-
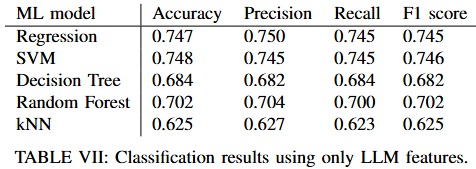
Classification results using only LLM features.
-
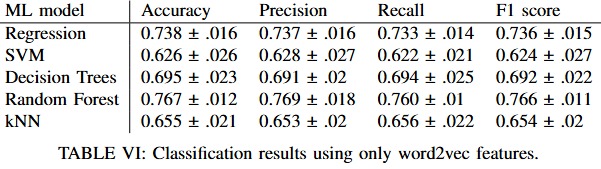
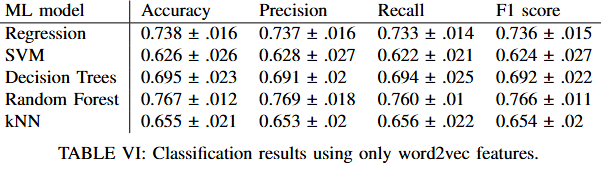
Classification results using only word2vec features.
-
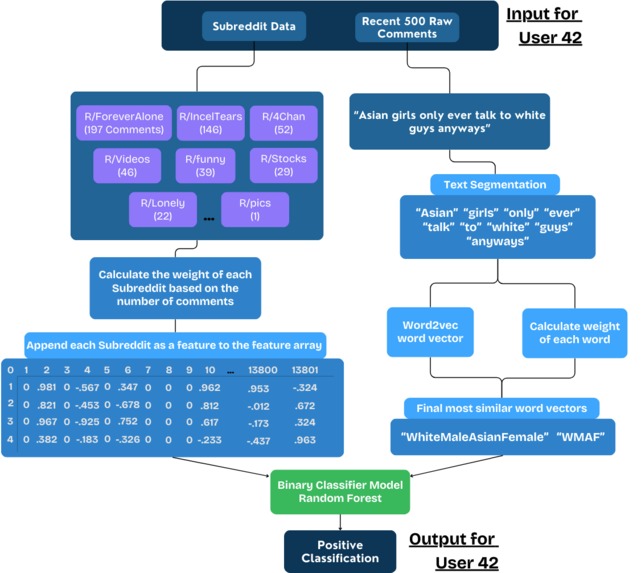
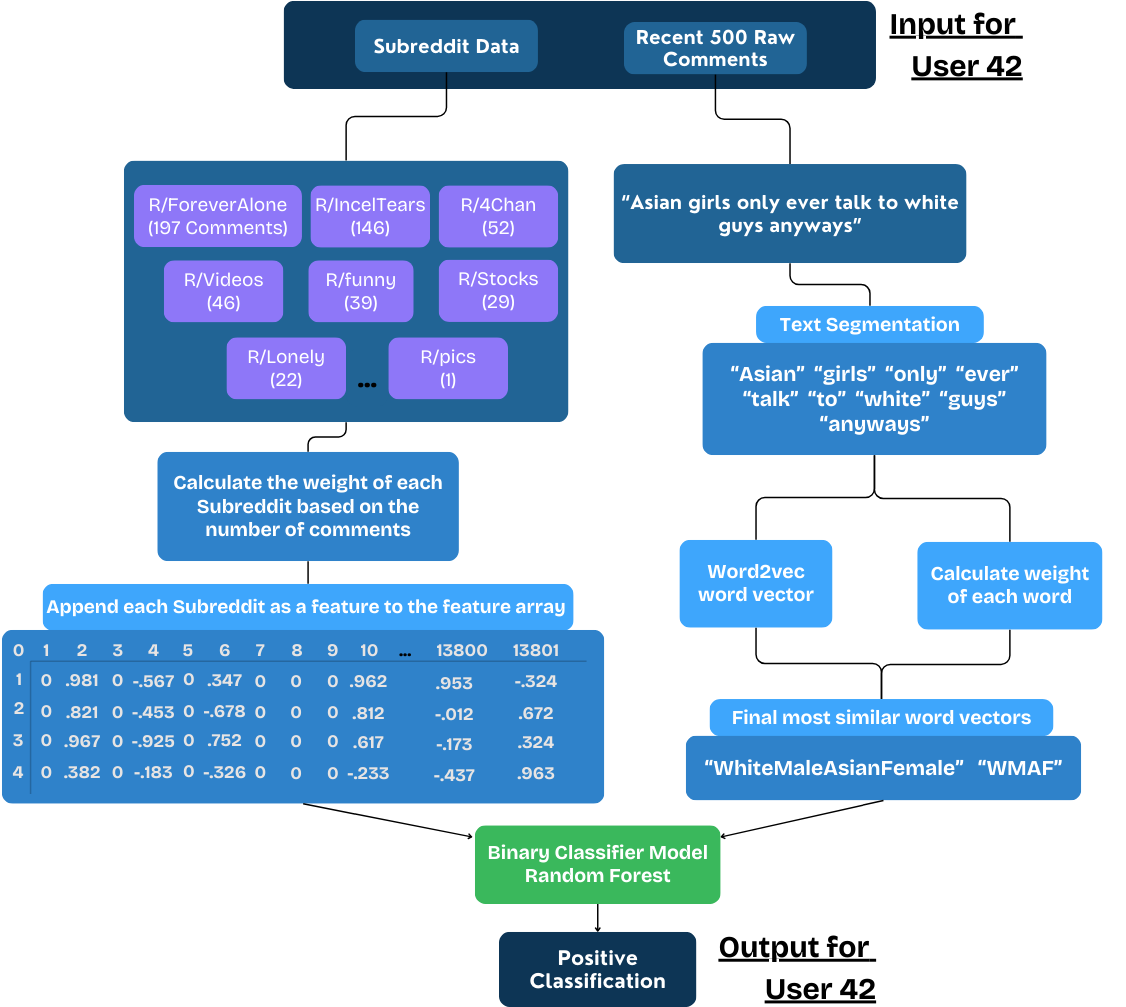
Flow diagram of the inference phase of the hybrid approach model.
📝 Inspiration
My original project on incel behavior detection implemented a mix of subreddit activity and comment text embeddings via Word2Vec. The approach achieved 99% accuracy, but the BigData conference reviewer #2 complained about not using large language models (LLMs). Reject! This led me to expand the project by testing BERT embeddings in a direct comparison with my existing Word2Vec-based model.
⚙️ What it does
The project extension integrates LLM embeddings from BERT into the original incel classification framework and compares its performance against the original Word2Vec embeddings.
🛠️ How I built it
I built on the scikit-learn and gensim-based structure of the original project. The BERT embeddings were incorporated using the transformers library from Hugging Face. I ran comparative experiments between BERT and Word2Vec, both integrated into the same machine learning models for fair analysis. I measured performance as well as training efficiency.
🚧 Challenges I ran into
Using BERT was resource-intensive, taking up to 160 minutes per training session compared to 15 minutes for Word2Vec. Another difficulty was ensuring that the LLM-based pipeline integrated smoothly with the scikit-learn framework. This was my first time integrating LLMs into a project.
🏆 Results that I am proud of
