-
-

Full Wiki Project
-
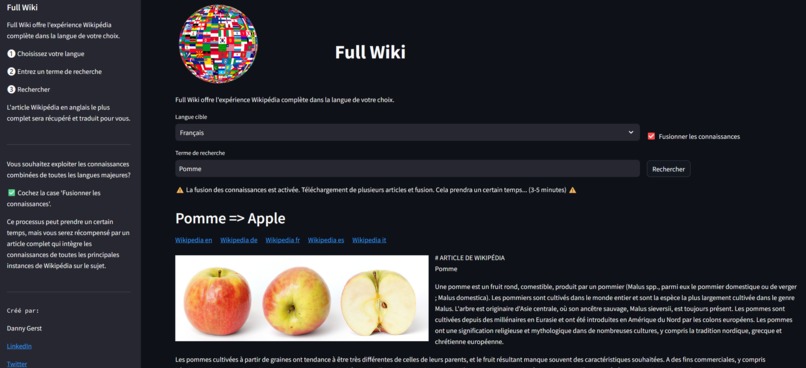
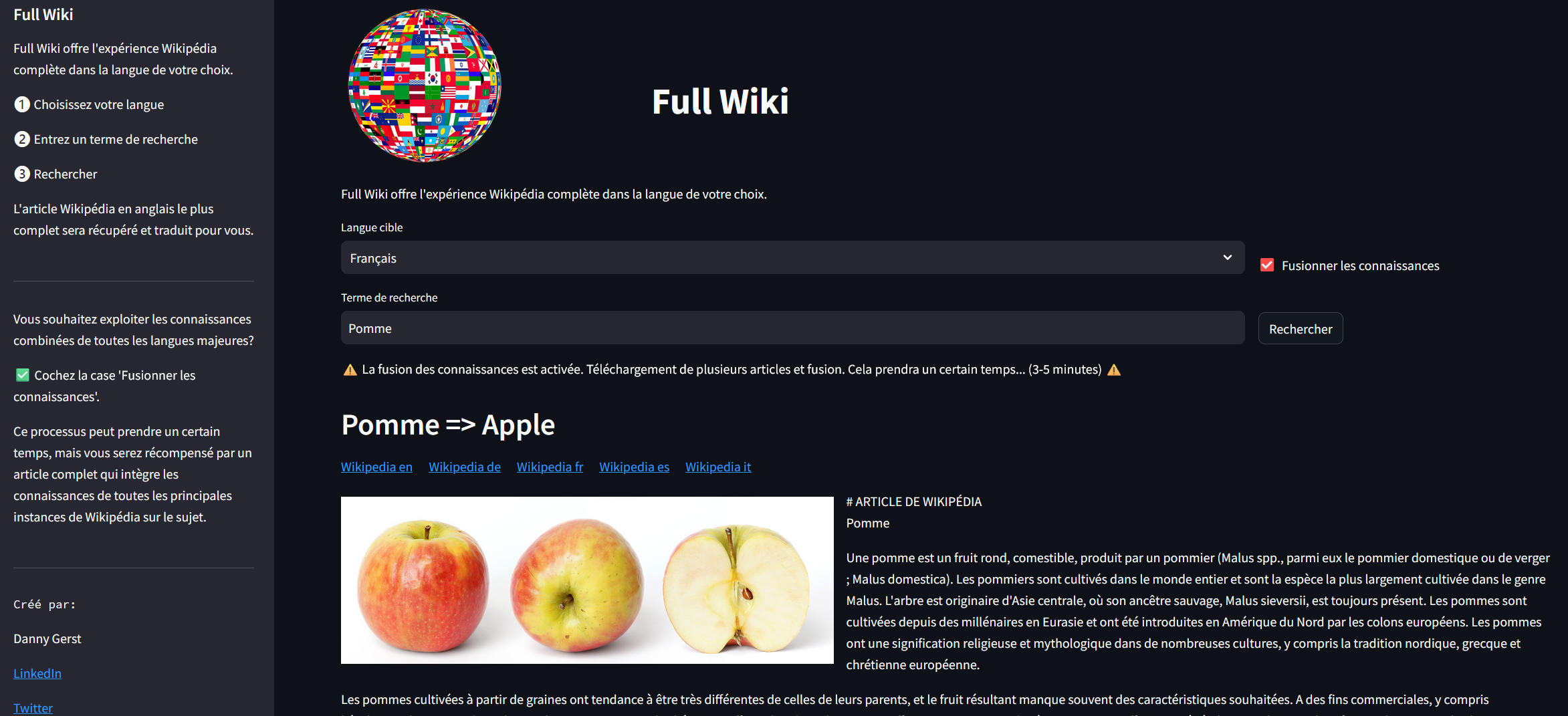
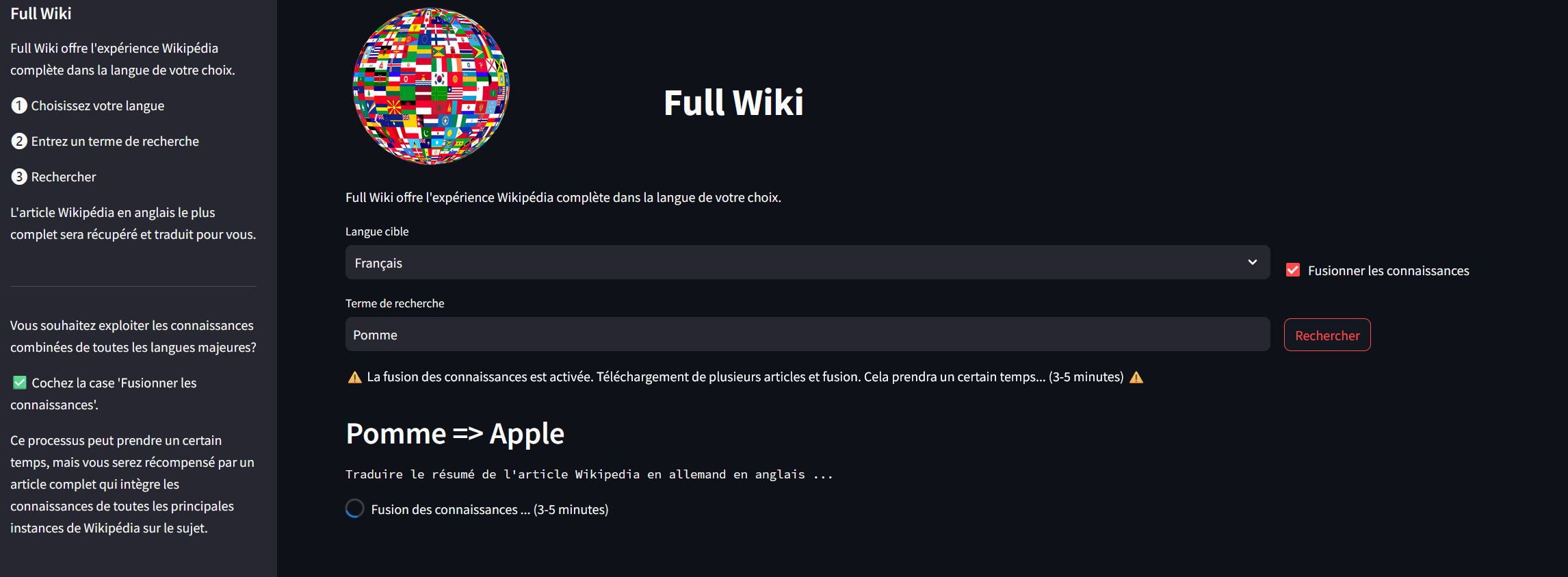
Searching all wikipages for Apple with French search term Pomme
-
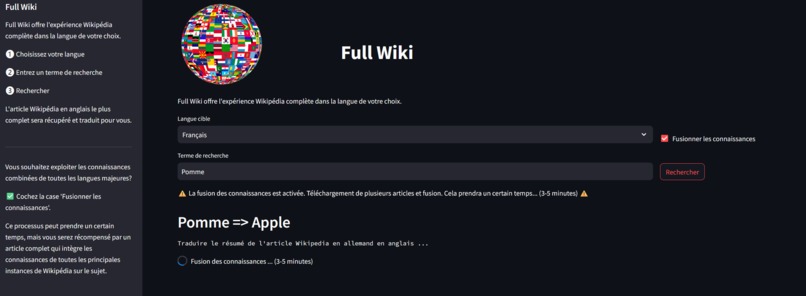
Searching all wikipages for Apple with French search term Pomme
-
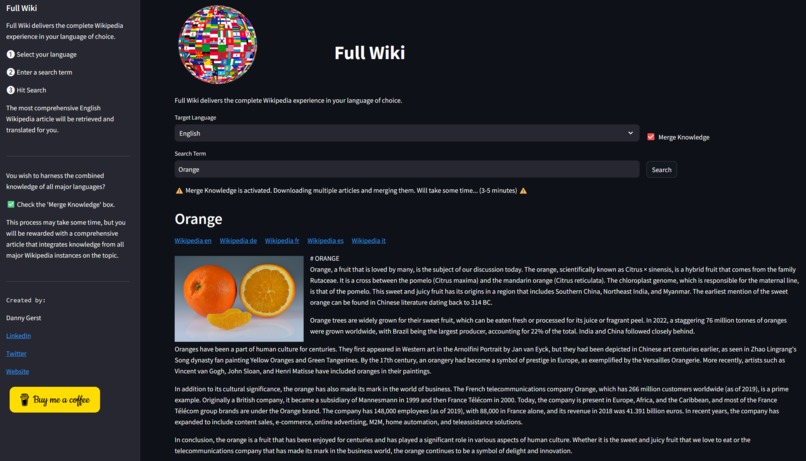
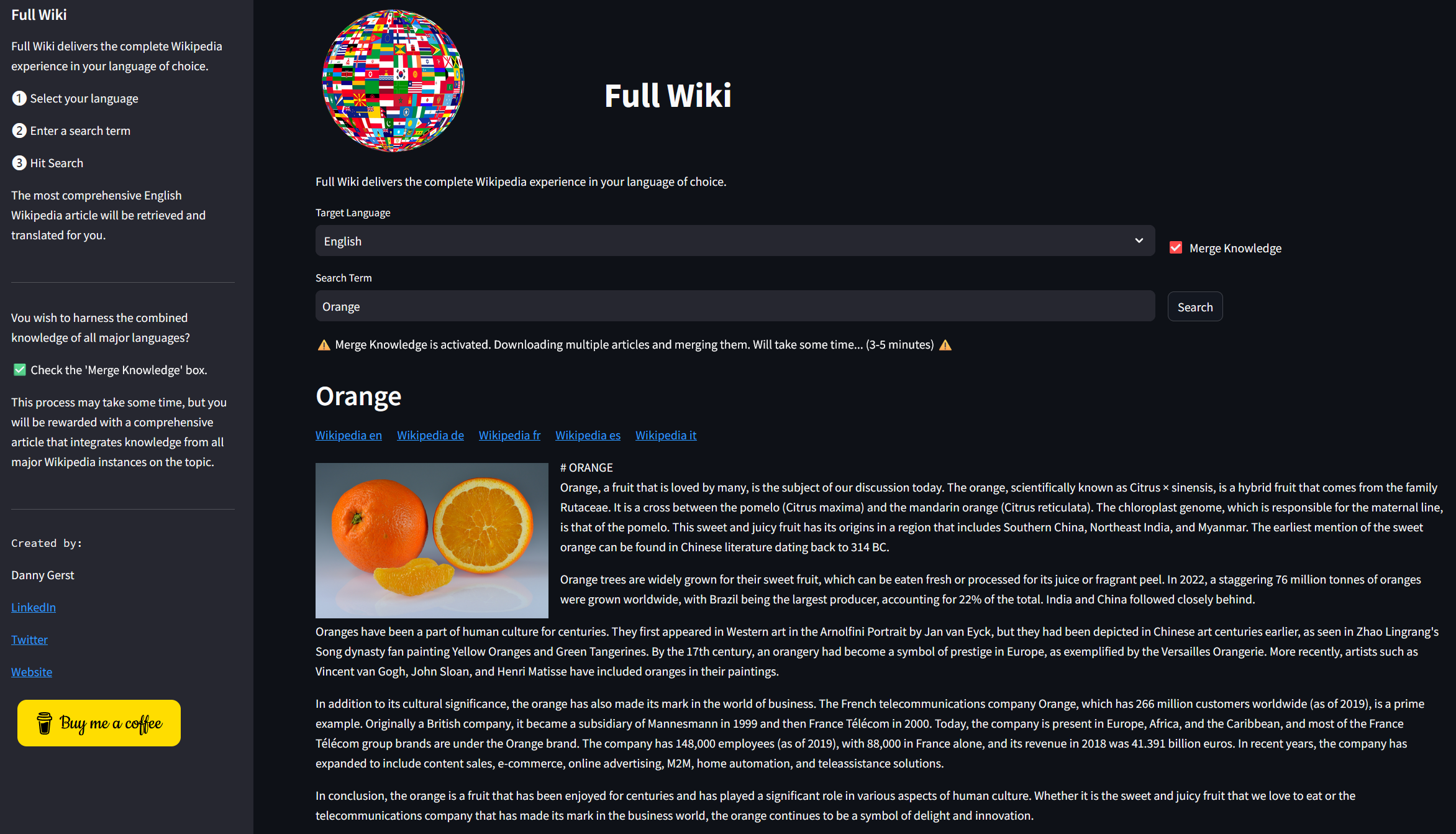
Combined Knowledge Search for Orange in English. See the list of all references wikipages
-
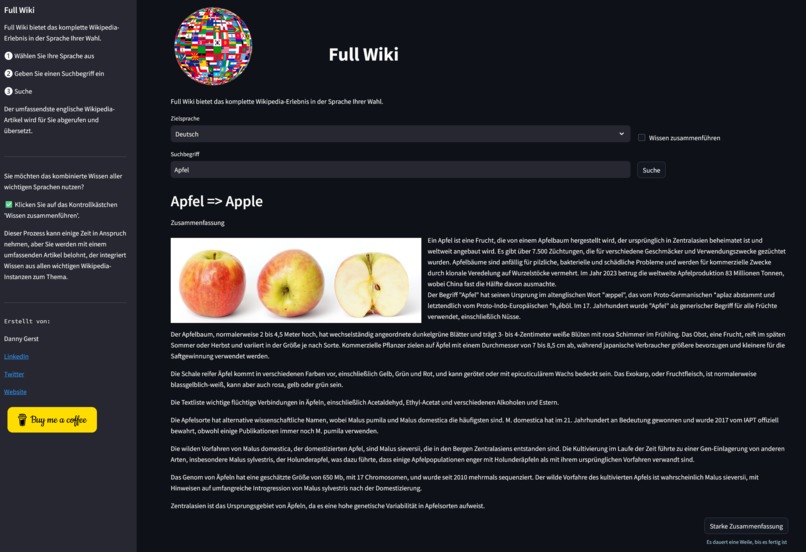
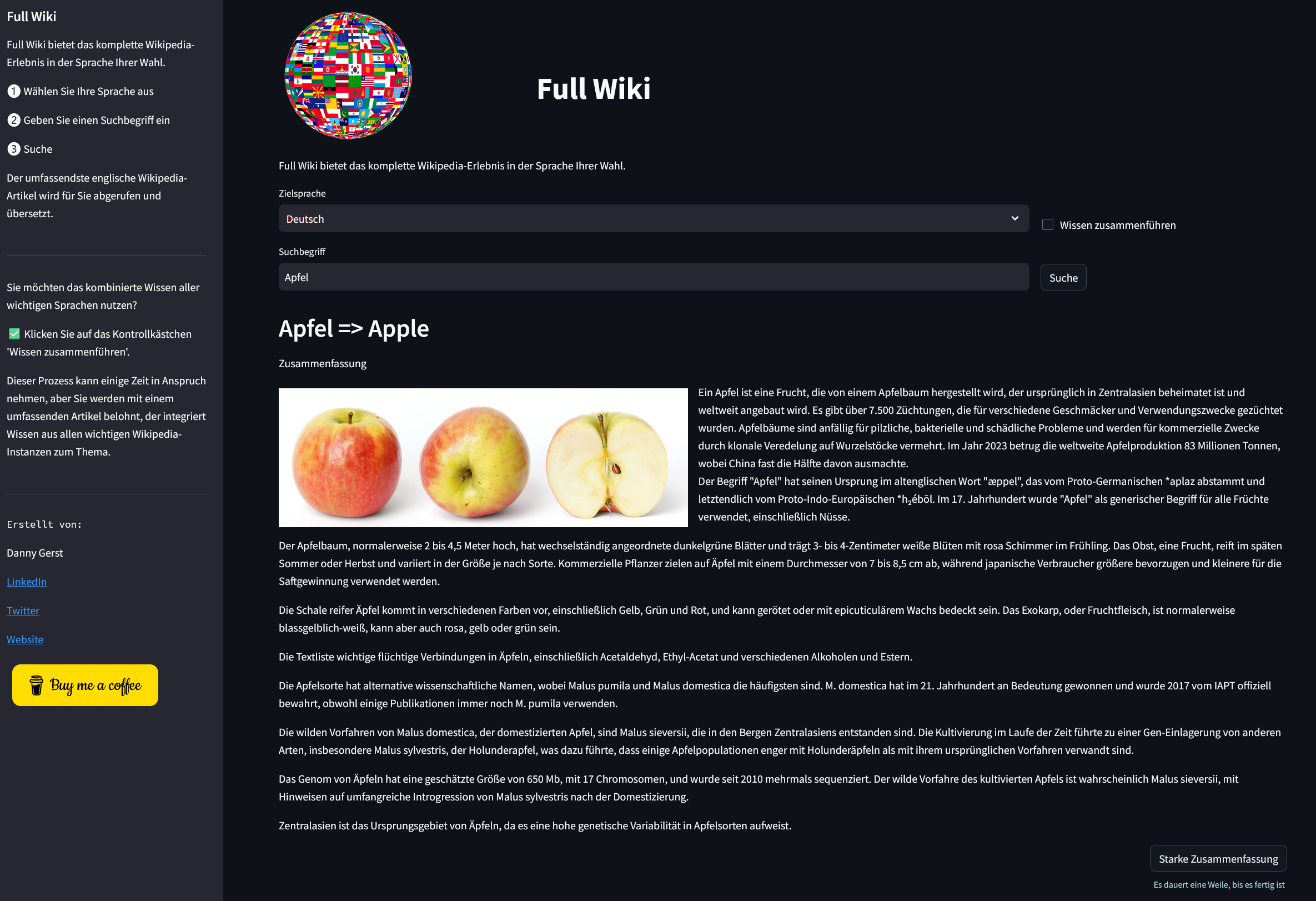
Searching for Apple with German search term Apfel

Welcome! 🎉
My name is Danny Gerst, and I've been developing software for over three decades. My philosophy is simple: don't do what a computer can do better. This principle has driven me towards the realm of automation with and without AI.
