-
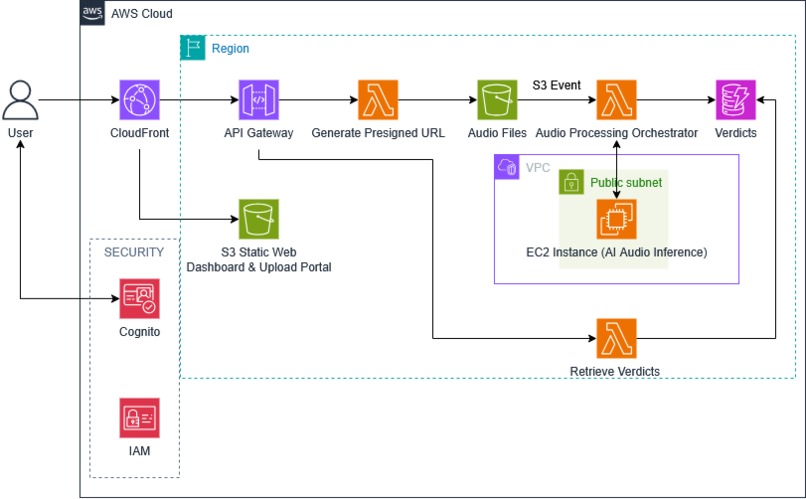
AWS Architecture for our Project
-
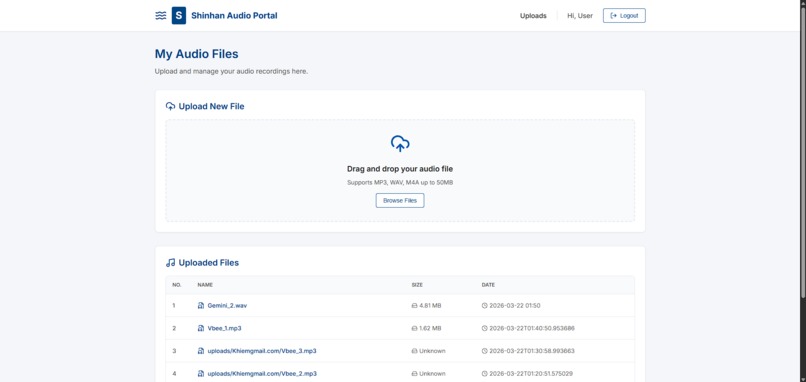
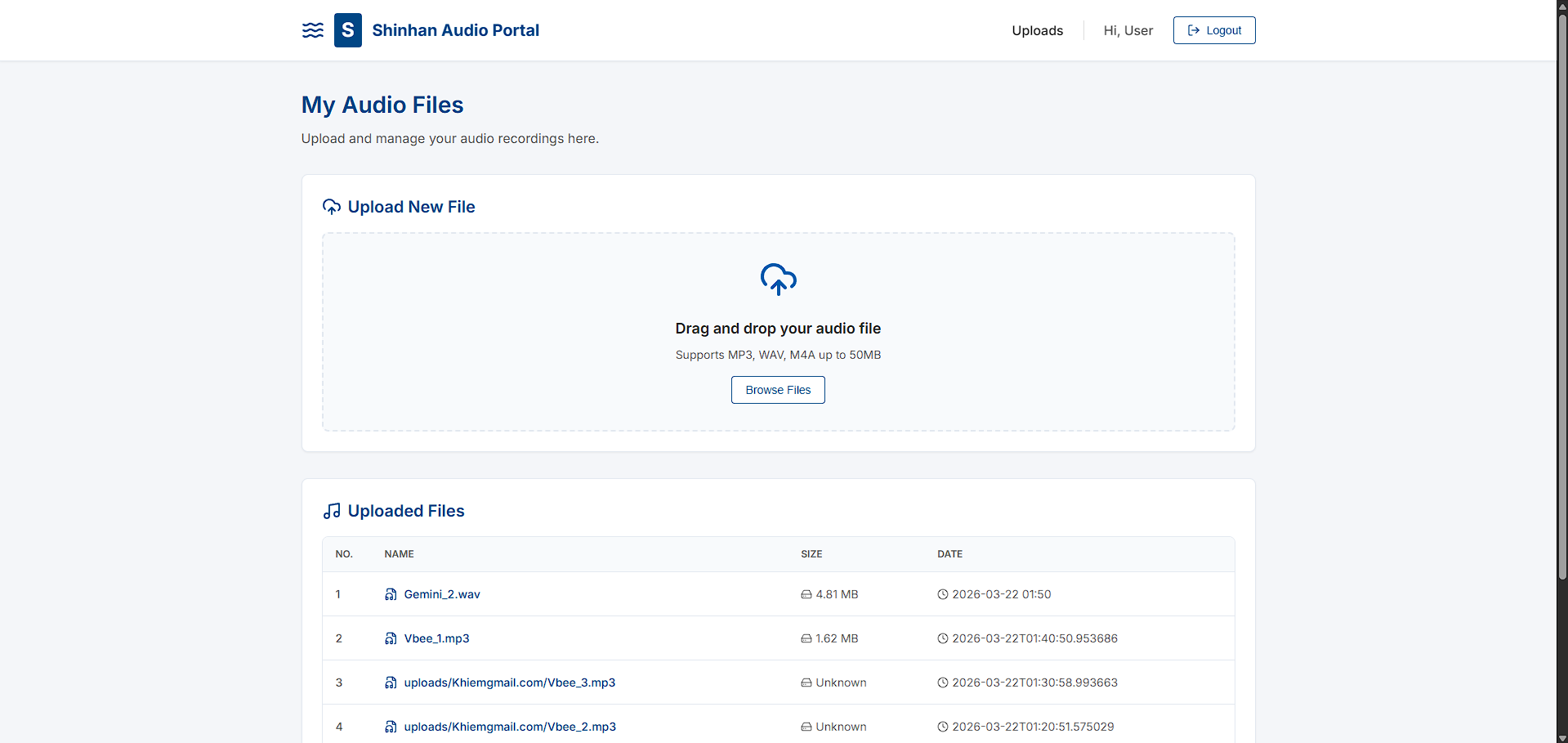
Web UI for User
-
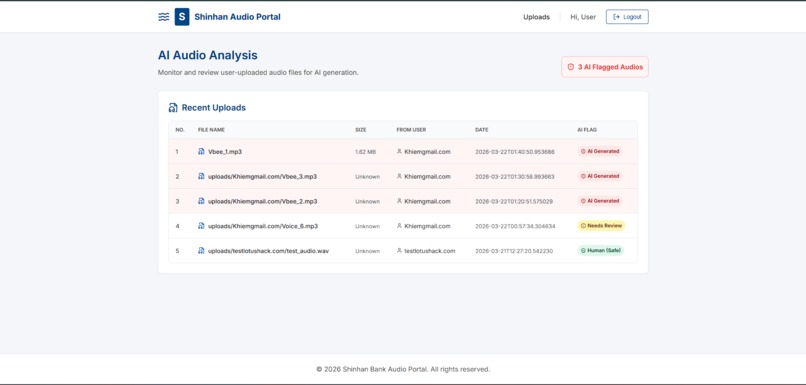
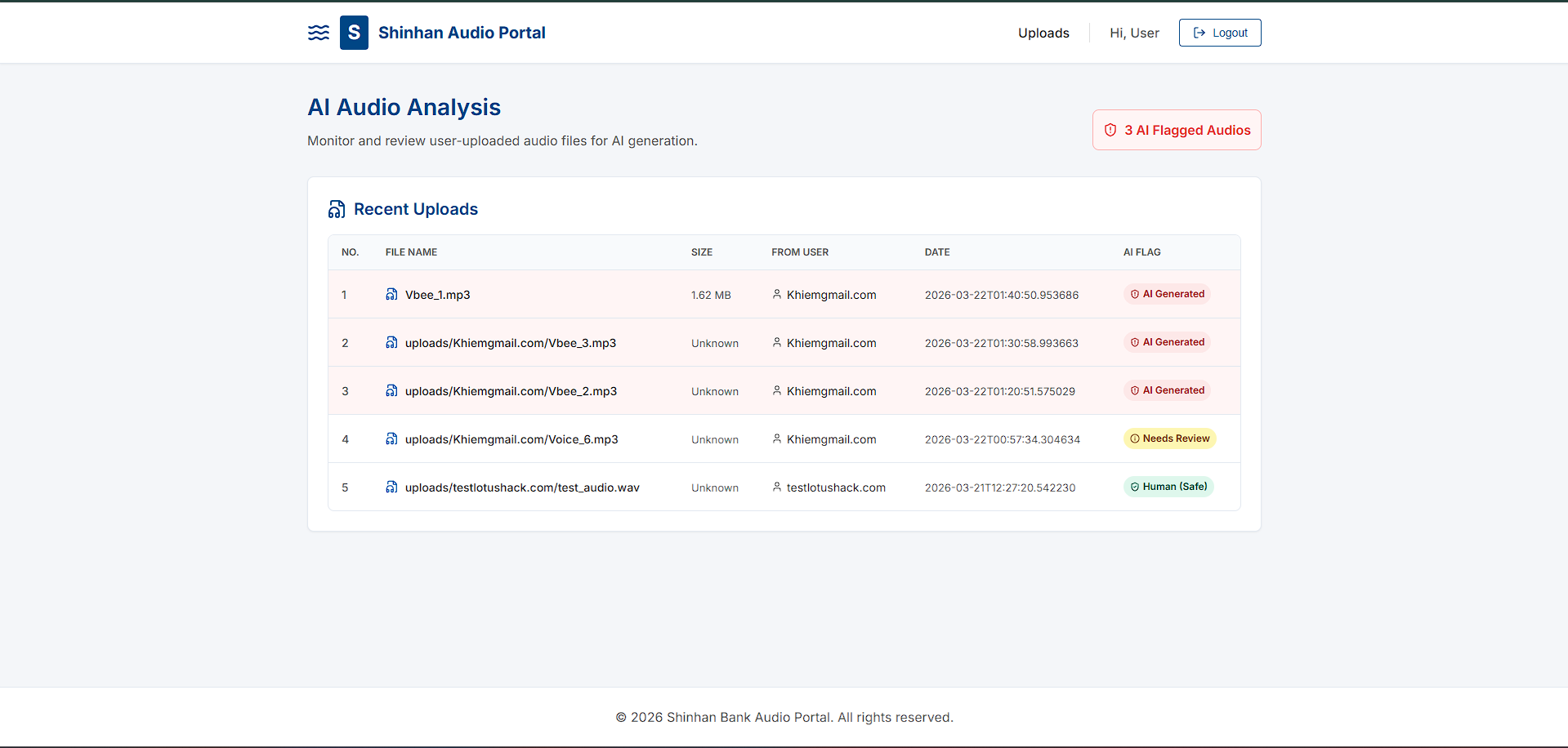
Web UI for Admin
Inspiration
https://app.genaifund.ai/usecase/e8825ead-c2d2-406e-9c6b-83c34a50258c Based on Shinhan Future's Lab Vietnam real problem, the SynthHunter Project was born out of an urgent need to restore and automate trust. We set out to build an intelligent, machine-learning-driven verification tool capable of analyzing audio files to definitively distinguish between authentic human dialogue and synthetic, AI-generated speech. By acting as a secure, automated checkpoint, this system ensures that every submitted recording is genuine—protecting the company from compliance risks and ensuring that the customer's true voice is always the one on record.
What it does
It is an audio classification system that decides whether a speech recording is human or AI-generated. It extracts features using XLS-R, Whisper, and pause pattern analysis, then combines their scores. It outputs a final verdict: HUMAN, AI GENERATED, or NEEDS REVIEW.
How we built it
We use an open-source detection models as a base because nowadays these models are easily fooled. When we set out to build a classifier to distinguish human speech from AI, we knew that one bullet wouldn't work. We needed a multi-signal ensemble approach to make detection robust, unbiased, and incredibly hard to trick.
