-
landing page
-
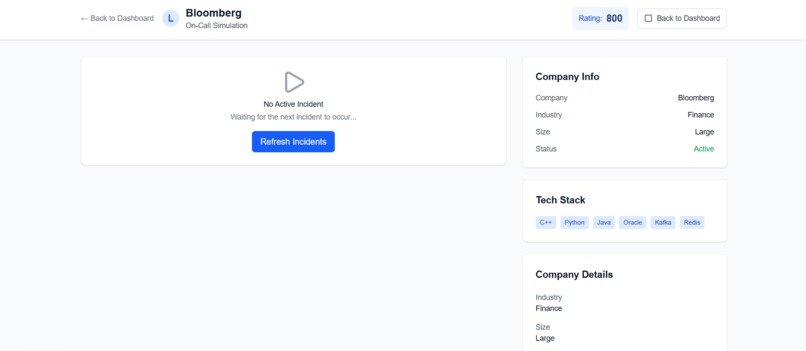
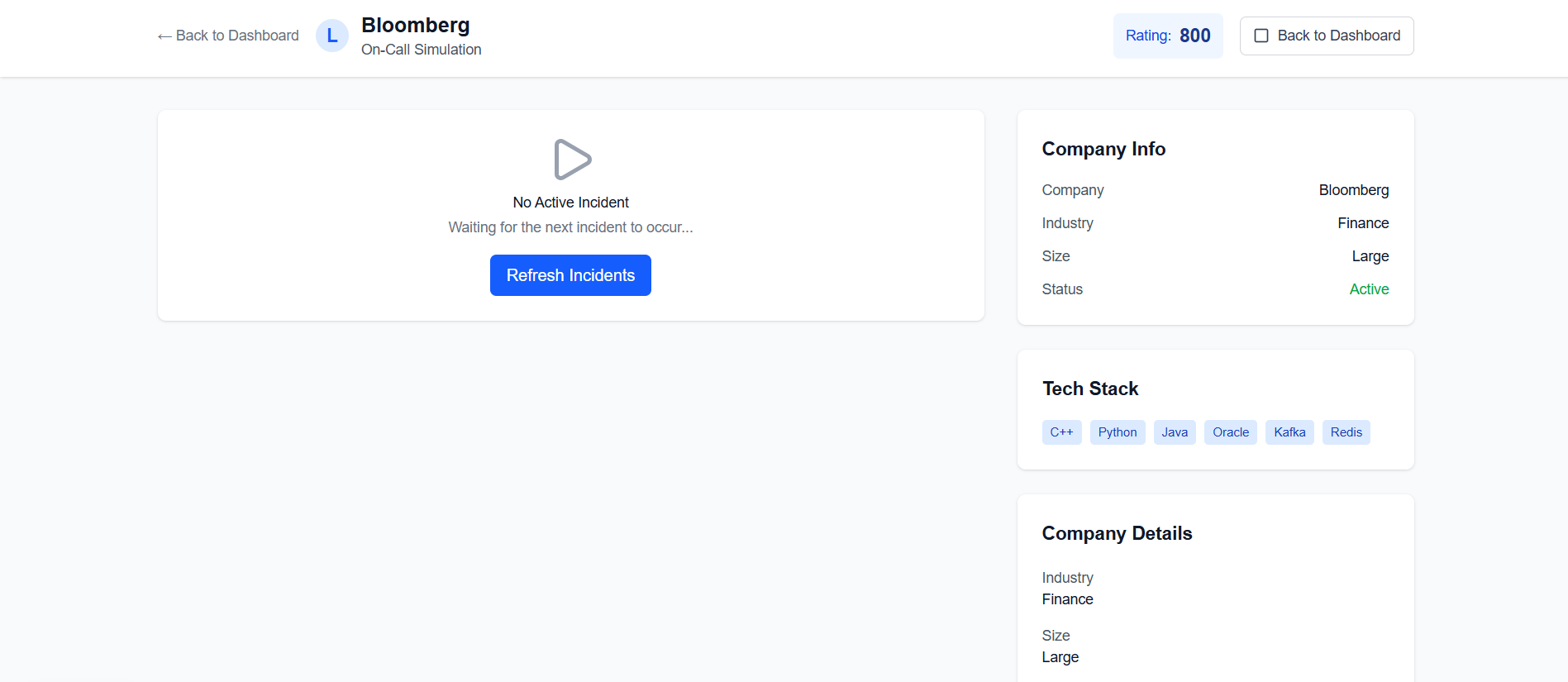
a page where an engineer (under training) is staying ready for the next incident that needs response
-
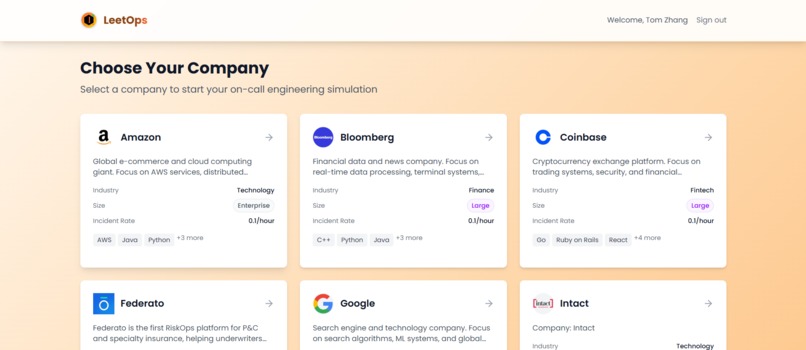
Inspiration
Having interned at 3 tech startups (one of them being a YC W24 company), I have witnessed firsthand the critical gap between theoretical knowledge and real-world incident response capabilities. The tech industry faces a massive problem: how do we objectively measure and train engineers for one of the most crucial, yet overlooked, skill in modern software development: handling incidents? The traditional coding interview tests algorithmic thinking, but they don't prepare engineers for the high-pressure, time-critical scenarios they face on-call. Companies lose millions due to prolonged outages, and engineers struggle to gain credibility in incident response without real experience. The inspiration came from seeing brilliant engineers that I have worked with freeze up during their first incident, while others with less technical depth but better incident response training thrived. After improving myself in incident response through tireless practice, I decided there needed to be a way to democratize this critical skill and create a new currency of engineering credibility.
What it does
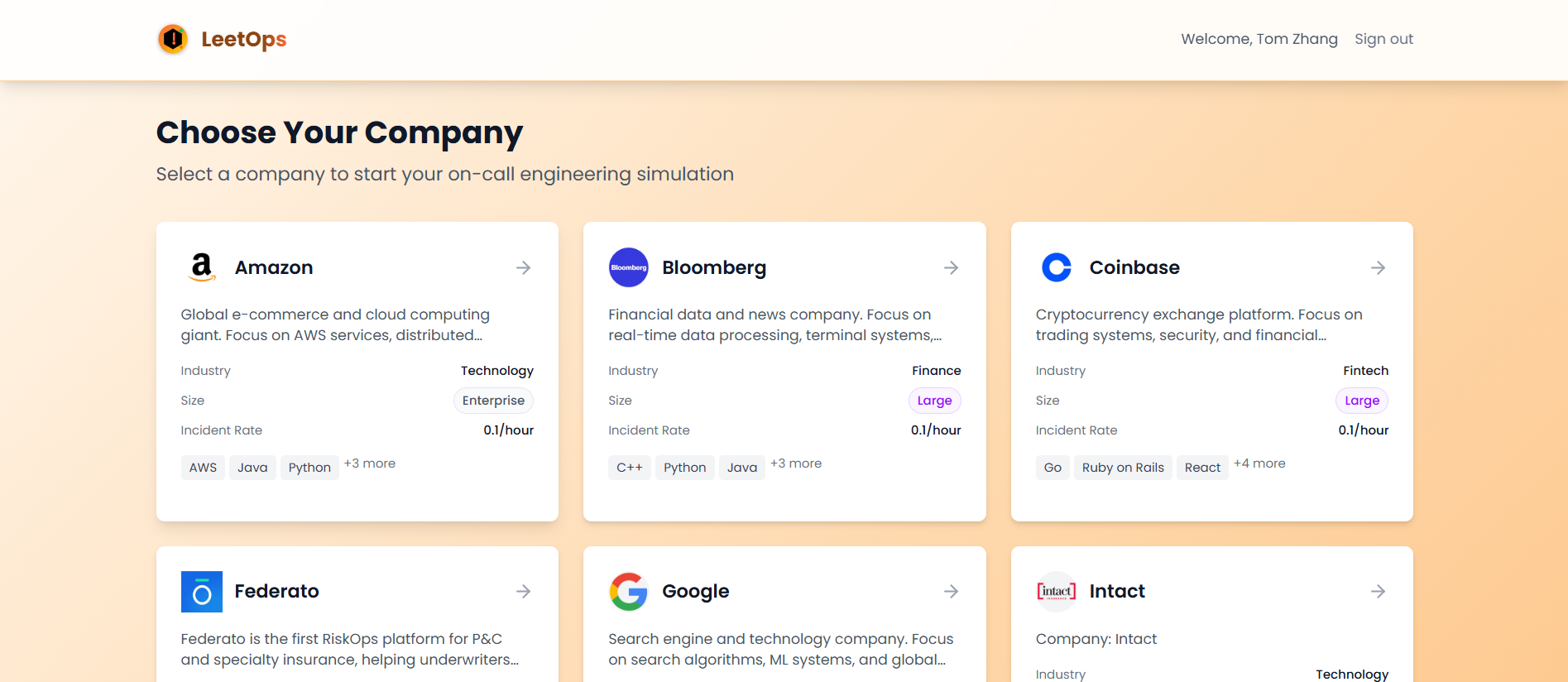
LeetOps is the world's first standardized platform for benchmarking on-call engineering credibility. Think of it as "LeetCode for incident response", but instead of solving algorithmic puzzles, engineers handle realistic production incidents across dozens of major tech companies and rising startups. Each user has a "LeetOps ELO" which is a benchmark they can use to prove their on-call reliability as well as for companies to leverage when comparing candidates.
