-
-
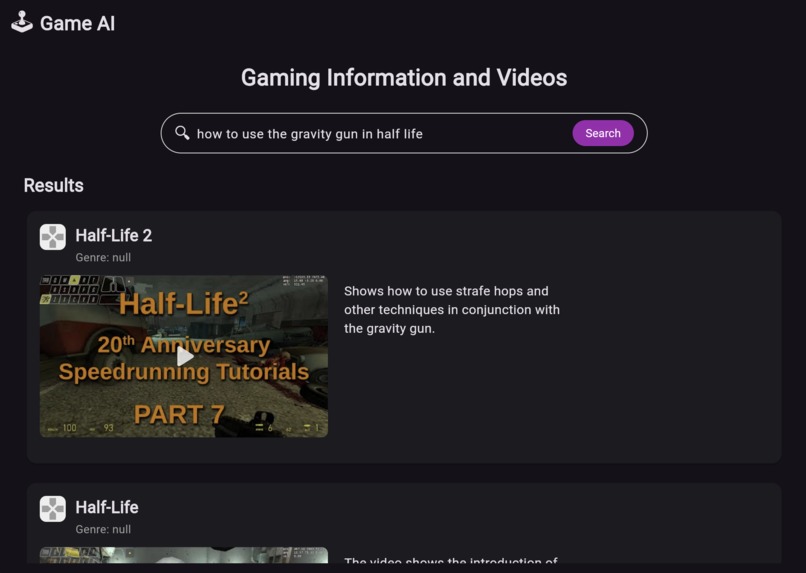
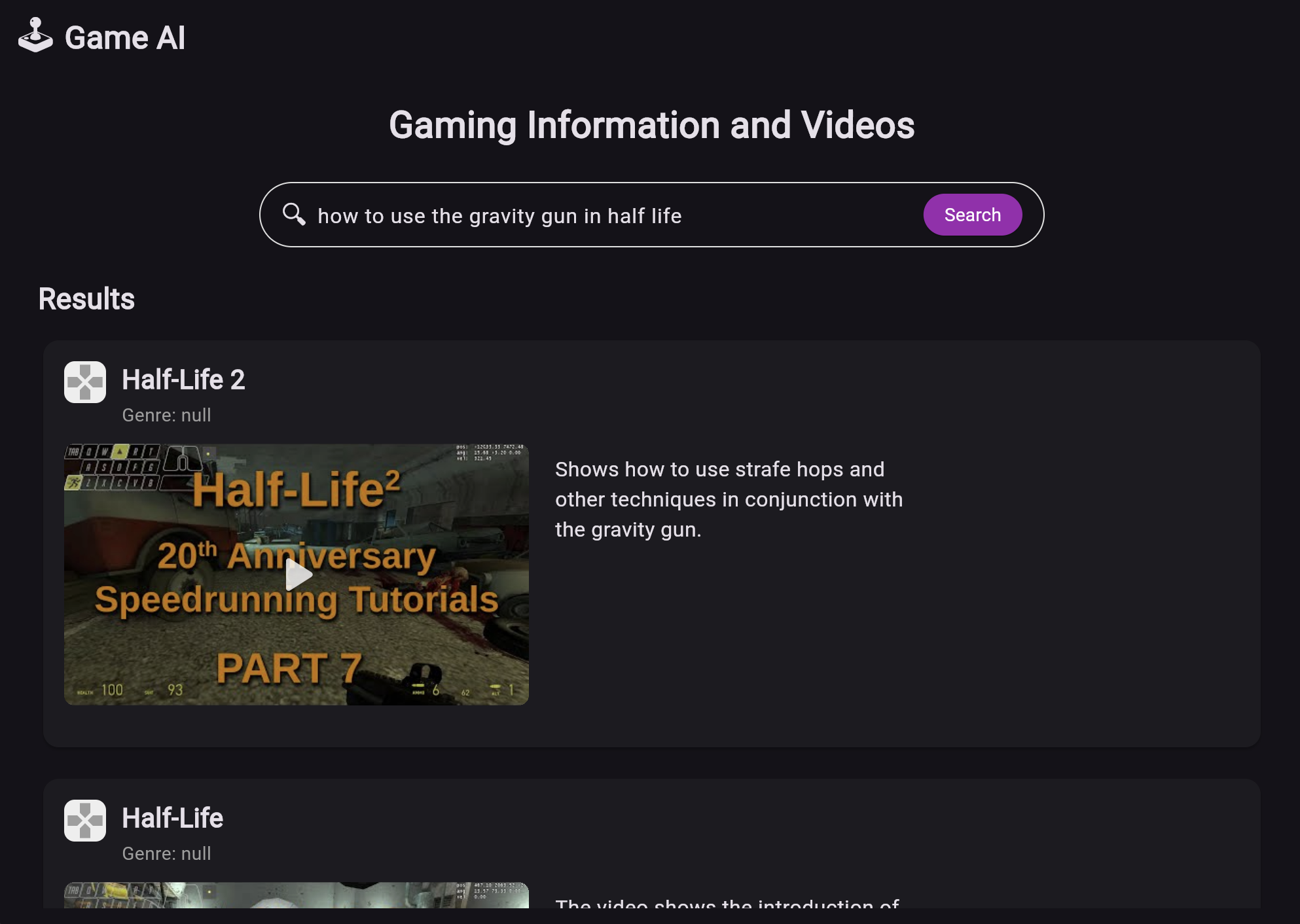
Search for tips
-
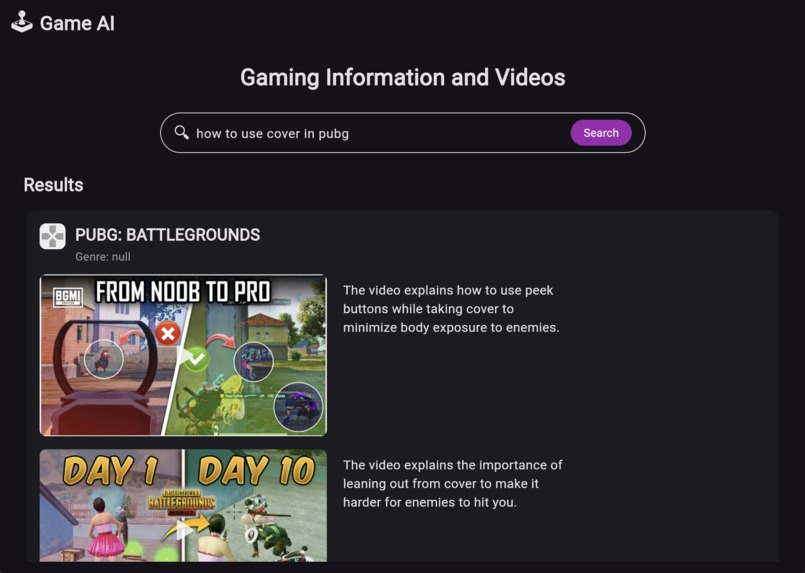
Search for techniques
-
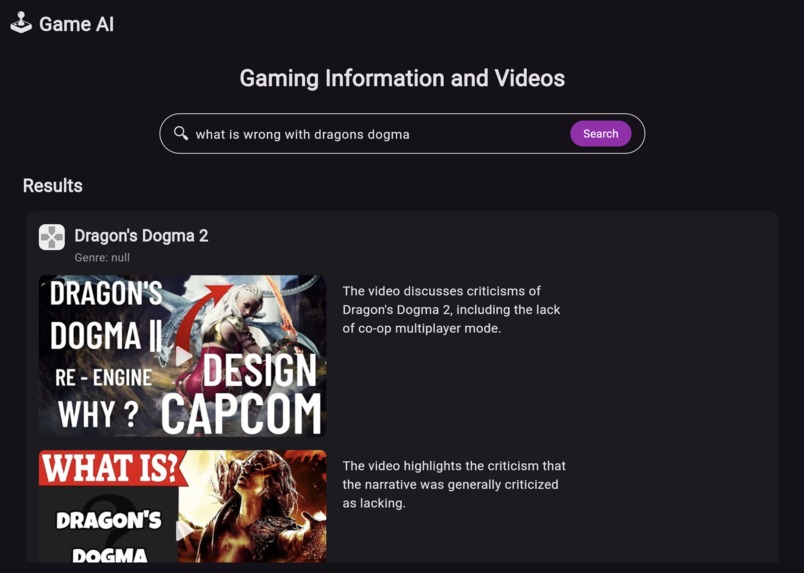
Search for opinions
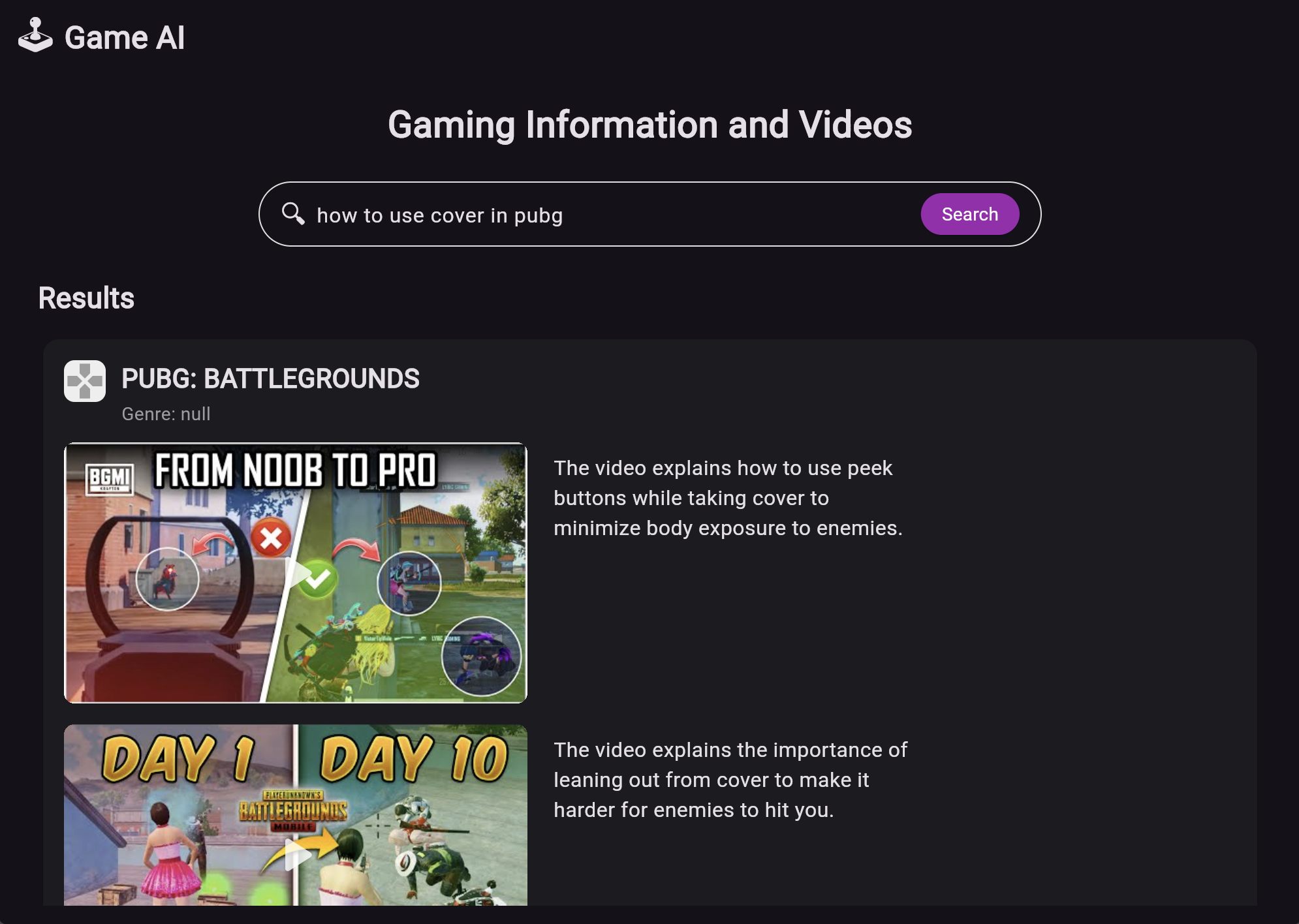
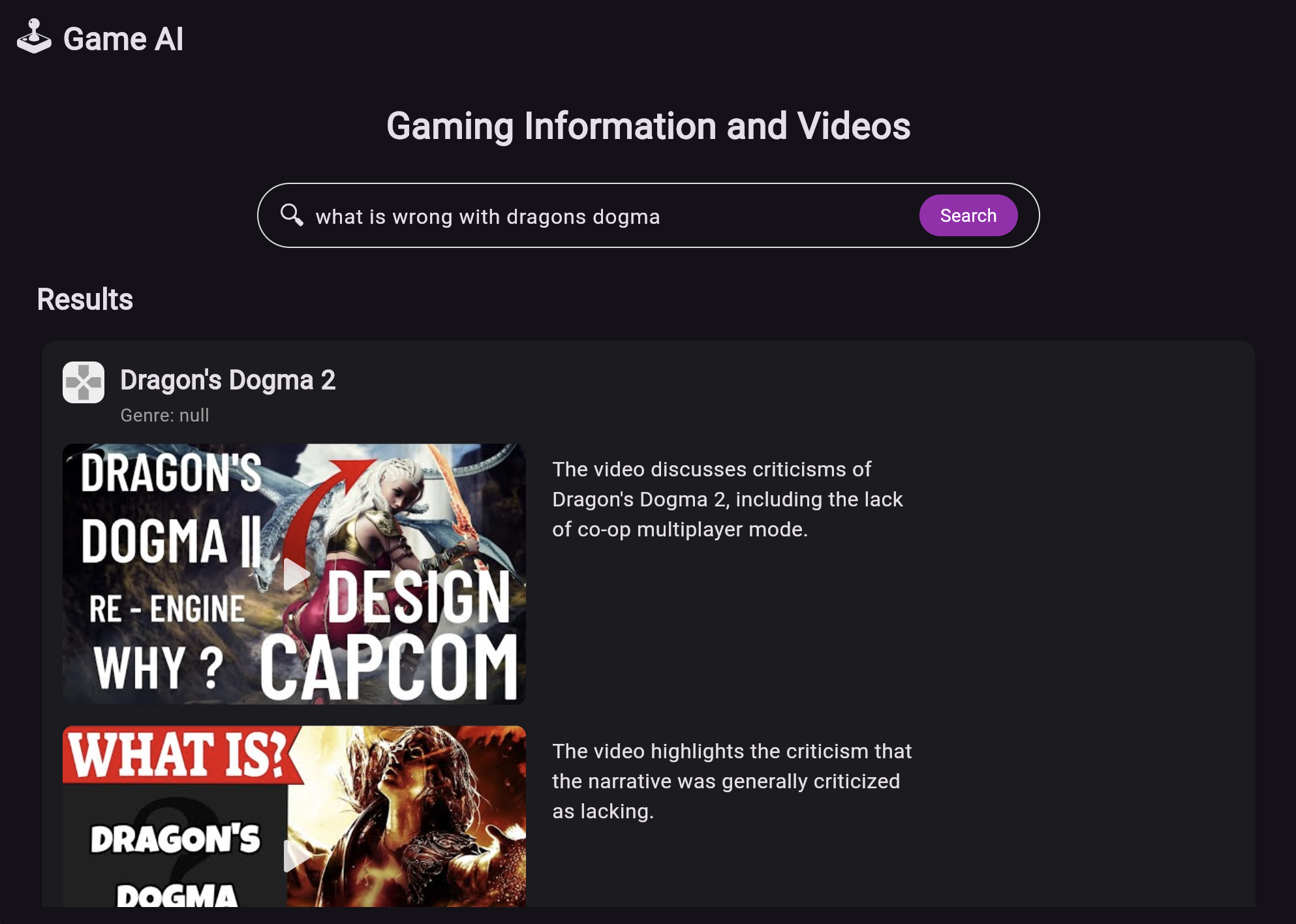
🎮 Inspiration
Game guides and reviews are scattered across hours-long videos. We wanted a tool that feels like “Ctrl + F for YouTube,” surfacing the exact 30 seconds you need—no scrubbing, no spoilers.
🛠️ How We Built It
Data pipeline
- Scraped metadata & transcripts of videos for ~1 000 games.