Surprisingly, Word2Vec outperformed BERT in this specific use case, achieving an accuracy of 79% versus BERT's 75%. This result was counterintuitive but validated that simpler methods can sometimes be more effective, especially in focused application domains. This confirmed that my original choice of Word2Vec was justified.
📚 What I learned
The process underscored that while LLMs like BERT are powerful, their performance isn’t always superior for every application. The highly specific nature of incel terminology and discourse patterns enables Word2Vec to adequately capture the semantic relationships needed for this targeted classification task. Using more complex language models instead of the lightweight Word2Vec model would add unnecessary computational overhead without meaningful performance gains for this task.
My results demonstrate that for specialized text classification tasks with distinct vocabulary patterns, traditional word embedding techniques can still be optimal when thoughtfully combined with domain-specific features. Indeed, my paper combined text analysis and subreddit activity profiles and achieved 99.8% accuracy. This two-pronged approach significantly reduces false positives and negatives by cross-referencing data both with language use and community engagement patterns. LLMs alone would not be able to approach this accuracy even with fine-tuning.
🔮 What's next for LLM vs. Word2Vec: Toxic Language Detection for Social Good
The next step is to incorporate longitudinal studies to assess user behavior trends over time. This will involve observing user interactions and language patterns over longer periods to identify early indicators of deeper engagement in incel communities.
Built With
- bert
- huggingface
- llm
- python
- scikit-learn
- transformers
- word2vec

Log in or sign up for Devpost to join the conversation.