-
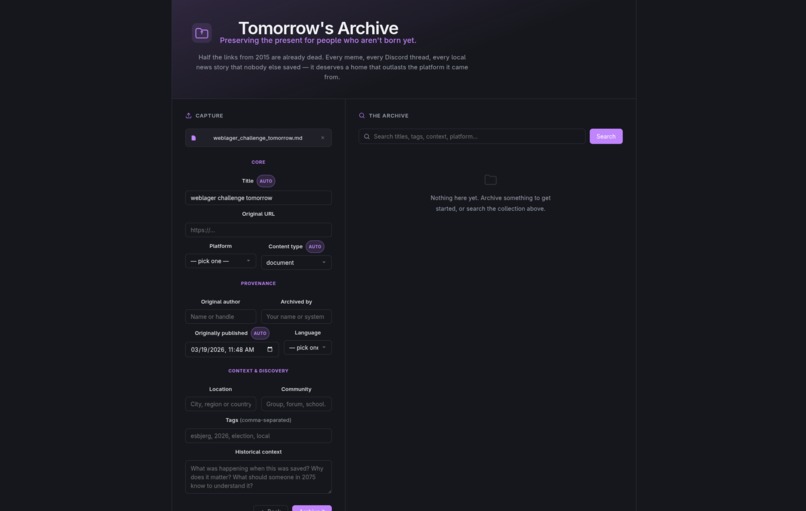
Our streamlined frontend UI
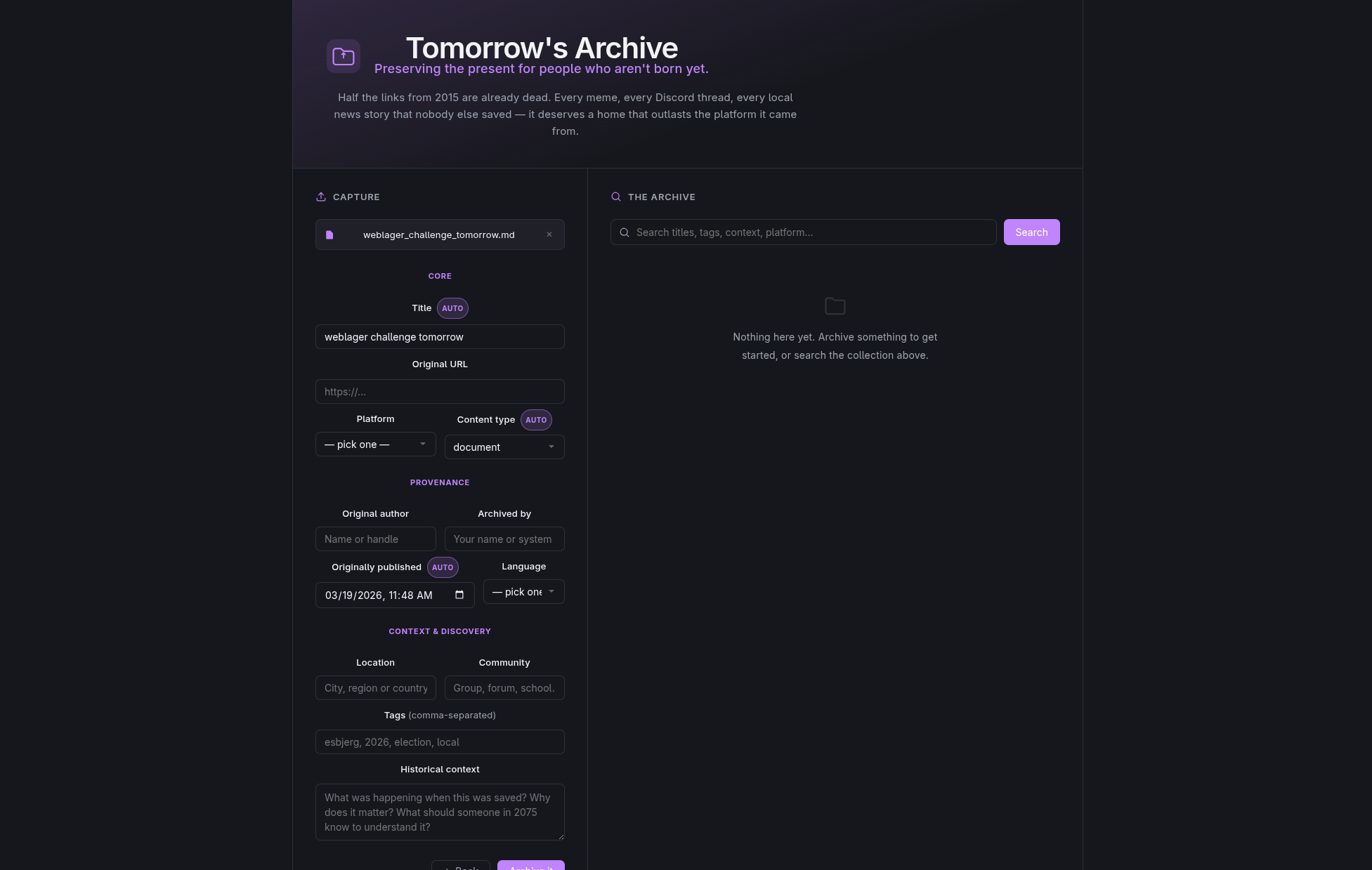
Inspiration Half the links from 2015 are already dead. We were inspired by how much of today's digital culture — memes, local news, community threads — vanishes without a trace, and by the WebLager challenge to build an archive designed for right now, not the past. What it does Future Archive lets users submit and search documents, images, and web snapshots representing life in 2026. An AI layer (Google Gemini) automatically analyzes and describes uploaded images, while OpenSearch powers fast, full-text retrieval across everything stored — making the archive actually findable decades from now. How we built it Backend: ASP.NET Core 10 REST API with two controllers — one for archive document indexing/search (ArchiveController) and one for AI image analysis (AnalysisController) Search: OpenSearch for scalable, structured document storage and retrieval AI: Google Gemini API for automatic image captioning and metadata enrichment Frontend: React + TypeScript (Vite) Infrastructure: Fully Dockerized via Docker Compose Challenges we ran into Getting OpenSearch to play nicely in Docker with security disabled for local dev took longer than expected. Structuring documents so they stay meaningful and searchable in 50 years — not just today — was a surprisingly hard design problem. Accomplishments that we're proud of We built a working end-to-end pipeline: drop in an image, get an AI-generated description, and have it indexed and searchable within seconds. It actually feels like an archive, not just a file dump. What we learned Preservation is more about structure than storage. Saving a file is easy. Saving context — who made it, when, why it mattered — is the hard part. Gemini helped us automate a layer of that context. What's next for Future Archive Scheduled captures of live URLs (before they go dead), community tagging, time-locked capsules that surface content on a set future date, and an embeddable widget so anyone can submit a snapshot directly from their browser.


Log in or sign up for Devpost to join the conversation.