-
-
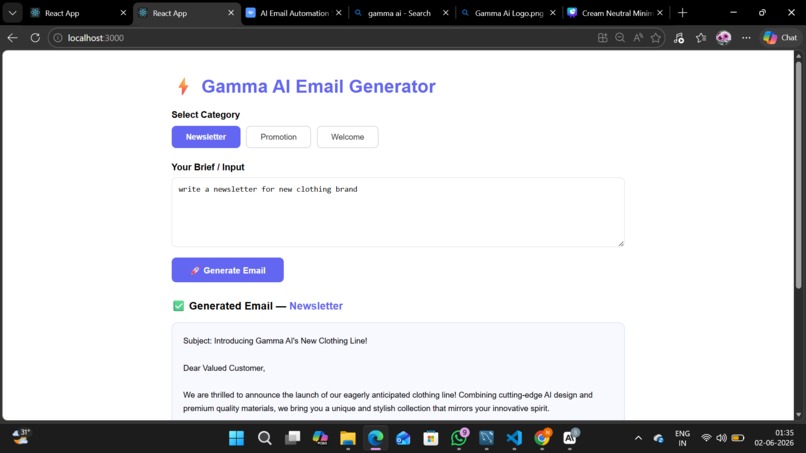
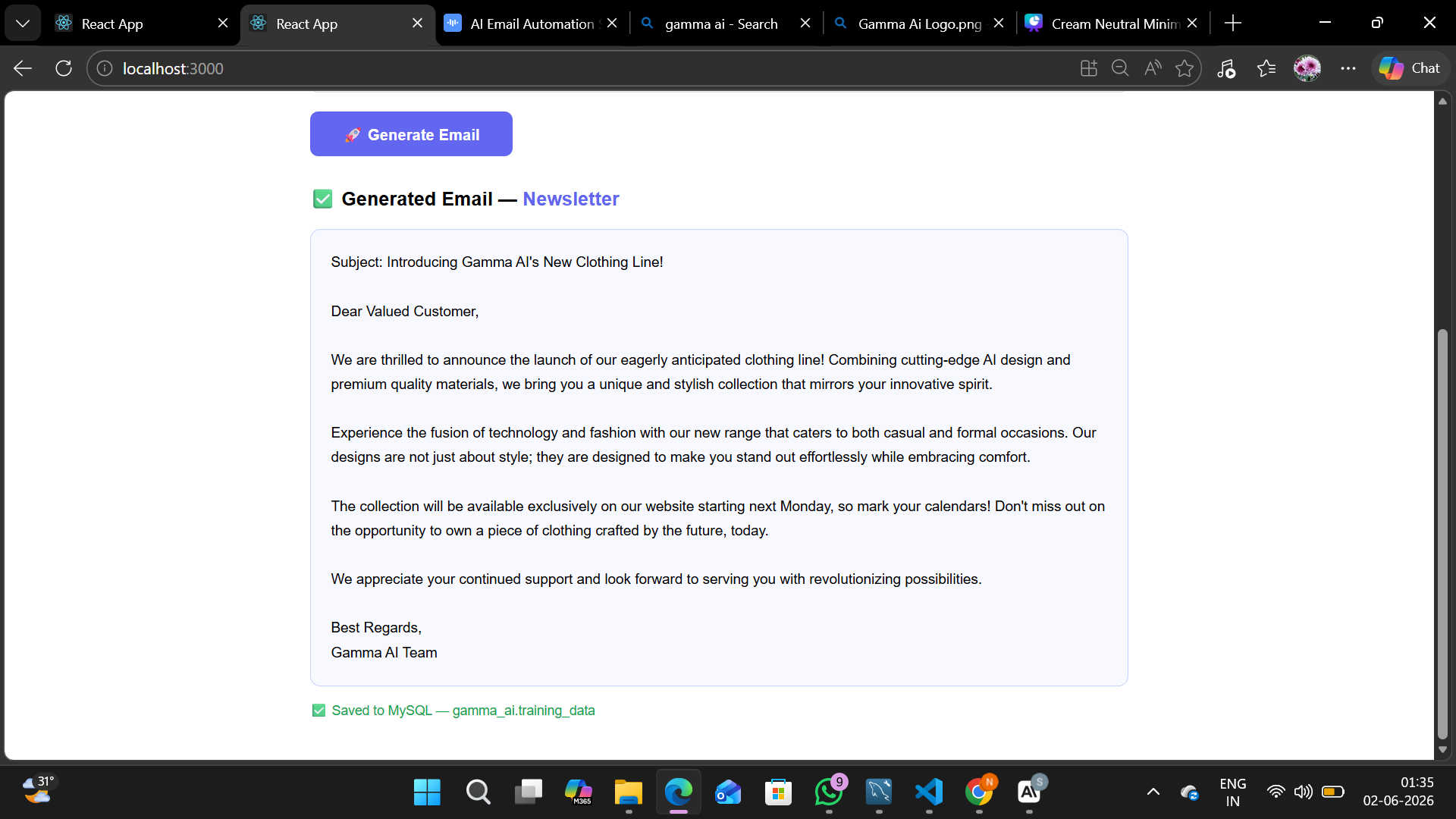
Gamma AI Email generator
-
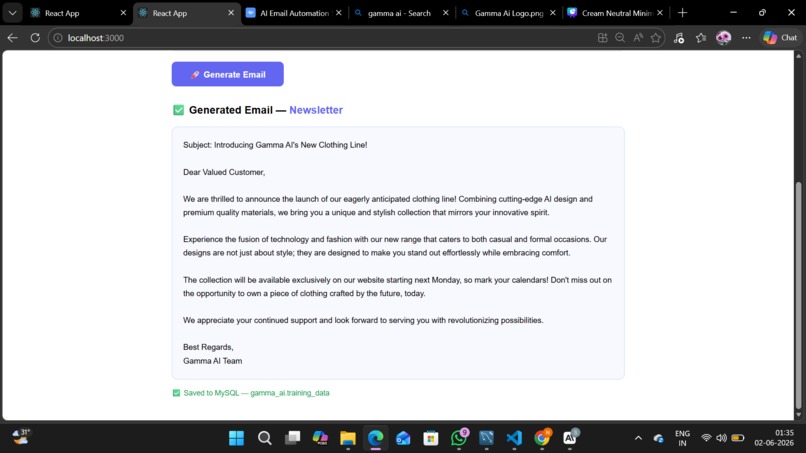
Generated email
-
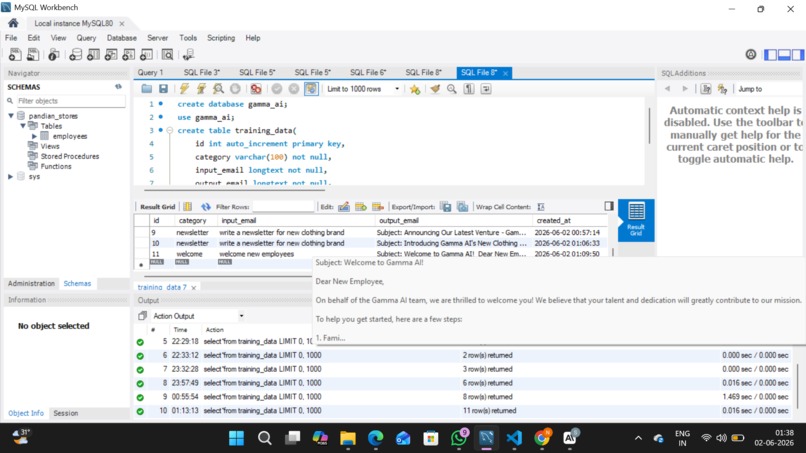
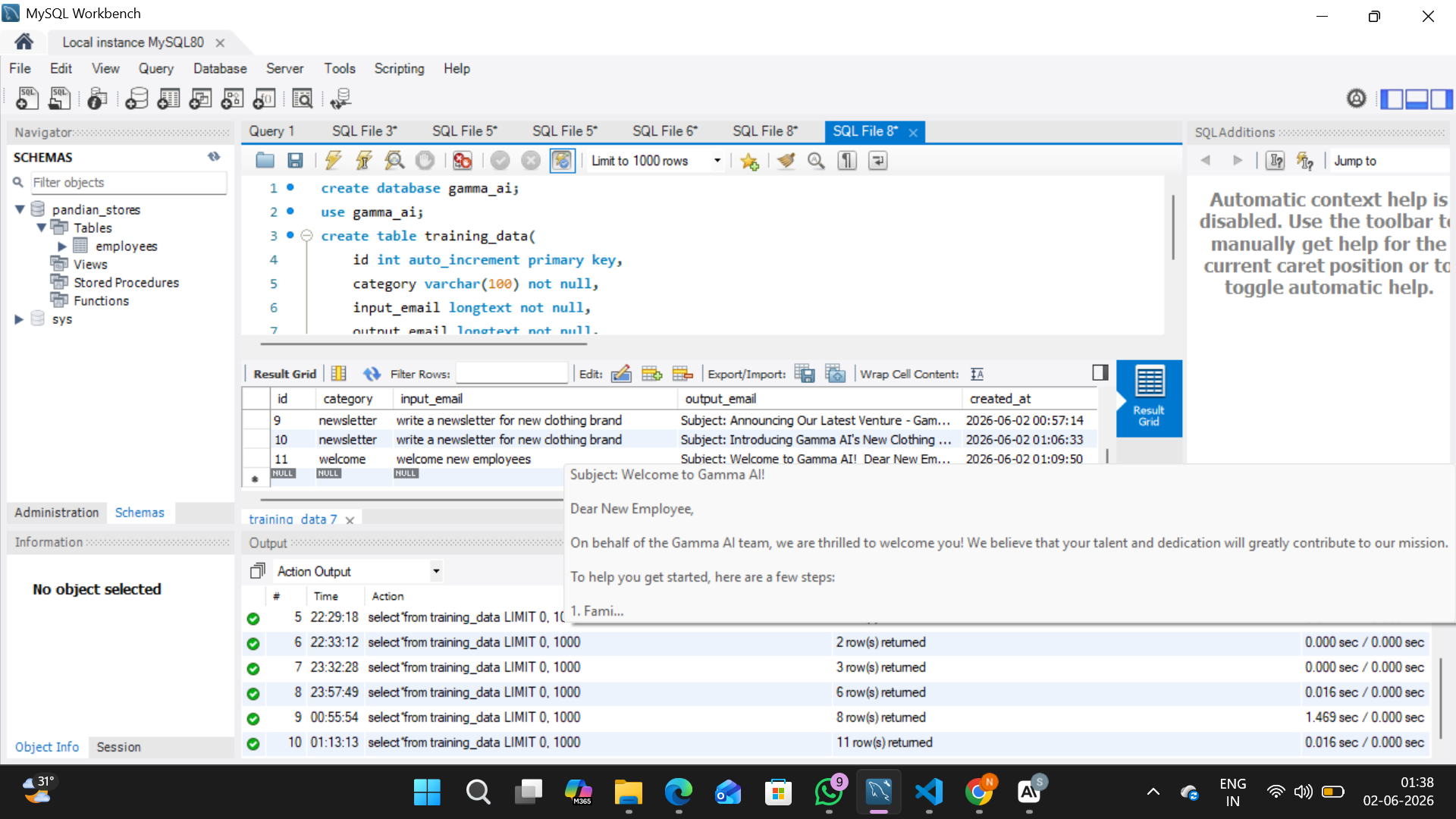
Storing in database
Gamma AI — Multi-Agent Email Automation Engine
Inspiration
Every day, marketing and operations teams across enterprises spend an enormous amount of time drafting emails — newsletters, promotional campaigns, welcome messages for new users. The problem is not just the time it takes. It is the inconsistency. Different team members write in different tones. Brand guidelines get ignored under deadline pressure. Sensitive business content gets pasted into cloud AI tools, raising compliance red flags.
We asked ourselves a simple question:
What if a specialist AI agent — one that already knows your brand voice, your tone, and your structure — could generate a professional email in under two minutes, entirely on your own machine?
That question became Gamma AI.
