-
-
FUSE Landing Page
-
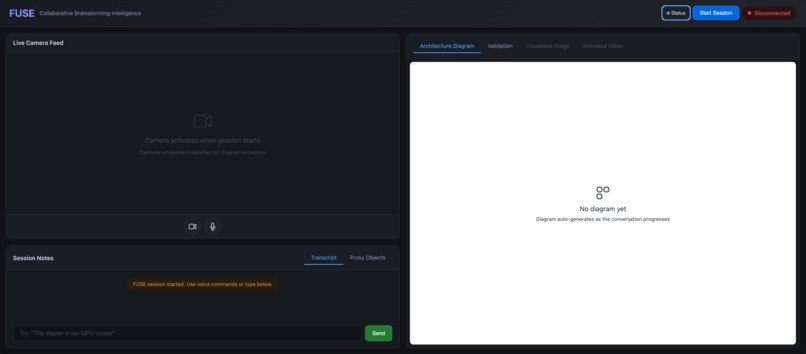
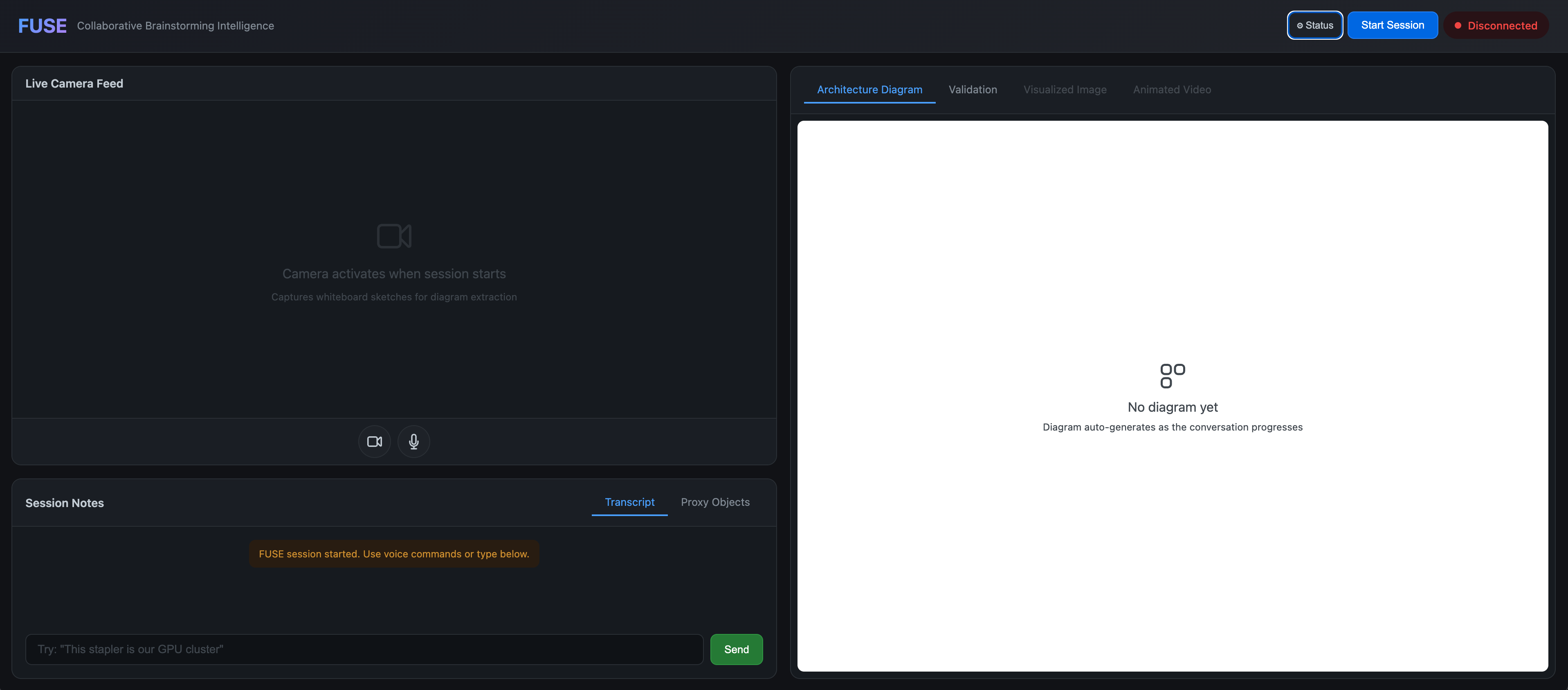
FUSE Session Page
-
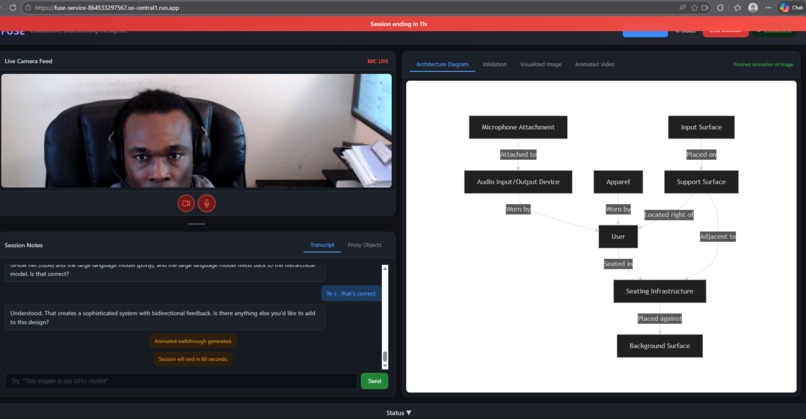
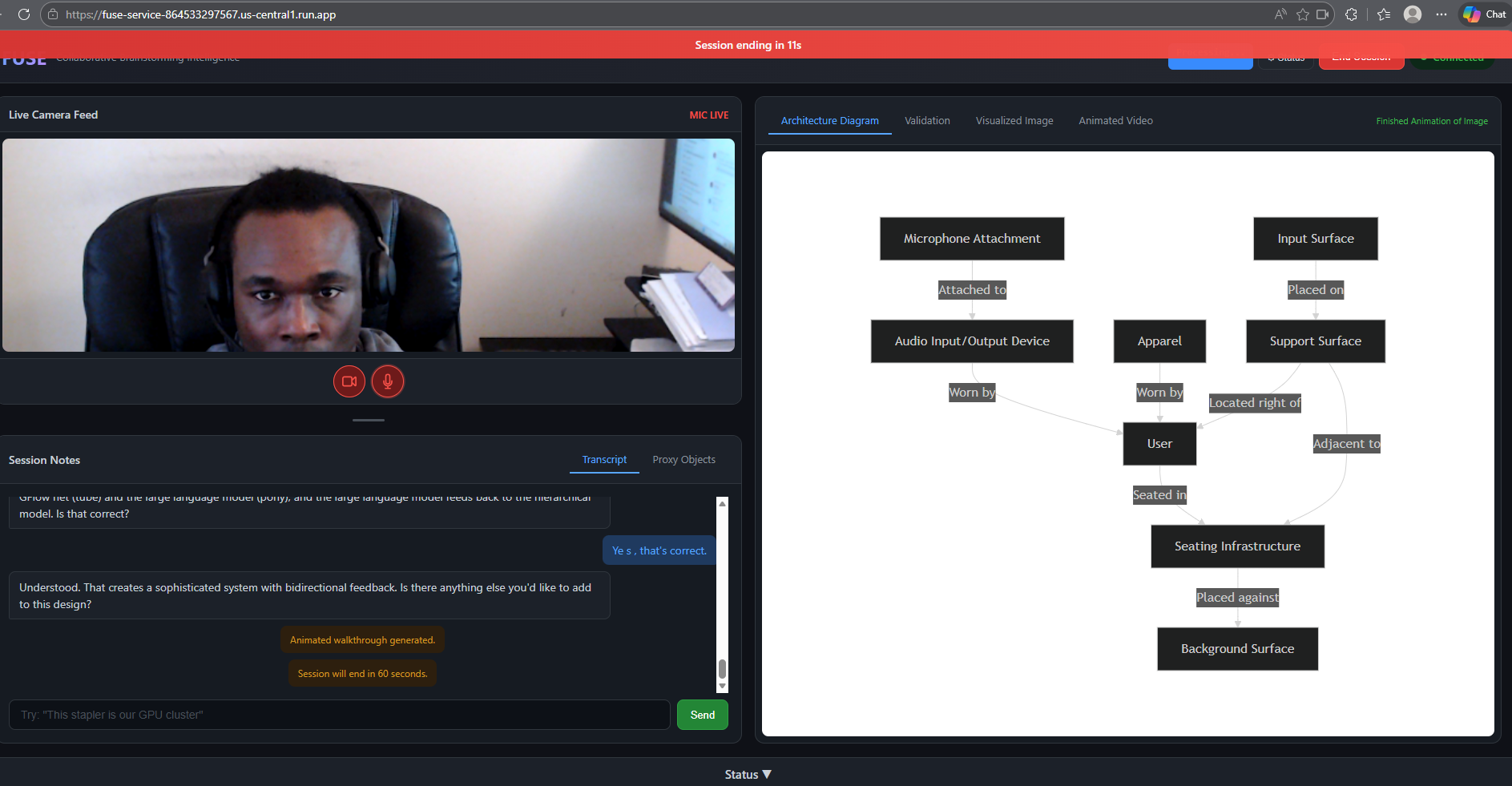
FUSE In Session
-