- Here is how we built our three-pillar detection engine:
- Pillar 1: Speech Dynamics (XLS-R): We used XLS-R to capture the subtle, complex dynamics of human speech. By measuring temporal variance and frame-to-frame changes, we generated a score where higher values mapped perfectly to natural human variance.
- Pillar 2: Encoder Behavior (Whisper): We fed log-Mel spectrograms through a Whisper encoder to analyze how a robust speech recognition system reacts to the audio, extracting the variance into a secondary authenticity score.
- Pillar 3: Temporal Rhythm (Pause Analysis): Humans breathe and pause irregularly; AI is often unnaturally perfect. Using librosa, we measured pause duration, entropy, and rate to easily spot the robotic rhythm of generated audio.
- The Smart Decision Engine:
With three independent signals, our logic engine routes the final verdict based on system confidence:
- High Confidence -> HUMAN
- Low Confidence -> AI GENERATED
- Unclear (NEEDS REVIEW) -> Trigger "Second Pass" Our Fallback Weapon: For those tricky edge cases, the system automatically triggers a Deep Pause Analysis. This second pass scrutinizes the statistical stability and micro-consistency of the audio's pauses to break the tie and deliver a highly accurate final call.
AWS Architecture
We designed the system using AWS to ensure scalability, reliability, and real-world deployability:
Amazon S3 stores uploaded audio files securely Amazon CloudFront + S3 serve the frontend dashboard Amazon API Gateway + AWS Lambda generate presigned URLs for direct uploads S3 events trigger backend processing workflows Amazon EC2 hosts the AI inference engine (PyTorch + Whisper + XLS-R) Amazon DynamoDB stores classification results and verdicts Amazon Cognito handles user authentication and access control
This architecture allows the system to process audio asynchronously, scale efficiently, and integrate seamlessly into enterprise workflows.
Challenges we ran into
Advanced synthetic audio from ElevenLabs consistently bypassed existing open-source detectors. With strict time constraints, fine-tuning a custom model simply wasn't an option.
Accomplishments that we're proud of
Despite the advanced realism of ElevenLabs, our model successfully detects its synthetic audio with 80% - 85% accuracy. To ensure system reliability and avoid false confidence, any uncertain edge cases are safely routed to a "Needs Review" queue for human verification.
What we learned
Building this system taught us that the gap between generative AI and detection technology is closing fast, making out-of-the-box open-source models insufficient for enterprise compliance. More importantly, we learned that when hardware and time constraints prevent training a perfect model, smart engineering is the answer. By implementing a confidence threshold that routes uncertain audio to a human review queue, we realized that the best AI solutions don't just predict—they know when to ask for help.
Built With
- amazon-web-services
- huggingface
- python
- pytorch
- ubuntu


Log in or sign up for Devpost to join the conversation.