Inspiration
Every day, people make high-stakes decisions—from navigating treacherous travel routes to executing volatile stock trades—often relying on gut feeling and incomplete data. We realized that existing AI tools act like simple chatbots, not strategic advisors. We wanted to build a "Tactical Command Center" for everyday life. A digital sixth sense that not only analyzes real-time telemetry to predict outcomes but also profiles the user's psychological risk appetite.
What it does
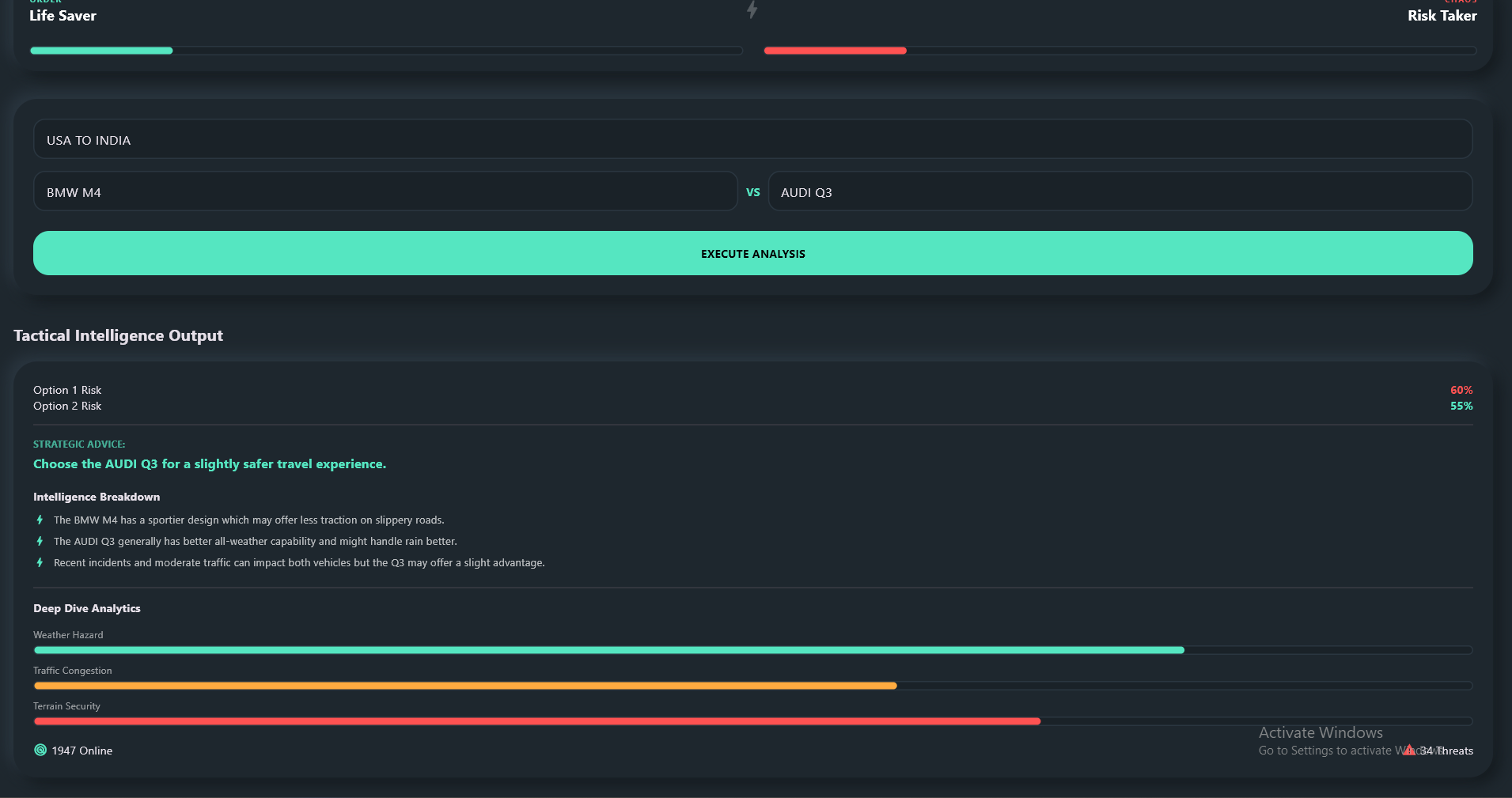
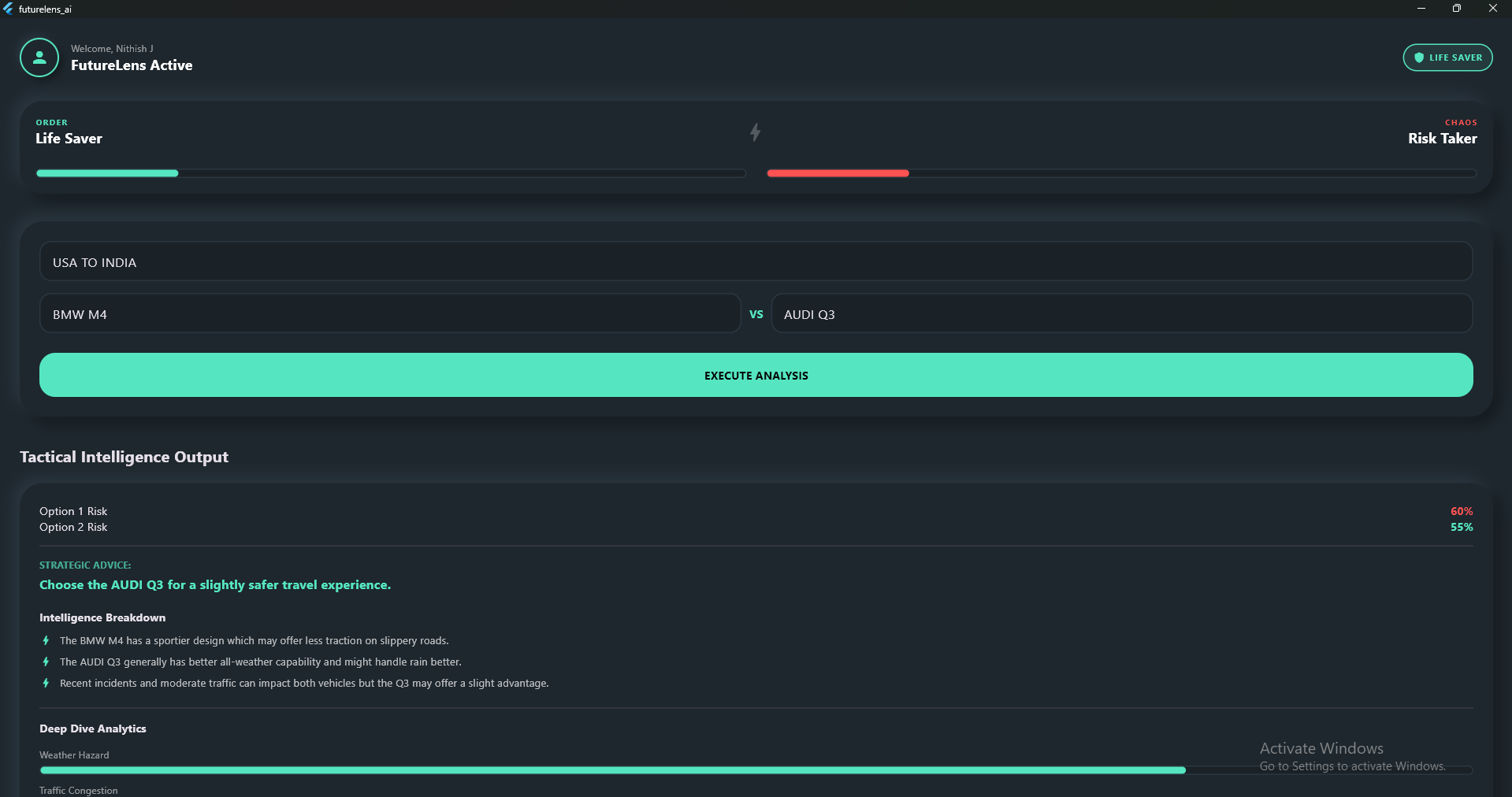
FutureLens AI is a context-aware decision intelligence platform. Instead of a standard chat interface, users input a core decision and pit two options against each other (e.g., Option 1: Bike via Mettupalayam VS Option 2: Bus via Kotagiri).
The system then acts as a tactical advisor:
Context-Aware Visuals: The UI dynamically adapts. If evaluating a trip, it renders a live Satellite Map. If evaluating a financial asset, it plots a Predictive Trend Graph.
Explainable AI (XAI): It doesn't just give a risk percentage; it provides an "Intelligence Breakdown"—a 3-point tactical explanation of why it made that choice.
Deep Dive Analytics: It breaks down the risk into specific vectors like Weather Hazards, Traffic Delay, and Terrain Security.
The Marshall Profiler: It gamifies the user's decision history. By tracking their choices, it places them on a Dual-Path progression system, leveling them up as a "Guardian" (Order Path/Safety) or a "Boogeyman" (Chaos Path/Risk Taker).
How we built it
We engineered FutureLens AI with a robust, scalable architecture:
Frontend: Built using Flutter (Dart), utilizing a custom dark-mode skeuomorphic design language to simulate a military-grade tactical interface.
Backend: Powered by a high-speed Node.js & Express server to handle asynchronous AI requests without blocking the UI.