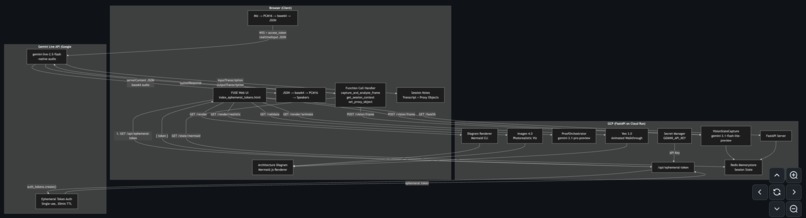
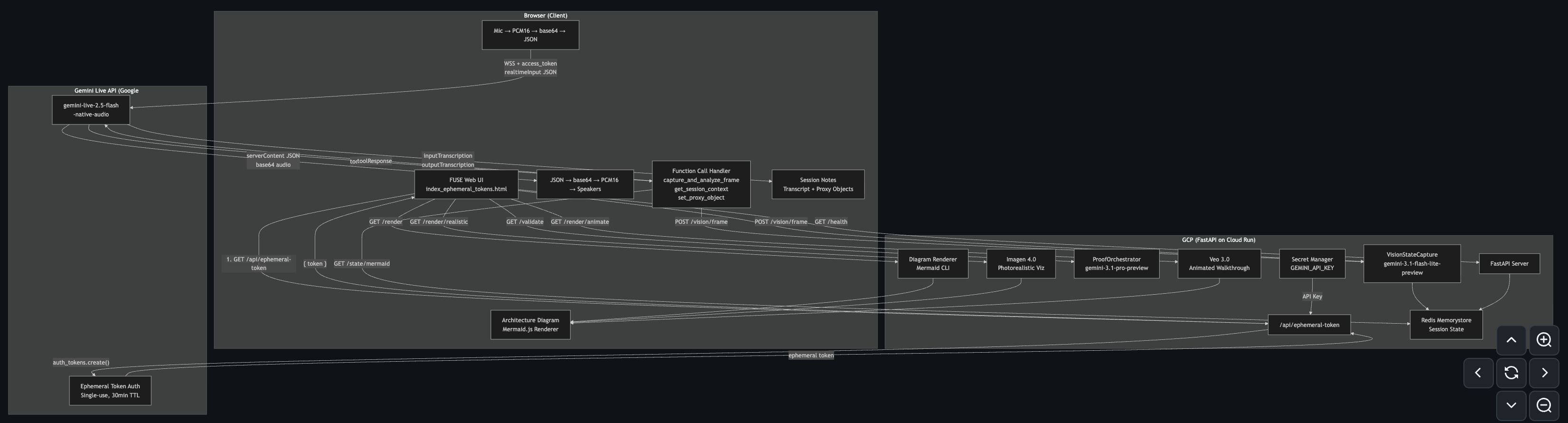
FUSE Architecture
Inspiration
As a Marvel Comics fan, I was captivated by how Tony Stark interacted with JARVIS — voice, holograms, and physical objects all feeding into real-time system design. After building the first iteration of Research Wiz AI (researchwiz.ai), I realized the missing piece was a natural interface where voice and vision could replace keyboards and mice for brainstorming complex technical architectures.