We were also inspired by the growing maturity of local LLM tooling. Ollama has made it trivially easy to run powerful models like Mistral and LLaMA 3 on a developer's laptop. CrewAI has made it possible to define specialist agents that behave like real team members. Combining both felt like the right moment to prove that enterprise-grade AI automation does not require a cloud.
How We Built It
We built Gamma AI as a full-stack local application across four layers:
1. Frontend — React
A clean, minimal React interface where users select an email category (Newsletter, Promotion, or Welcome), type a brief, and click Generate. The UI shows the generated email and confirms when it has been saved to the database.
2. Backend — FastAPI
A Python FastAPI server exposes a REST API at /api/email/generate. Because FastAPI is fully asynchronous and CrewAI's crew.kickoff() is synchronous, we solved the conflict using Python's ThreadPoolExecutor:
output = await asyncio.wait_for(
loop.run_in_executor(executor, orchestrate, category, user_input),
timeout=600
)
This keeps FastAPI's async performance intact while running CrewAI safely in a worker thread.
3. Multi-Agent Orchestration — CrewAI + Ollama
This is the core of the project. We defined three specialist agents using CrewAI, each with a distinct role, goal, and behavioral backstory:
| Agent | Role | Behavioral Constraint |
|---|---|---|
| Newsletter Agent | Informative journalist | Engaging, factual, under 200 words |
| Promotion Agent | Persuasive copywriter | Punchy, benefit-driven, strong CTA |
| Welcome Agent | Onboarding specialist | Warm, clear next steps, reassuring |
Each agent is connected to Ollama running Mistral 7B locally via the "ollama/mistral" model string — no API keys, no cloud.
At runtime, the orchestrator loads real .eml training files from disk and injects them into the agent's task prompt as few-shot context. This is a lightweight RAG-lite pattern that teaches the LLM Gamma's brand voice without any fine-tuning.
4. Database — MySQL
Every generated email is automatically saved to gamma_ai.training_data with the category, the user's original brief, the AI output, and a timestamp. Over time, this becomes a searchable corpus of branded emails.
