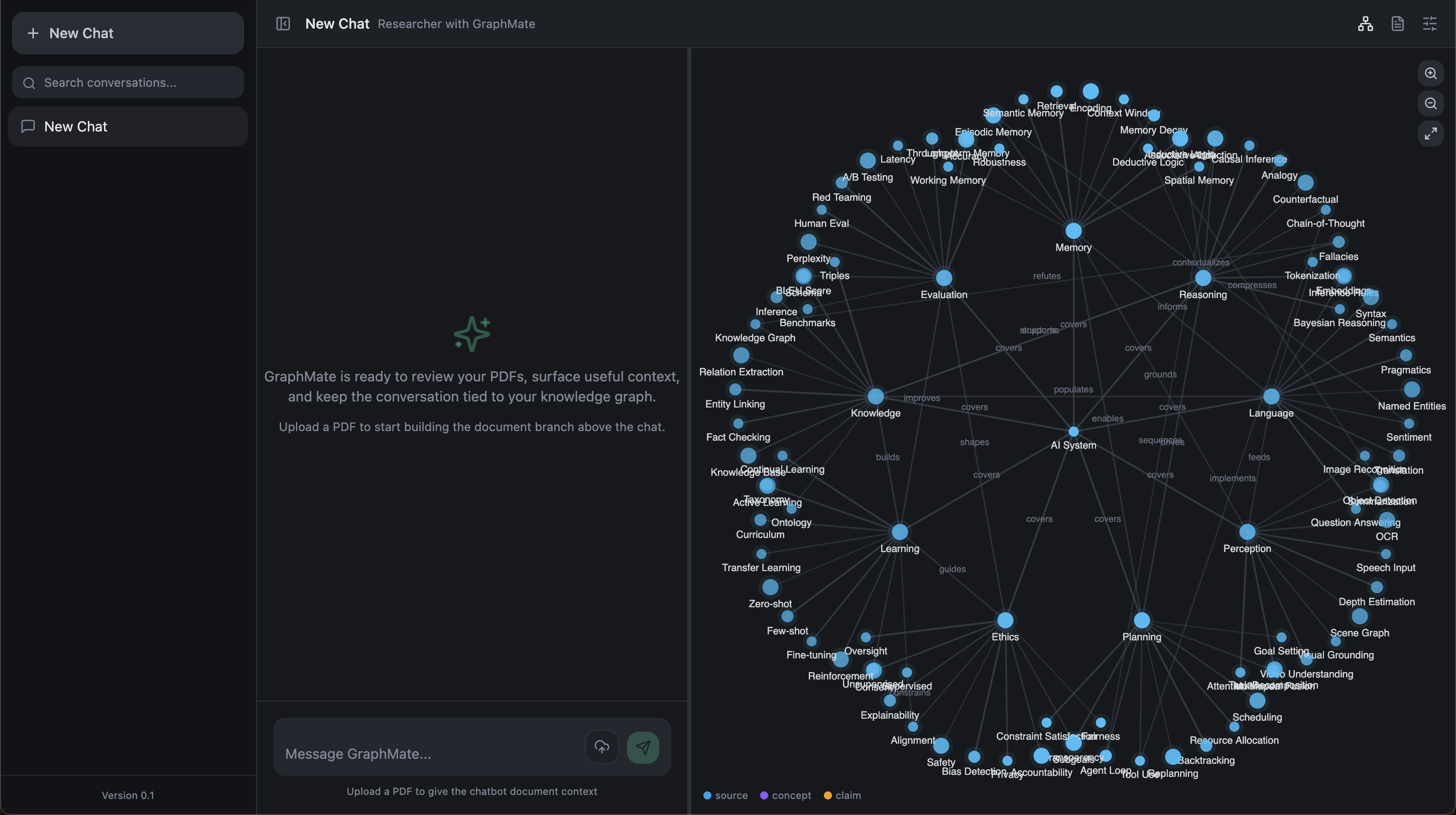
MEMO permanently extracts facts from your documents and locks them into a knowledge graph. Every time you ask a question, the AI searches that graph first pulling actual ground truth before generating any response. The context window empties. The graph doesn't.