- Stored raw docs + embeddings in MongoDB Atlas; chunked transcripts for time-level recall.
- Scraped metadata & transcripts of videos for ~1 000 games.
Three purpose-built vector indexes
games– reliable name matchingtips-tricks– guides & walkthroughsreviews– critiques & first-looks
AI retrieval workflow
- Prompt Refiner (Gemini-Flash) extracts game titles + intent from the user’s NL query.
- Vector search (Atlas Vector Search) fetches top-k chunks, optionally pre-filtered by
gameId. - Neighboring chunks are fetched from Firestore to give context without extra Atlas storage.
- Response Refiner (Gemini-Flash) ranks chunks, adjusts timestamps, and explains relevance (RAG).
- Prompt Refiner (Gemini-Flash) extracts game titles + intent from the user’s NL query.
Frontend
- Built in Flutter Web → snappy, single-page UX.
- Deployed on Firebase Hosting; queries hit a Cloud Functions worker that orchestrates the flow.
- Built in Flutter Web → snappy, single-page UX.
🤓 What We Learned
- Designing multi-index RAG: balancing precision (vector search) vs. recall (context expansion).
- Cost-savvy hybrid storage: Atlas for search-critical data, Firestore for cold context.
- Prompt engineering for timestamp alignment inside video transcripts.
🚧 Challenges
- Synonym explosion in game titles (localized names, DLCs). Solved with a lightweight embedding-based matcher.
- Keeping latency < 2 s despite two LLM hops—caching embeddings and parallelizing index hits did the trick.
🌱 Next Steps
- Auto-scraper that adds fresh game videos daily.
- Explore extracting valuable information from video description and comments (e.g. sentiment)
Built With
- flutter
- gcp
- gemini
- javascript
- mongodb
- vertexai
- youtube



Log in or sign up for Devpost to join the conversation.