The Math Behind Agent Quality
One insight we validated during building: specialist agents outperform general-purpose prompts because of how language model probability distributions work.
When a model generates text, it samples from a conditional probability distribution:
$$P(w_t \mid w_1, w_2, \ldots, w_{t-1}, \text{context})$$
A generic prompt leaves context broad, producing a high-entropy distribution — the model hedges across many possible writing styles. A specialist agent's role + goal + backstory narrows the context significantly, reducing output entropy:
$$H(X) = -\sum_{i} P(x_i) \log P(x_i)$$
Lower entropy means more focused, consistent, on-brand output. This is why defining a backstory like "You are a direct-response copywriter. You NEVER use HTML. You always include one CTA." produces measurably better emails than a single generic prompt asking for "a promotional email."
The few-shot .eml examples further condition the distribution toward the target style — analogous to Bayesian updating of the prior:
$$P(\text{style} \mid \text{examples}) \propto P(\text{examples} \mid \text{style}) \cdot P(\text{style})$$
What We Learned
1. Multi-agent design is about separation of concerns, not complexity. We initially considered using one agent with a category parameter. After testing, we found that dedicated agents with category-specific backstories produced dramatically more focused output. The lesson: give each agent one job and one identity.
2. Local LLMs are production-ready for structured tasks. Mistral 7B running on Ollama generated coherent, brand-consistent emails reliably. For constrained generation tasks like email writing — where the output structure is predictable — a 7B parameter model is more than sufficient.
3. The async/sync boundary is a real engineering problem.
Integrating a synchronous library (CrewAI) into an async framework (FastAPI) without blocking the event loop required careful use of ThreadPoolExecutor. This is a pattern every developer building AI backends will encounter.
4. Few-shot prompting via real files beats fine-tuning for POCs.
Loading .eml training files at runtime and injecting them as prompt context gave us brand-aligned output without a single GPU-hour of fine-tuning. For rapid prototyping, this approach is underrated.
5. Plain text is harder to enforce than it sounds.
Getting an LLM to consistently output plain text — no markdown, no HTML, no asterisks — required explicit constraints in both the agent backstory and the Task description, plus a post-processing cleanup step with regex. Behavioral constraints need to be stated in multiple places.
Challenges We Faced
Challenge 1 — Python Version Compatibility
CrewAI requires Python 3.10–3.12. Our initial environment used Python 3.14, which caused immediate ModuleNotFoundError failures. We had to rebuild the virtual environment from scratch using py -3.12 -m venv venv. Lesson: always check framework compatibility before environment setup.
Challenge 2 — Async/Sync Conflict
Running crew.kickoff() directly inside a FastAPI async def endpoint raised:
Agent execution was invoked synchronously from within a running event loop.
The fix — wrapping the synchronous call in loop.run_in_executor() with a ThreadPoolExecutor — took significant debugging to land on correctly.
Challenge 3 — LLM Response Timeout
Local LLMs are slower than cloud APIs. Initial requests timed out at 30 seconds. We increased the timeout to 600 seconds (10 minutes) on both the backend (asyncio.wait_for) and the frontend (AbortController). We also switched from LLaMA 3 (8B) to Mistral 7B for faster inference.
Challenge 4 — HTML Leaking Into Output
Even with explicit "no HTML" instructions in the prompt, the LLM occasionally returned <p> tags or markdown bold text. We solved this with a post-generation cleanup function using regex:
def clean_output(text: str) -> str:
text = re.sub(r'<[^>]+>', '', text) # strip HTML
text = re.sub(r'\*\*?|__?', '', text) # strip markdown
text = re.sub(r'#{1,6}\s?', '', text) # strip headers
text = re.sub(r'\n{3,}', '\n\n', text) # normalize whitespace
return text.strip()
Challenge 5 — CORS Configuration
The React frontend (port 3000) could not reach the FastAPI backend (port 8000) due to CORS policy. Setting allow_origins=["*"] with allow_credentials=False resolved it for the POC environment.
What's Next
- Fine-tuned model — use the
training_dataMySQL table to fine-tune Mistral on Gamma's exact email corpus via LoRA/Unsloth - Judge Agent — a fourth CrewAI agent that reviews and scores the output of the other three before returning the best result
- Parallel crew execution — run all three agents simultaneously and select the highest-quality output
- Docker deployment — containerize the full stack for single-command startup in any environment
- Feedback loop — users rate generated emails; ratings feed back into training data selection
Built With
CrewAI · Ollama · Mistral 7B · FastAPI · React · MySQL · LangChain · Python 3.12 · ThreadPoolExecutor
Built at the AI for Business Automation Hackathon · May 2026 · Gamma AI Team


Log in or sign up for Devpost to join the conversation.