-
-
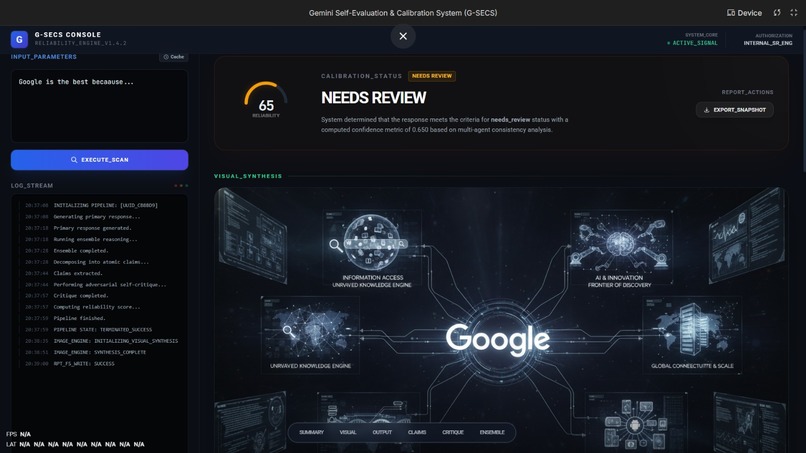
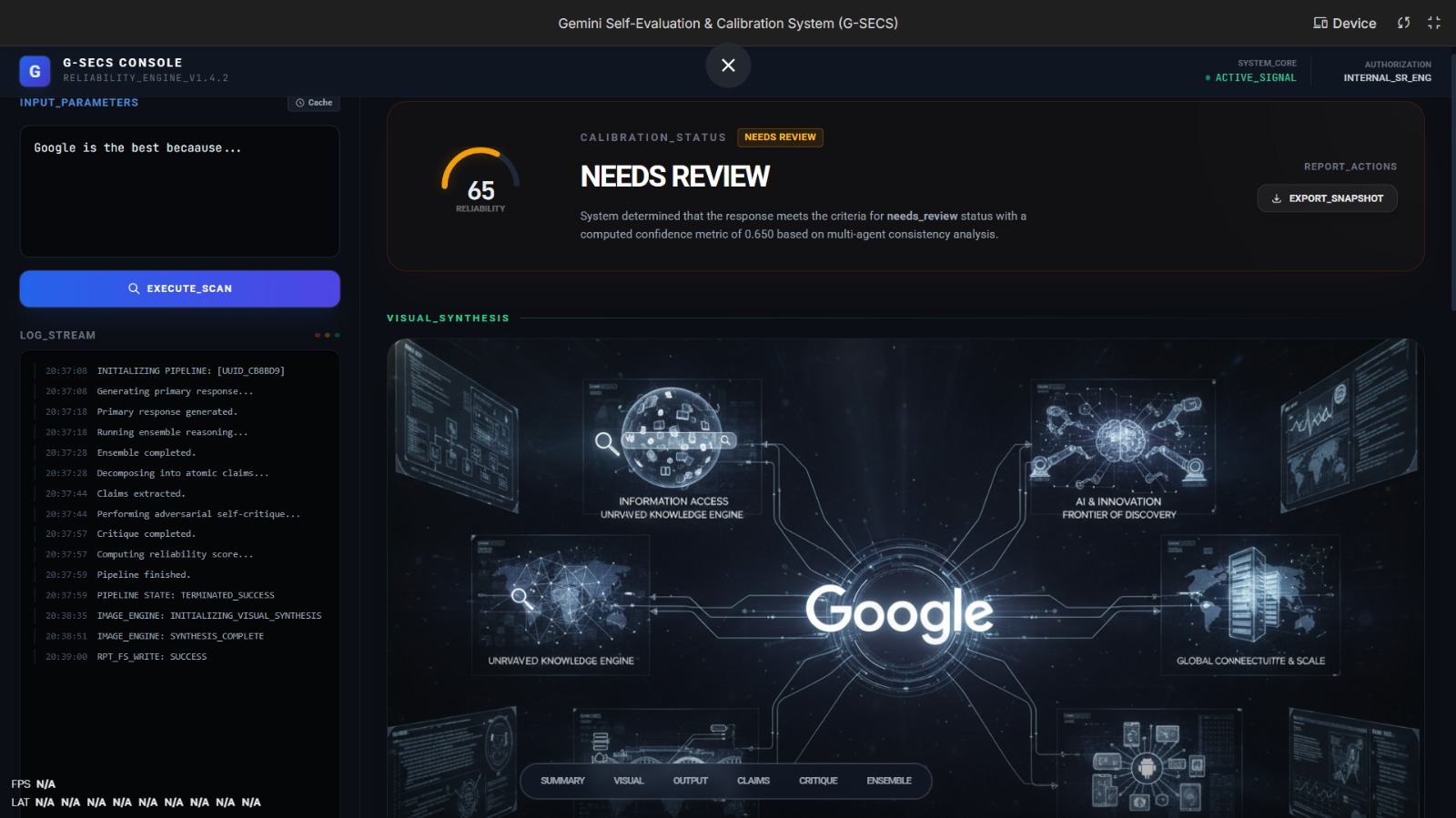
Main Page Of the project
-
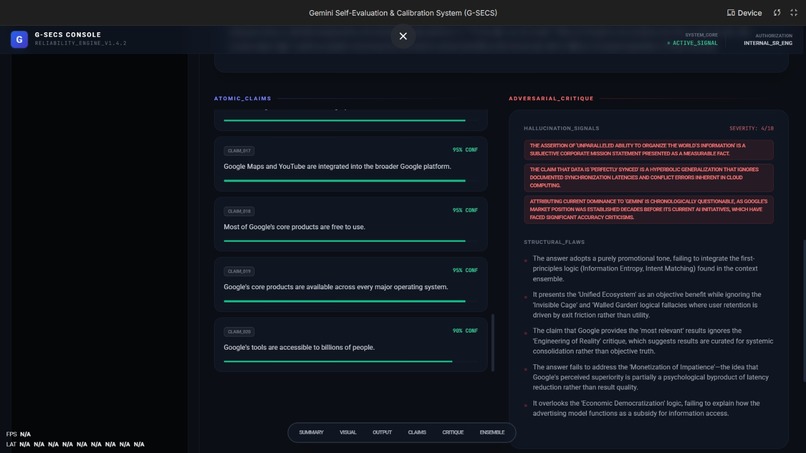
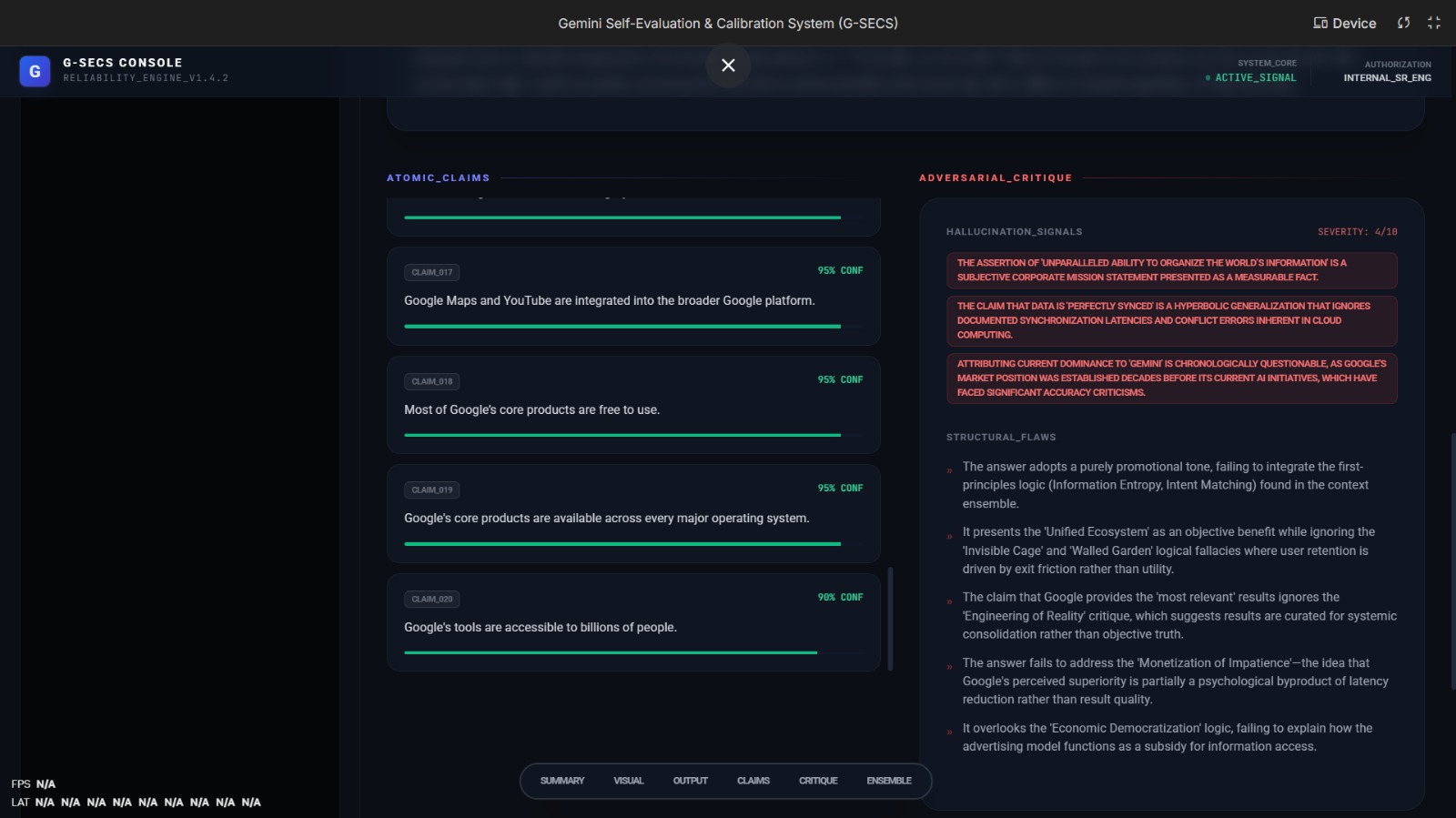
Reports
Inspiration
-As Gemini scales across search, coding, agents, and enterprise workflows, a key challenge emerges: how does the model know when it might be wrong? Most LLM systems optimize for fluency rather than calibrated confidence. -We were inspired by Google’s work on model evaluation, uncertainty estimation, and AI safety, and asked a simple question: what if Gemini could evaluate its own answers before users rely on them? -G-SECS (Gemini Self-Evaluation & Calibration System) was built to act as an internal reliability layer that enables Gemini to self-audit, quantify uncertainty, and correct high-risk outputs using only the Gemini API.
What it does
G-SECS is a self-evaluating reliability engine for Gemini responses. For every user query, the system:
- Generates a primary Gemini answer
- Produces multiple independent reasoning paths
- Decomposes responses into atomic claims
- Performs adversarial self-critique
