-
-
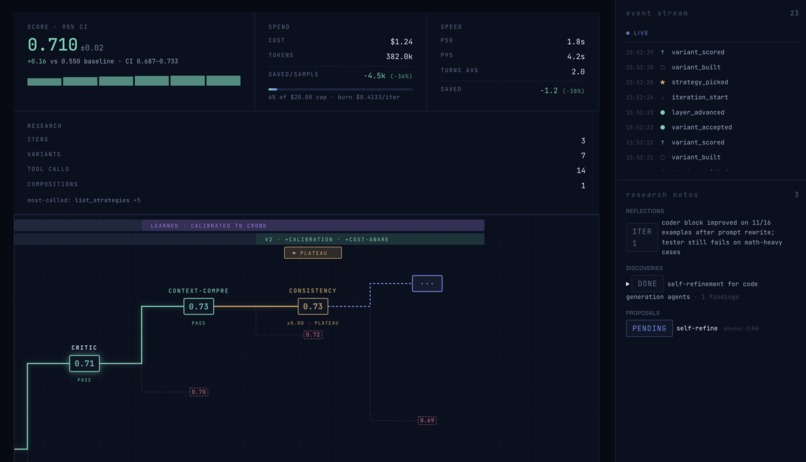
Having a rubric allows us to diagnose why an agent scores poorly, future iterations improve upon the past beating records.
-
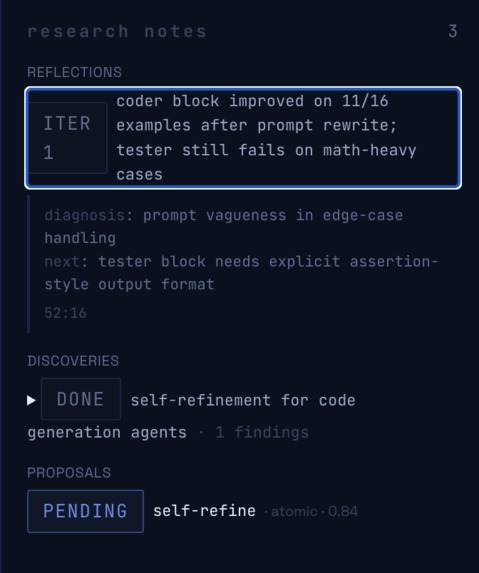
Research loop running: agent diagnoses past issues using a quantifiable score, grounds itself in papers, repos and tunes it to your uses
-
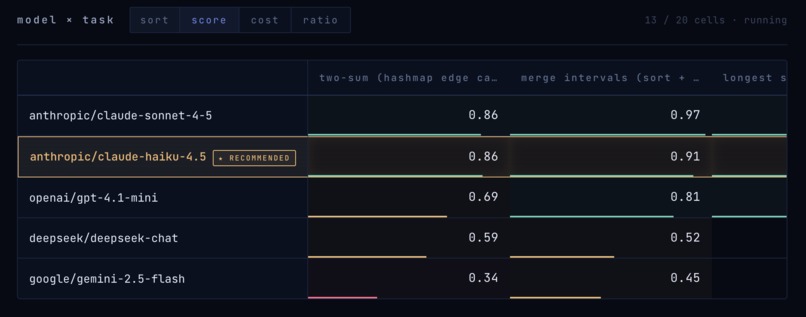
Model bakeoff: the latest model isn't always the best! we figure out which suits your use cases through rigorous evaluation