Intelligence Engine: Integrated with AWS Bedrock, specifically leveraging the Amazon Nova Lite foundational model.
Architecture: We designed a custom Dynamic Micro-RAG (Retrieval-Augmented Generation) Engine. Before hitting the LLM, the backend intercepts the prompt, detects the domain (Aviation, Maritime, Finance, or Transit), and injects simulated real-time telemetry (e.g., crosswinds, sea states, market volatility) directly into the model's context window.
Challenges we ran into
One major challenge was "AI Hallucination" and generic advice. Initially, the AI warned us that stealth fighter jets might face "slippery roads and traffic congestion." We overcame this by building a dynamic routing system in our Node.js backend that feeds strict, domain-specific RAG context to the AWS Bedrock model.
Another challenge was enforcing a strict JSON output from the LLM so our Flutter frontend could flawlessly parse the risk percentages, XAI explanations, and deep-dive analytics without breaking the UI.
What we learned We learned that the true power of GenAI isn't just generating text—it's Decision Intelligence. We learned how to constrain a foundational model using strict JSON schemas, how to manipulate context windows using RAG to ground the AI in reality, and how to use psychological profiling (Order vs. Chaos) to increase user retention and engagement.
What's next for FutureLens AI
Our immediate next steps include replacing the Micro-RAG simulator with live API WebSockets (e.g., AviationStack, live Google Traffic, and real-time market tickers). We also plan to integrate AWS DynamoDB to persistently track a user's "Marshall Rank" across sessions, and implement a feature to generate and export downloadable PDF "Tactical Briefing Reports" for enterprise use.

Log in or sign up for Devpost to join the conversation.