The core feature is we simulate a real work day (typically 9 AM - 5PM). Engineers in training must stay engaged (they can't leave for too long), mirroring real on-call responsibilities. Once a problem pops up on their screen, the clock ticks down and they must enter an answer to the "resolution notes". After they submit, a language model will then assess the grade, provide educational feedback, and determine an increase/deduction in the engineer's "LeetOps ELO". The algorithm grades their answer based on technical accuracy of the solutions, problem-solving approach, communication clarity, efficiency and best practices. Finally, they wait patiently and readily for the next incident that may pop up after a random time interval.
How we built it
We first began by talking to all the sponsors at the hackathon to better understand incidents that occur at their respective companies and what they do in response to them. In addition we also inquired whether the company were willing to give consent in putting example incidents on our platform related to them for engineers to practice with. In the end, we tailored around 15 incidents to test the platform using the data that we gathered from sponsors including Amazon, Bloomberg, Coinbase, Federato, Intact, Rox, Shopify.
As for the tech stack, we used Next.js with App Router for the frontend to optimize performance. Typescript for type safety and developer experience. Tailwind CSS for modern UI. Django REST framework for robust API endpoints. Groq API with Llama-3.3-70b for fast, accurate grading.
Challenges we ran into
We first set out to assess the code people write during incident response as well as the DevOps, but quickly realized that incidents rarely have a single right solution (even the same issue can demand different actions). This resulted in us pivoting to assessing incident response instead of code/DevOps. Next, we ran into some challenges figuring out examples of incidents at certain companies but through patience (and a lot of time waiting in lines at Sponsor Bay), we were able to gather valuable data from them.