-
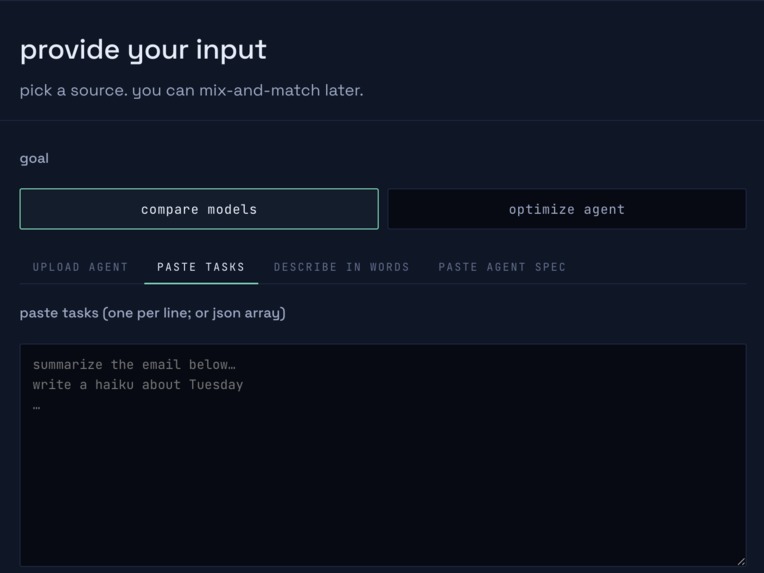
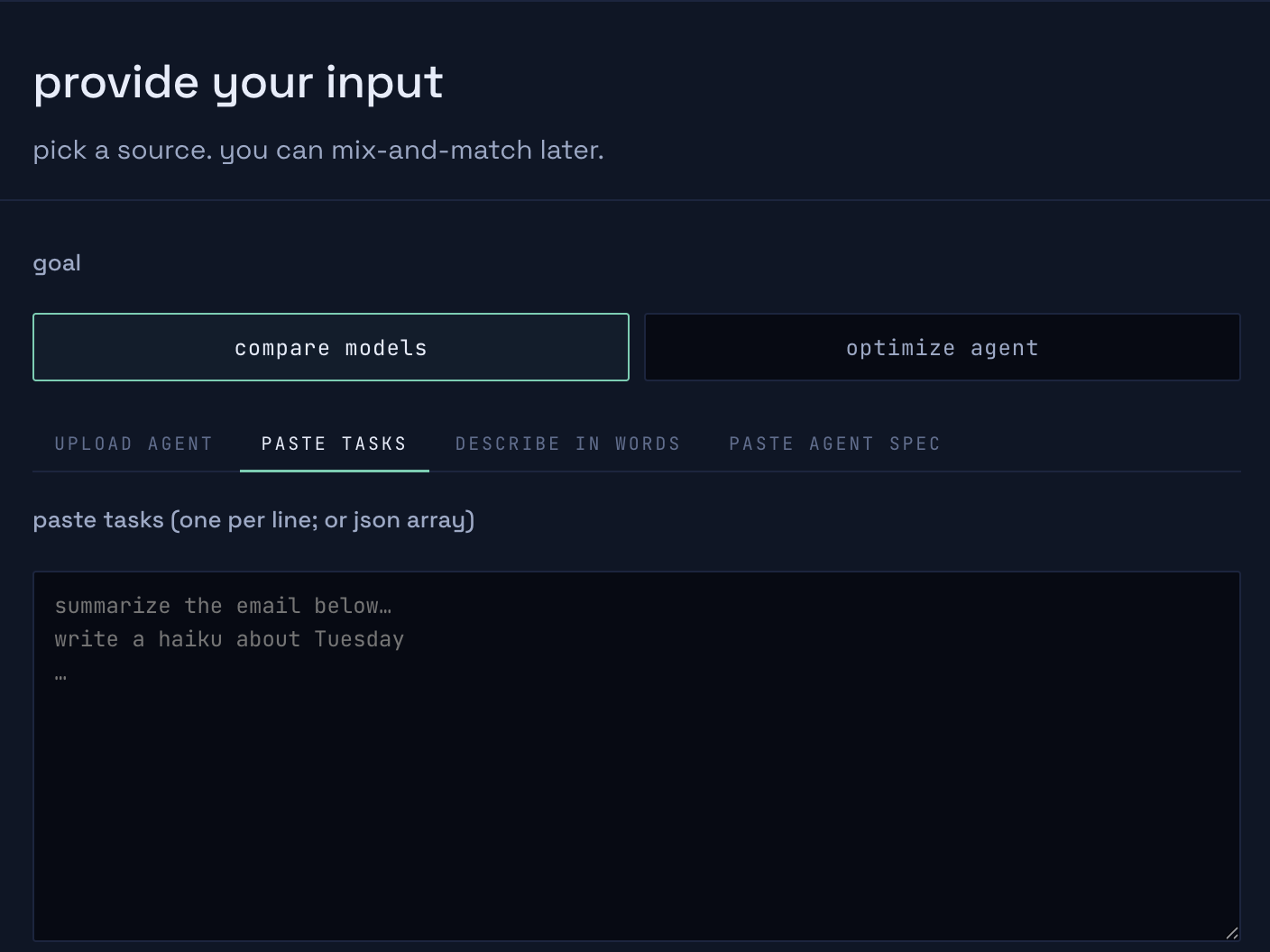
Simple setup wizard: attach a codebase, idea, tasks, or agent json we do the rest
Inspiration
Everyday tens if not hundreds of new repos are created to "improve your agent" at a specific task. We want to phase out all of that, all the unecessary time spent prompting, curating mcp servers, skills, harnesses, ALL OF IT. No more pondering how to get your ai to write a half decent joke.