Features:
- Upload any PDF or document - MEMO reads it, extracts every fact, and maps it into a graph of entities and relationships
- Ask questions in plain English - answers are grounded in your actual documents, not the AI's training data or memory
- Live knowledge graph - watch the graph light up as the AI pulls nodes and edges to answer your question, so you can see exactly what it's reasoning from
- Conflict detection - if two documents contradict each other (two lease versions say different things), MEMO flags it
- Entity resolution- "CBRE", "CBRE Group", and "CBRE Inc." are automatically recognized as the same entity
- Source tracing -every fact traces back to the exact document it came from, no anonymous claims
- Persistent memory - each conversation keeps its own graph that survives long sessions and page refreshes
How We Built It
Fact Extraction - When you upload a document, we send the text to Google Gemini with a structured prompt that forces atomic, clean output: identity facts ("CBRE is a real estate firm") and relation facts ("{source} requires approval from {target} for subleasing"). Compound sentences get split. Everything comes back as typed JSON no freeform text, no hallucinated structure.
Knowledge Graph - We built a custom graph database from scratch. Nodes are entities. Edges are relationships. Every fact is tagged with its source document so nothing is ever anonymous.
Entity Resolution - Every node name is embedded using nomic-ai/nomic-embed-text-v1.5 and clustered by vector similarity. Names that land within a cosine similarity threshold of $\delta = 0.85$ get merged into one node automatically.
Conflict Detection - An NLI cross-encoder (cross-encoder/nli-MiniLM2-L6-H768) runs across facts about the same entity. If two facts contradict each other across documents, the system flags the disagreement.
Retrieval Agent - A LangGraph ReAct agent powered by Gemini Pro decides what to look up before answering semantic search over the graph, subgraph exploration around a specific entity, or pulling the raw source text. It never freestyles without checking the graph first.
Streaming UI - The backend streams tokens to the frontend in real time while simultaneously sending graph_access events that tell the UI exactly which nodes and edges the AI touched so the knowledge graph lights up in sync with the response.
Frontend - React + TypeScript with a resizable split-panel layout: chat on the left, live knowledge graph on the right. Rendered on an HTML canvas with zoom, pan, and hover tooltips showing node facts and source attributions.
Challenges We Ran Into
Getting Gemini to consistently output clean, atomic facts was harder than expected. Left unconstrained, it would bundle multiple facts into one sentence, use actual entity names inside relation templates, or skip splitting compound statements. We spent significant time on few-shot prompt engineering and schema enforcement to lock down the output format.
Entity resolution was the other big one figuring out when two differently-named nodes are actually the same thing, without over-merging entities that just sound similar. Tuning the embedding similarity threshold to avoid both false merges and duplicates took real iteration.
Accomplishments We're Proud Of
The knowledge graph updates live mid-conversation you can watch the AI's reasoning light up on screen in real time. We're also proud that the full pipeline - upload, extract, resolve, index, retrieve, stream works end to end as one coherent system, not a collection of disconnected scripts.
Entity resolution working reliably without any manual labeling felt like a real win.
What We Learned
Structured fact extraction is its own discipline. An LLM that's great at conversation needs completely different prompting to become a reliable fact-extraction engine. We also learned that combining vector search with an explicit graph structure gives you something neither approach achieves alone the speed of embeddings with the precision of relationship traversal.
What's Next for MEMO
Real-time conflict alerts surfaced directly in chat when two documents disagree. A shareable graph mode so teams can build a collective knowledge base together one conversation at a time. And expanding beyond PDFs to emails, meeting notes, and live web sources, so MEMO becomes the memory layer for everything a professional team works with.
Built With
- google-generativeai
- hnswlib
- langgraph
- networkx
- numpy
- python
- react
- sentence-transformers
- typescript

Log in or sign up for Devpost to join the conversation.