Accomplishments that we're proud of
We are proud that we used real-world examples of incidents from real companies (shoutout to ALL of them for helping sponsor Hack the North 😊😊) like Amazon, Bloomberg, Coinbase, Federato, Intact, Rox, RBC, Shopify so that engineers who eventually use our platform are getting genuine value and learning.
What we learned
One of the profound learning points we had is that incident response is a crucial skill that companies look for in engineers (software engineers especially). Companies like RBC emphasized to us that outages and poor incident response not only led to companies losing money but losing the more valuable currency: reputation.
What's next for LeetOps: The New Currency of Engineering Credibility
Our next steps include deploying this tool for early test users. Our target audience are early career software engineers or anyone looking to improve their incident response acumen in software engineering. Our end goal is to make real-world impact for the people we aim to serve: engineers, companies, and the industry.
For Engineers: build credible incident response experience without waiting for real ones
For Companies: identify and efficiently compare candidates with proven incident response capabilities and benchmarks
For the industry: create the next standardized metric and benchmark for the one of the most critical, but yet overlooked, engineering skill
Last but not least, we will aim to add more security and integrity to the application. This means we will add more verification and stringent measures to mitigate instances including, but not limited to, cheating, misuse, abuse, on our application.
Built With
- django
- groq
- javascript
- mysql
- next.js
- rest
- typescript





Log in or sign up for Devpost to join the conversation.