Why can't you just drag in your codebase, idea, or existing agent have various models rigorously tested to YOUR use case, then have it all optimized and scored. AI coding agents — Devin, Cursor, Claude Code, Codex — can write code, run tests, and open PRs, but they still hit walls. The deeper problem: every existing optimizer commits to a single technique. DSPy bootstraps few-shot universally. TextGrad needs the user to hand-build a graph. OPRO and PromptBreeder evolve prompts blindly. JudgeFlow does block-level blame but applies one optimizer to whatever it finds.
A few-shot bootstrap won't repair an agent whose tool-calling is broken. A prompt rewrite won't fix a multi-agent coordination bug. We built the layer above all of it. Any agent, at any stage model selected, evaluations for any task grounded in research, everything around it optimized.
What it does
Drop in any AI coding agent — source, trace, or an OpenAI-compatible endpoint — and Escalon runs the full stack as two phases behind one URL:
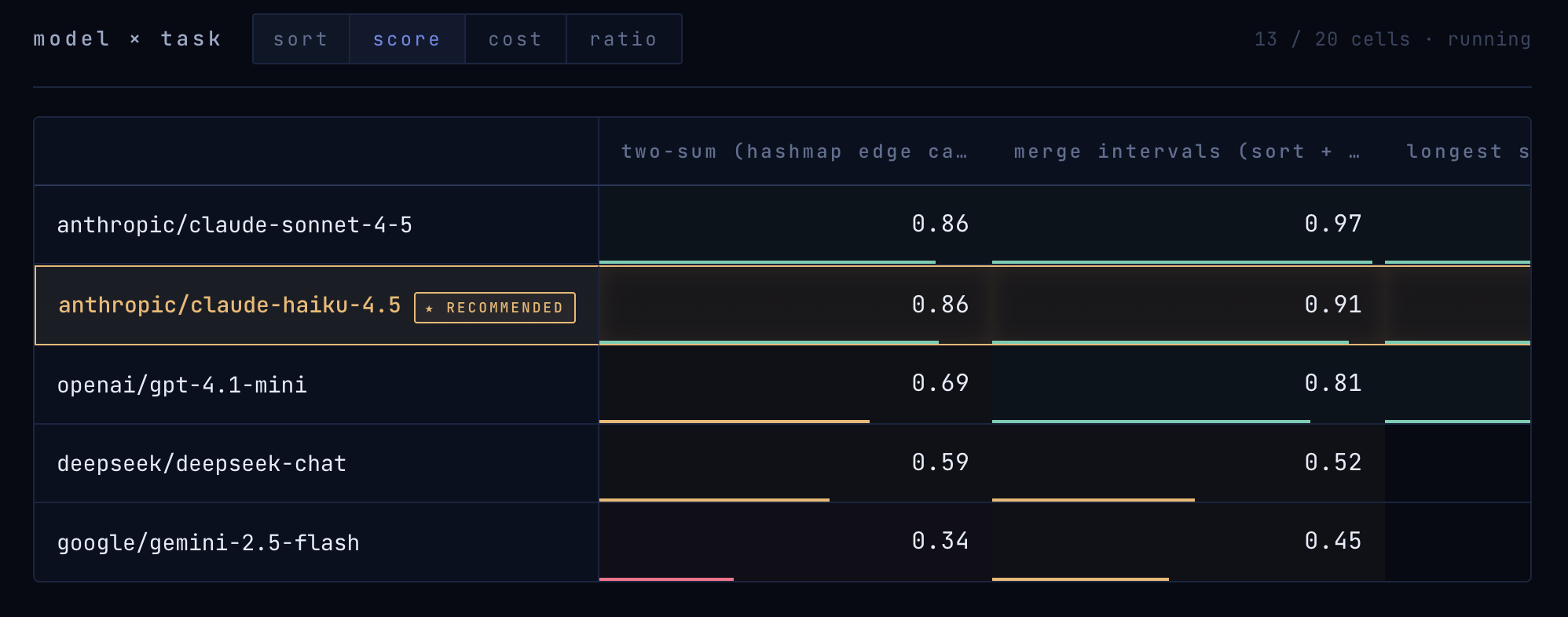
Phase 1 — Bake-off. N×M matrix: candidate models × the user's tasks. Pick the winning baseline before optimizing anything.
Phase 2 — Optimization loop. A 9-step diagnose-and-optimize pipeline that runs against the bake-off winner:
- Introspect — classify archetype (solo / multi-agent / tool-heavy / RAG-heavy / hybrid).
- Baseline — run agent on an eval batch.
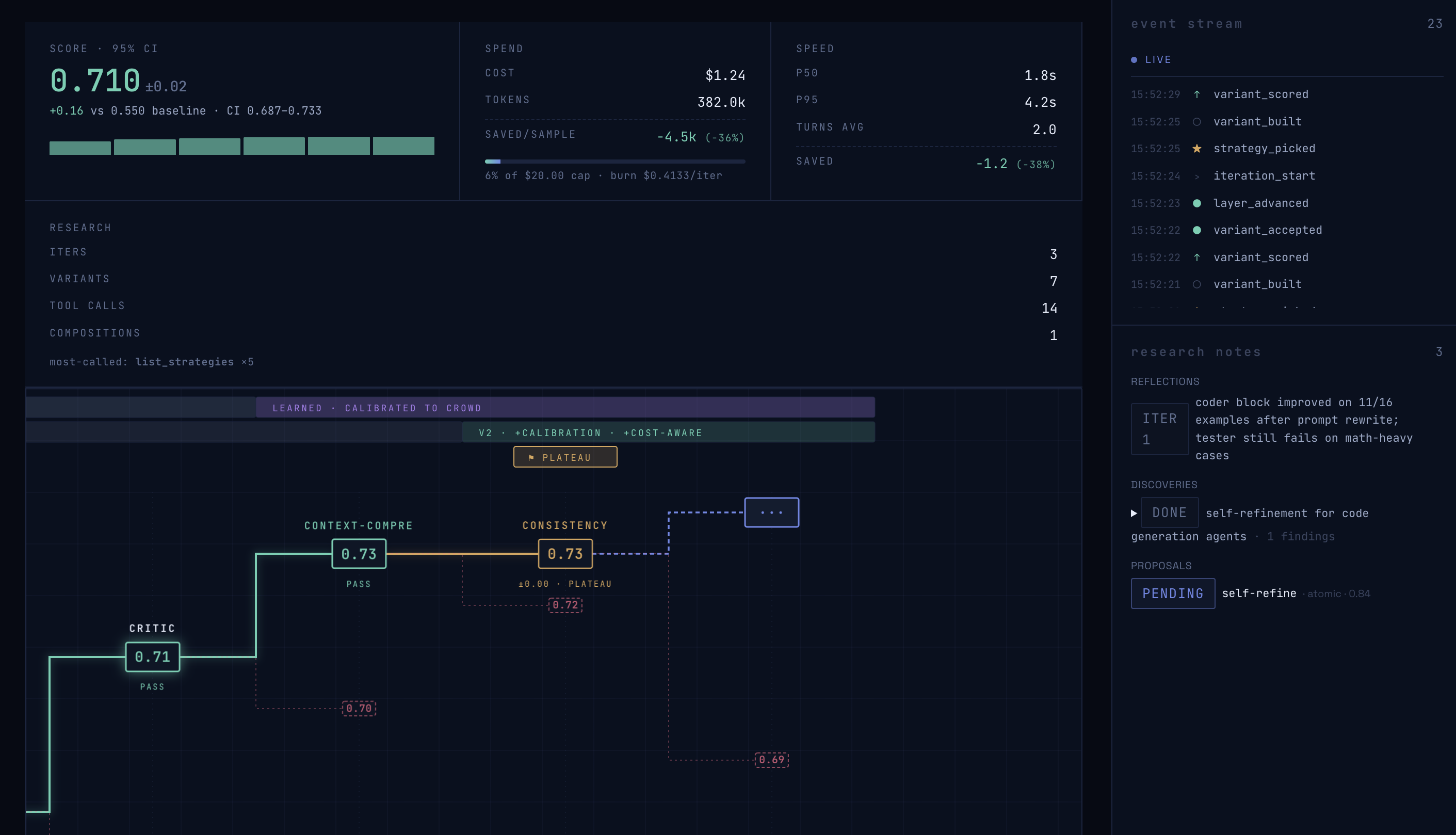
- Rubric — AdaRubric auto-generates task-specific criteria. Quantifying open-ended tasks.
- Score — 3-family judge panel + ArenaRL tournament.