- Measures cross-answer agreement and contradictions
- Estimates probability of correctness
- Computes a calibrated reliability score
- Classifies outputs as Reliable, Needs Review, or High Risk
- Regenerates a safer answer when risk is high The system outputs structured confidence signals that can be directly integrated into agents, search workflows, and safety pipelines.
How we built it
G-SECS is implemented as a multi-agent prompt orchestration system powered entirely by the Gemini API. Key components include:
- Independent reasoning agents to avoid shared bias
- A claim extraction agent for atomic fact analysis
- An adversarial critic agent to surface weaknesses
- A calibration agent that converts disagreement into probability scores
- A controller that decides trust, review, or regeneration All agents communicate through structured JSON, making the system deterministic, debuggable, and production-ready. No fine-tuning, external datasets, or third-party tools are used.
Challenges we ran into
- Preventing circular reasoning across agents
- Designing reliability scores without external ground truth
- Balancing safety with answer usefulness
- Maintaining hackathon-feasible scope while ensuring real-world applicability
Accomplishments that we're proud of
- Built a fully self-contained Gemini reliability system
- Designed a calibrated confidence score instead of binary judgments
- Created a drop-in backend component usable across Gemini products
- Demonstrated that LLMs can self-evaluate without external supervision
What we learned
- Prompt orchestration can replicate many evaluation benefits without training
- Model disagreement is a strong signal of uncertainty
- Self-critique improves safety more consistently than single-pass guardrails
- Trustworthy AI depends on knowing when not to be confident
What's next for G-SECS
- Integration with Gemini Agents for real-time confidence signaling
- Domain-specific calibration for sensitive use cases
- Long-term memory for recurring failure patterns
- Human-in-the-loop review triggers
- Deployment as a standard internal Gemini reliability layer
Built With
- fastapi
- firestore
- gemini
- github
- google-cloud
- multiagent
- pydantic
- python
- requests

Log in or sign up for Devpost to join the conversation.