-
Still working on it
Book Genre Classification Inspiration Classifying books manually into genres is time-consuming and inconsistent. This project automates genre classification using Machine Learning and Natural Language Processing (NLP) to improve efficiency.
What We Learned
- Preprocessing textual data for ML models.
- Feature extraction using TF-IDF and word embeddings.
- Training and evaluating a text classification model.
- Handling imbalanced datasets in classification problems.
How We Built It
- Data Collection:
- Used an open dataset from Goodreads/OpenLibrary containing book titles, descriptions, and genres.
- Preprocessing:
- Removed stopwords, punctuation, and applied lemmatization. 3.Feature Extraction:
- Converted text into numerical features using TF-IDF (Term Frequency-Inverse Document Frequency.
- Model Training:
- Trained Logistic Regression, Random Forest, and SVM classifiers.
- Evaluation & Optimization:
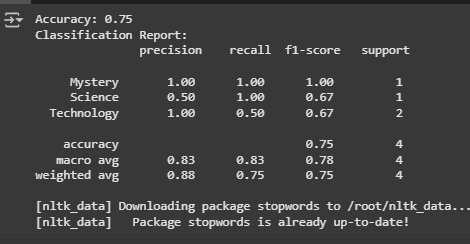
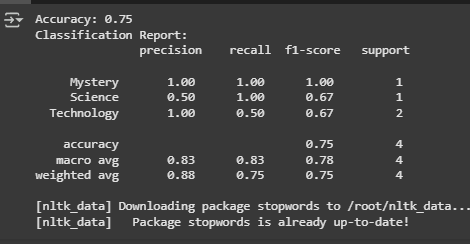
- Measured performance using accuracy, precision, recall, and F1-score.
Challenges Faced
- Handling imbalanced data, where some genres had fewer books than others.
- Improving accuracy by choosing the best feature extraction method.
- Optimizing the model to avoid overfitting.
Built With
- Languages & Libraries: Python, Pandas, Scikit-learn, NLTK, Matplotlib
- Dataset: OpenLibrary Dataset / Goodreads Dataset
- Model: Logistic Regression / SVM / Random Forest
- Platform: Google Colab / Jupyter Notebook
Built With
- languages-&-libraries:-python
- nltk
- pandas
- scikit-learn

Log in or sign up for Devpost to join the conversation.