-
-

cover
-

visualization
-

best model


What it does
It predicts the acceptance of a given mortgage application.
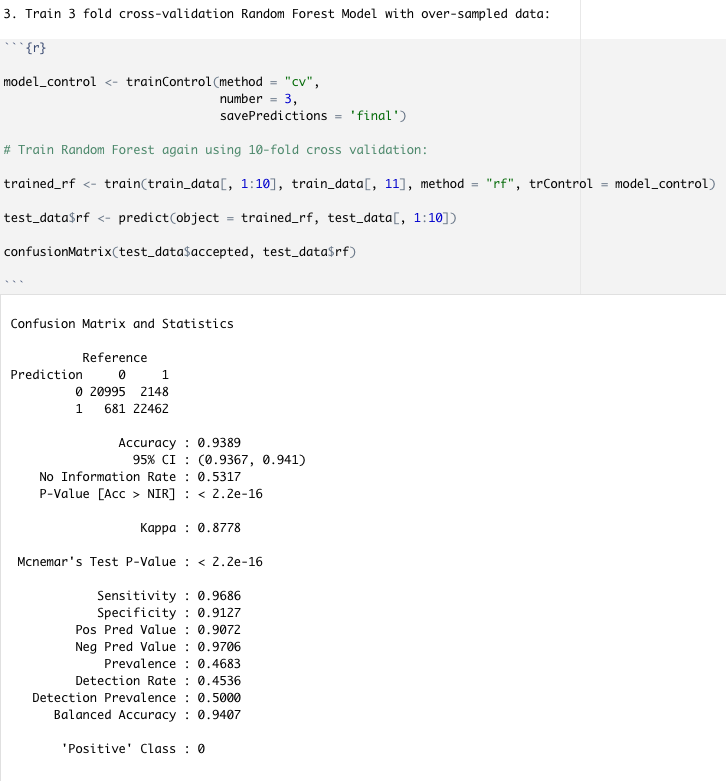
How we built it
We cleansed the data in R, then fixed data imbalance using the SMOTE technique in Python. After that, we tried various models in R, such as the logistic regression, kth nearest neighbors, etc. Finally, we obtained a 93.89% accuracy using a 3-fold cross-validation random forest model.
Challenges we ran into
We ran into some bugs in our code when we tries to do data clearance. But we have resolved this by trying different dimensions of data frame. Also, our false positive was really high at first when using random forest without cross-validation. But we resolved the issue with cross-validation.
Accomplishments that we're proud of
We are proud of successfully completing our first datathon.
What we learned
What we learned is that it is hard to pick the best model in a very limited time frame, so we need to definitely be more efficient at extracting all the data and filtering works since these are the most time-consuming work before actually building a model.
What's next for Game of Loans: Home Purchases in Harris County, TX
- Use the oversampled data to build a more robust ensemble model to improve the accuracy of our prediction beyond the time limit of this datathon challenge;
- Choose different variables and compare the results of different models;
- Explore more options of modeling techniques (neural networks, basic logistic/penalized regression models, etc)










Log in or sign up for Devpost to join the conversation.