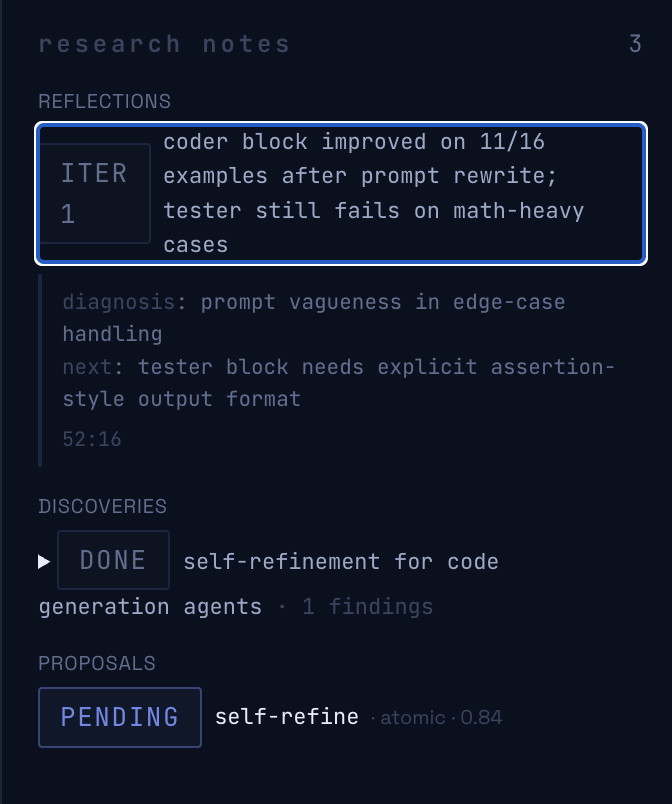
- Diagnose — JudgeFlow-style block-level blame: which prompt, which tool call, which retrieval step is bleeding score.
- Veto + Pick — meta-selector validates each pick against hardcoded FORBIDDEN rules (with paper citations), e.g. "vetoed self-refine for math_reasoning — Madaan et al. 2023, 0% improvement, 94% feedback was 'everything looks good'." Picks 2–3 strategies from the library.
- Run — strategies execute in parallel.
- Compare — re-score every variant with the same rubric, pick the winner.
- Return — improved agent, full lineage tree (every veto, every judge vote, every Δ), exportable as zip easily integrate into any LLM.
The engineer audits the system's reasoning at every step. Nothing hides behind a Run button.