Inspiration 🌍
Ever fantasized about having fairy-given superpowers? My top pick would be the power to speak and understand every language on the planet! Unfortunately, my mind operates more like that of a scientist—great at deduction but poor at retention. Consequently, learning new languages has always been a challenge for me. However, the advent of machine learning introduced a revolutionary possibility: the ability for everyone to understand each other. The development of transformer technology, which enhances machine translation, has truly excited me.
Gratitude and Opportunity 🙏
Thank you for the chance to dive into the Arctic architecture during this hackathon. In today’s AI-driven era, we can knock down language barriers. State-of-the-art language models deliver high-quality translations at minimal cost, encompassing numerous languages and often outperforming tools like Google Translate or DeepL. These models even grasp cultural nuances, which is a game-changer. Although inference speed once posed a challenge for meaningful exchanges over large text volumes, it's rapidly improving, setting new standards for real-time communication. The Arctic model's inference speed is also notably above average.
Introducing Full Wiki 🔥
Today, I am excited to present the project Full Wiki. Imagine accessing the deepest corners of Wikipedia in any language, without ever missing out on details obscured by language barriers.
What Full Wiki Does 🌐
Wikipedia is the global cornerstone of knowledge, but it's not a centralized repository. Instead, information is spread across various country-specific Wikipedia instances. Often, the most comprehensive data resides on English Wikipedia, which leaves non-English speakers at a disadvantage as their local versions might not offer as much depth.
Full Wiki bridges this gap by initially allowing the translation of English Wikipedia entries into four major languages: German, French, Spanish, and Italian. While translating the search term as well. To avoid long wait times associated with full-page translations, Full Wiki tackles this challenge section by section. This give the user a more interactive experience. It relies heavy on a caching system to conserve both Wikipedia and AI resources, ensuring that response times are virtually instantaneous as more data is processed as well.
To enhance user interaction, I've begun implementing aesthetic improvements such as displaying an infobox image and considering an additional infobox on the right side of the page. These enhancements significantly improve the user experience.
Beyond mere translations, Full Wiki unleashes the classical potential of models like Artic by including a summarization task: it first condenses entire Wikipedia texts into English, then either translates these summaries into other languages or presents them directly to English-speaking users.
More Than Just Translations 📚
But what if Full Wiki did more than just translate? What if it aggregated the knowledge from all Wikipedia instances? This way, even an English-speaking user could access information that is available in the French Wikipedia but not in the English version. To facilitate this, I have created the "Combined Knowledge" checkbox. With this feature, when a search term is entered, articles from the four largest Wikipedia instances are downloaded, summarized, and the knowledge extracted.