What it does
FUSE lets teams brainstorm system architectures using voice and physical objects in real-time, with Gemini Live converting spoken ideas and whiteboard sketches into validated Mermaid diagrams. You can assign everyday objects as proxy components ("this stapler is our GPU cluster"), and the agent maintains a live, evolving architecture that it validates for logical consistency.
How we built it
We built a FastAPI backend on Google Cloud Run with five Gemini models: gemini-2.5-flash-native-audio for real-time voice via the Live API (using ephemeral tokens for direct browser-to-Gemini WebSocket), gemini-3.1-flash-lite-preview for two-pass vision capture (scene classification + mode-specific extraction), gemini-3.1-pro-preview for architecture validation, Imagen 4.0 for photorealistic diagram visualization, and Veo 3.0 for animated architecture walkthroughs. The frontend connects directly to Gemini for audio/video streaming via ephemeral tokens, while using the FastAPI server for vision processing, diagram rendering, validation, and visualization. Session state persists in Redis (Memorystore), and the API key is secured via GCP Secret Manager — never stored in code.
Challenges we ran into
Our biggest challenge was achieving stable real-time audio with the Gemini Live API. We initially built a server-to-server architecture where the FastAPI backend proxied all audio between the browser and Vertex AI's Live API. This double-hop relay introduced persistent WebSocket 1007 ("invalid audio format") and 1008 ("policy violation") errors caused by timing mismatches when audio frames arrived during session transitions, race conditions during pending tool calls, and an UnboundLocalError that crashed sessions after exactly 5 responses.
After 31 issues and extensive debugging — including A/B testing audio-only vs audio+video, latency instrumentation, session resumption with transparent handles, server-side VAD tuning, and context window compression — we pivoted to ephemeral tokens for direct browser-to-Gemini WebSocket communication. This eliminated the server-side audio proxy entirely. But the ephemeral token path brought its own challenges: Gemini sends all WebSocket messages (including JSON) as binary frames (not text), the BidiGenerateContentConstrained endpoint requires ?access_token= (not ?key=), and the proactiveAudio feature doesn't reliably trigger the model to speak first (we solved this with a delayed realtimeInput.text trigger).
We also learned that response_modalities must be ["AUDIO"] only — adding "TEXT" causes silent failures — and that the browser's getUserMedia API requires HTTPS or localhost, which silently blocks mic/camera access on plain HTTP.
Accomplishments that we're proud of
We achieved a seamless voice-to-diagram pipeline where you can speak an architecture into existence and see it render in real-time. The proxy object system — where physical items become architecture components — feels genuinely novel and makes brainstorming tactile and collaborative.
What we learned
Building with the Gemini Live API's native audio mode requires a fundamentally different approach than text-based APIs — you're working with real-time audio streams, video frames, and function calls, not structured request/response cycles. We learned that server-to-server audio proxying introduces fragile timing dependencies that direct client connections eliminate. We discovered that ephemeral tokens provide a secure, reliable bridge between server-side API key management and client-side real-time streaming. And we learned that multimodal fusion (voice + vision + state) creates emergent capabilities that neither modality provides alone — when the model can see, hear, and call functions simultaneously, it becomes a genuinely useful brainstorming partner.
What's next for Fuse (The Collaborative Brainstorming Intelligence)
We plan to introduce FUSE as commercial product for both B2B and B2C domains.
Built With
- css
- docker
- ephemeral-tokens
- fastapi
- gemini-2.5-flash-native-audio
- gemini-3.1-flash-lite-preview
- gemini-3.1-pro-preview
- google-artifact-registry
- google-cloud-memorystore-(redis)
- google-cloud-run
- google-cloud-secret-manager
- google-gemini-live-api
- google-genai-sdk
- html
- imagen-4.0
- javascript
- mermaid.js
- python
- veo-3.0
- websockets

Log in or sign up for Devpost to join the conversation.