How we built it
Backend. Python 3.12, FastAPI, Pydantic v2, async throughout. Pipeline state streams over Server-Sent Events via sse-starlette; SQLModel over SQLite for run artifacts (escalon.sqlite + data/bakeoff.db); NumPy for tournament rank aggregation. A ModelSpec-driven routing layer (eval/client.py) abstracts the Anthropic SDK, OpenAI SDK, OpenRouter, and the direct Gemini SDK so judges and agents are hot-swappable without touching call sites.
Model routing — zero Anthropic-priced calls on hot paths.
- Meta-selector / orchestration:
openai/gpt-5.5withreasoning_effort=high - Rubric evaluator + agent blocks (highest-volume, must be non-thinking):
moonshotai/kimi-k2-0905 - Summarizer (
context-compress):deepseek/deepseek-v4-flash - Judge panel: family-disjoint by construction —
deepseek/deepseek-v4-pro(DeepSeek) +moonshotai/kimi-k2.6(Moonshot) +z-ai/glm-5.1(ZhipuAI). Three labs, three training pipelines, three families.
Strategy library — 5 shipped, all behind one interface.
| Strategy | What it does | FORBIDDEN when |
|---|---|---|
prompt-rewrite |
LLM rewrites block prompt from failure examples | — |
critic-insert |
Adds a critic node downstream of the failing block | — |
self-consistency |
N=3 samples + aggregation | no verifiable signal (Wang 2022) |
self-refine |
Block critiques + revises own output | math / pure verification (Madaan 2023) |
context-compress |
RECOMP-style summarization with NO_CONTEXT sentinel |
multi-hop reasoning (Xu 2023) |
Each exposes the same propose → run → score → return shape so the meta-selector routes across them uniformly. Every veto cites the paper that motivates it.
Eval stack. AdaRubric vendored at vendor/AdaRubrics/. SBC replication vendored at vendor/sbc-replication/ — full taxonomy, judge prompt, 3,076 labeled traces. Judge panel implements PoLL (Verga 2024) + MT-Bench (Zheng 2023) position-swap gating: only judges whose verdict is consistent across A↔B swap are kept; <2 surviving judges → tie. Tournament is an ArenaRL port (anchor-seeded single-elim, 2(N-1) judge calls; quantile rewards + standardized advantages).
Reference agents (built-in demo targets, real eval datasets):
humor— solo single-block, New Yorker captionscoder— multi-agent planner → coder → tester, HumanEvalrag— tool-heavy ReAct + search/lookup, HotpotQA
Frontend. React 18 + TypeScript + Vite, TanStack Query, Zustand, React Router v6. Custom design-token CSS, no Tailwind, no component library. SSE-driven pipeline timeline, ELO-style judge tournaments with sparklines, click-through lineage tree, archetype-aware sidebar.
Challenges we ran into
Veto correctness. A meta-selector that picks the wrong family is worse than one that runs everything blindly. We grounded every veto in a hardcoded FORBIDDEN table where each entry cites the paper that motivates it (Madaan 2023 for self-refine on math, RECOMP 2023 for context-compress on multi-hop, Wang 2022 for self-consistency without verifiable signal). The meta-selector LLM proposes; validate_pick() enforces. An engineer can audit the reasoning chain end-to-end rather than trusting a black-box recommendation.
Judge-panel calibration. Three judges from the same model family vote in lockstep. We measured strong inter-vote correlation on early test runs and the "panel" was cosmetic. Switching to family-disjoint judges (DeepSeek + Moonshot + ZhipuAI — three labs, three training pipelines), surfacing split votes (rather than averaging them away), and gating each judge by MT-Bench position-swap consistency was the unlock.
Hot-path cost containment. With three strategies × twenty samples × three judges per loop, costs add up fast. We routed every per-iteration heavy role to non-thinking smart-cheap models (Kimi K2-0905 for blocks + rubric, DeepSeek v4 flash for summaries) and kept the orchestration brain (GPT-5.5) on the low-volume meta path only. Live cost meter, per-block budget caps, dominated-variant short-circuiting on the wire.