Right now this is implemented for the leading section.
Thus, Full Wiki contributes to making knowledge accessible globally, ensuring that no valuable insight due to languages barriers.
Challenges 🚧
Every new technology brings its unique challenges. For instance, integrating the Arctic model required navigating Snowflake's Cortex API—a challenge in itself. It took some time to master using the LLM through this interface. You might wonder why not use Replicate, known for its ease of use? Simply put, I'm driven to maximize resources. Since translations consume a significant amount of tokens, and Snowflake offered unlimited access until June, it became the best choice.
Prompt engineering posed another significant challenge. Each model processes instructions differently. To enhance translation quality, texts were divided into smaller segments.
Time is precious, as are the resources of both LLMs and Wikipedia. Therefore, leveraging caching became crucial. So I have implemented a caching system fro Wikipedia pages and translated content. This cache is shared, so after it is warmed up results are nearly instant.
Implementing section-wise translation was important for a good user experience, offering a more interactive feel. However, this required adjustments to the wikipedia Python lib to function as needed—a more complex task than thought.
Moreover, I encountered unexpected hurdles with app internationalization due to the lack of straightforward Python libraries; this led to a built-in solution, sparking the idea for a more comprehensive project.
Additionally, transforming Wikipedia's markup language to Markdown remains an ongoing challenge. Still there a some glitches.
Lessons Learned 📚
The abundance of libraries available doesn't guarantee a seamless development process. Often, you need to tweak or even overhaul a library to meet specific project needs—as I did with the Wikipedia Python library.
I was suprised that there is no easy to use internationlization lib for Python. A lot of thought came into my mind. Like using a combined technique to translate labels on the fly to ensure a more complete translation and you could plugin new languages very easy.
Streamlit proved to be an invaluable tool for rapid prototyping. Initially, I was concerned about the complexity of adding unique styling, but it turned out to be easier than expected.
What's Next? 🚀
Imagine a world where every piece of digital content, regardless of its original language, is instantly accessible to everyone. This isn't just a dream; it's within our reach, thanks to the architecture of Artic. Allow me a moment to share a yet-to-be-discussed benefit of this technology— that could redefine how we interact with information globally.
The Untapped Potential of Artic's Architecture 🌐
The vast majority of internet content—over 50%—is in English. Therefore, the technical capabilities of large language models (LLMs) like Artic mean we get the best prediction in englisch than in any other languages. Concentrating on English only, we leverage the richest datasets available and the best performance of an LLM. This could be name as the central knowledge repository. Even if we would translate content from other languages to englisch. But the core would be in englisch alone.
A Cascade of Linguistic Expansion 📈
By training a multitude of translation experts around that, we can create a bidirectional translation functions between English and other languages. The advantage here is that each expert enables various translation permutations. For example, translating from German to English and then from English to Spanish inherently provides the function for direct German-Spanish translations without additional training. With each new language added, our model doubles its linguistic capabilities.
Economical and Efficient Scaling 🔍
The beauty of Artic’s approach lies in its cost-effectiveness. Rather than training a colossal model on all languages—which is both resource-intensive and costly—with this architecture we can focus on optimizing smaller, more specialized 'translation experts.' These experts work in concert, each enhancing the model's overall performance. As better data becomes available, these experts can be improved individually, avoiding the need to retrain the entire system. I would bet that this approach would bet METAs SeamlessM4T.
Why This Matters Now 💡
This method mirrors the way DALL-E 3 from OpenAI, uses English prompts to create accurate images even if the inital prompt was in another languages. Similarly, Artic could uses this English-centric knowledge to maintain consistent quality across translations, making it uniquely suited to today’s globalized internet.
Before this project I've envisioned a mix of models approach with the challenge to auto-pick the right modell, but Artic’s architecture inherently integrates this capability.
What a great Journey this would be🌟
As we continue to refine and expand Artic's capabilities, the implications for global communication and information sharing are profound. Instead of chasing the holy grail of AGI lets concentrate of things that real will have an impact for all humanity.
Thank you for your time. I invite you to explore Full Wiki.
What an incredible time to be alive!
Disclaimer
This is a rapid prototype to show a proof-of-concept. It works for major terms like Nvidia, Snowflake, Python ... but error handling is nearly not existing. So expect to see one here and there.
Built With
- arctic
- llm
- python
- snowflake
- streamlit


Log in or sign up for Devpost to join the conversation.