Backpressure on SSE. Parallel variants emit thousands of events per loop across 30+ event kinds (baseline_scored, variant_built, judge_voted, rubric_evolved, selector_thought, …). sse-starlette framing plus a coalescing client buffer kept the live view at 60 fps under three concurrent tournaments.
Architecture inference under partial info. When a user gives us a trace but no source, we infer block structure from observed call patterns. The meta-selector's confidence appears in the UI rather than getting hidden, so an engineer knows when to trust the routing call and when to override.
Accomplishments that we're proud of
- A meta-selector that justifies its non-picks. Every vetoed strategy ships with a paper citation in code (
introspect/rules.py). Trust through traceability, enforced statically. - Family-disjoint judging out of the box. DeepSeek + Moonshot + ZhipuAI as the default panel, with MT-Bench position-swap gating and explicit split detection. No other open hackathon-built optimizer we know of ships PoLL-style multi-family judging by default.
- Two phases, one URL. Bake-off picks the baseline; the loop optimizes against it. The frontend wraps both into one
Runand auto-advances; the backend keeps/api/bakeoffs/*and/api/loops/*cleanly separated. - A live UI that earns the "show your work" claim. Archetype detection → veto with citations → tournament with per-judge votes → winner with Δ. All visible, all clickable, no loading-screen theatre.
- 60-hour build, 2 people. ~15K LOC backend Python, ~12K LOC frontend TypeScript, ~14K LOC tests. AdaRubric and SBC vendored and wired. Real evals on real reference agents (HumanEval, HotpotQA, NewYorker captions). No mocked demos in the critical path.
What we learned
- Architecture is the prior. Once you have an archetype classification, the strategy search space collapses by roughly 70%. Most optimizer compute spent today is on runs the architecture should have ruled out a priori.
- Specificity earns trust faster than polish. A live counter reading
μ = 0.55 → 0.70, Δ = +0.15, n = 20buys more credibility in two seconds than any onboarding flow. - Same-family judges are not a panel. PoLL is right; we measured it. And position-swap gating matters as much as family-disjointness — judges who flip on swap have to drop out, not get averaged in.
- Thinking models melt budgets on the hot path. They burn tokens on
reasoning_contentand return emptycontent, scoring 0. Reserve them for the orchestration brain; route per-iter heavy work to non-thinking smart-cheap models. - Verification is harder than generation. Catching behavioral drift in an agent's outputs is the actual bottleneck for AI coding agents today. A judge panel with split detection beats a single rubric score every time.
What's next for Escalon
- MCP server. Ship
escalon.classify,escalon.diagnose,escalon.optimize,escalon.tournament_statusas MCP tools so any MCP-speaking client (Claude Code, Cursor, Devin) calls Escalon mid-task instead of context-switching to a separate workflow. - First-class Devin / Cursor / Claude Code integrations. Beyond raw MCP, ship a Devin skill and a Cursor extension so the optimizer is one click from any agent IDE.
- GitHub-native loops. Point Escalon at a repo, get a PR with the winning variant and full lineage attached as the PR description. CI re-runs the rubric on every commit; behavioral regressions get flagged automatically before merge.
- More archetypes, more families. Strategy library v1 —
retrieval-reformulate,topology-trim,debate,model-role-swap,tool-restrict,mce-context-evolve. Planner, RAG-heavy, and streaming sub-archetypes. - Cost-aware Pareto search. The tournament is currently single-objective. Next: live Pareto front over (score, latency, $/call) with user-set weights.
- Self-hosted judges. Swap the judge-panel API for locally-served Qwen or Llama-3 for cost and reproducibility on long-running benches.
- Public archetype leaderboard. Aggregate anonymized winning variants per archetype into a community-curated optimizer prior — the strategy library becomes a learned object.
Built With
- claude
- devin
- fastapi
- gemini
- html/css
- javascript
- mcp
- numpy
- openrouter
- pytest
- python
- react
- sql
- typescript
- uvicorn
- windsurf
- zustand



Log in or sign up for Devpost to join the conversation.