-
-
Home page
-
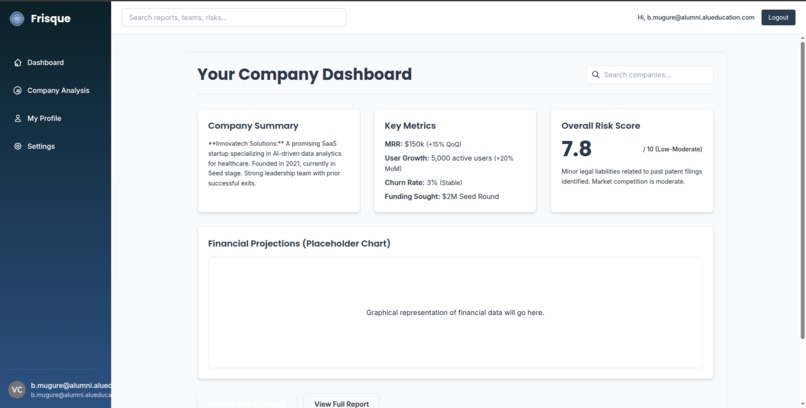
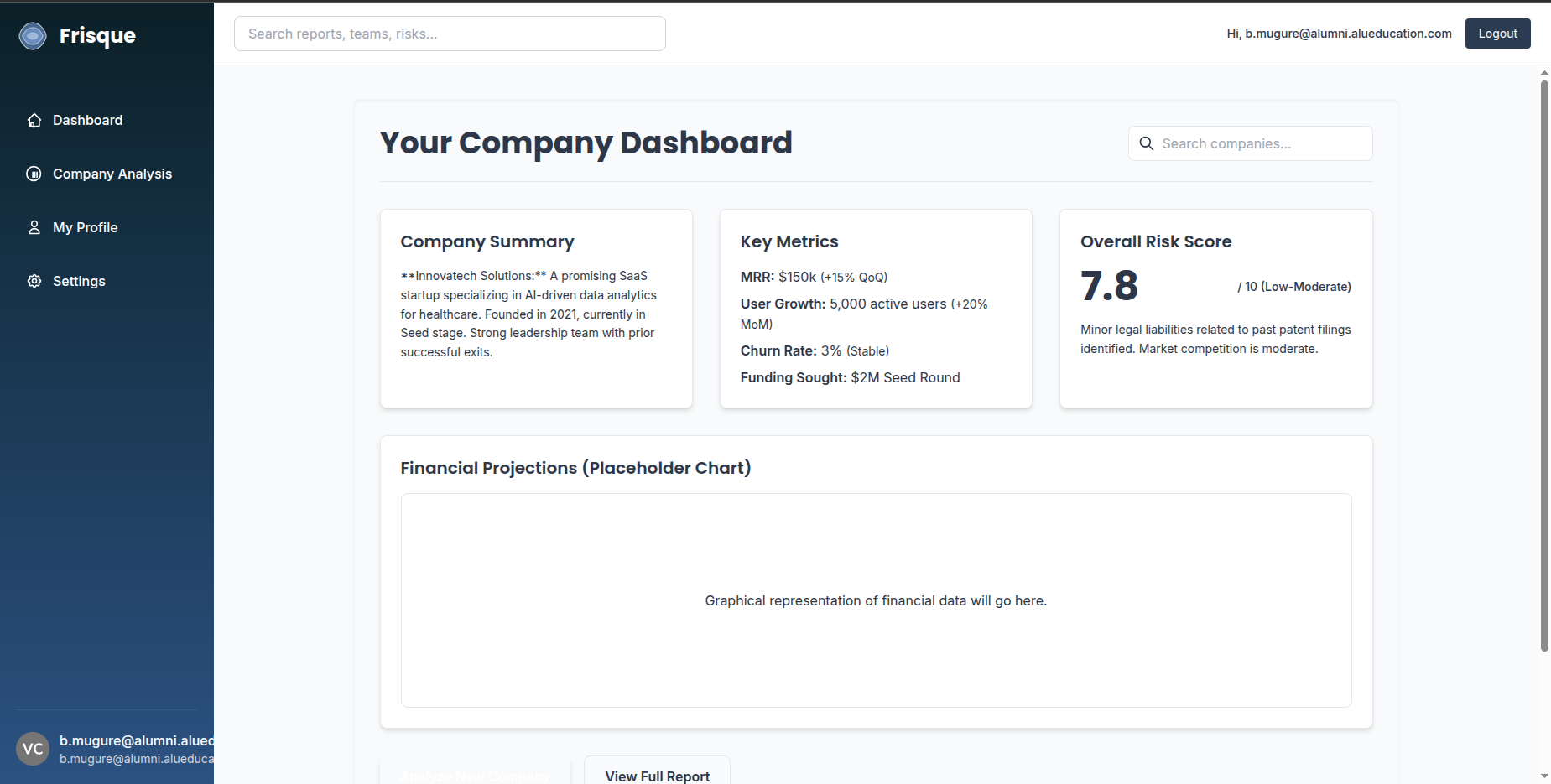
Dashboard
-
Scan page
-
In Progress result results page
-
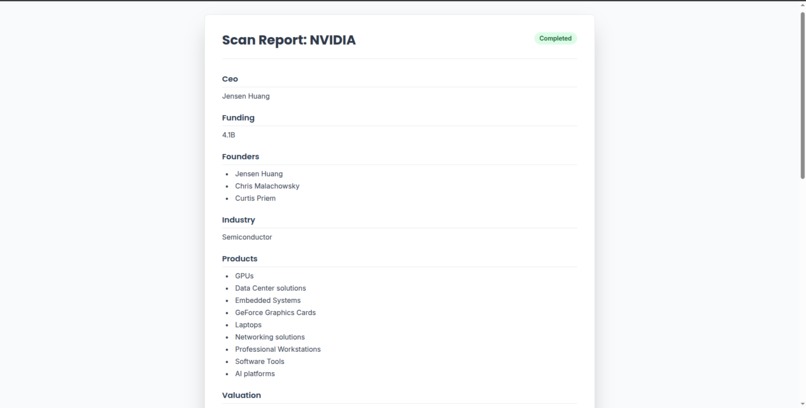
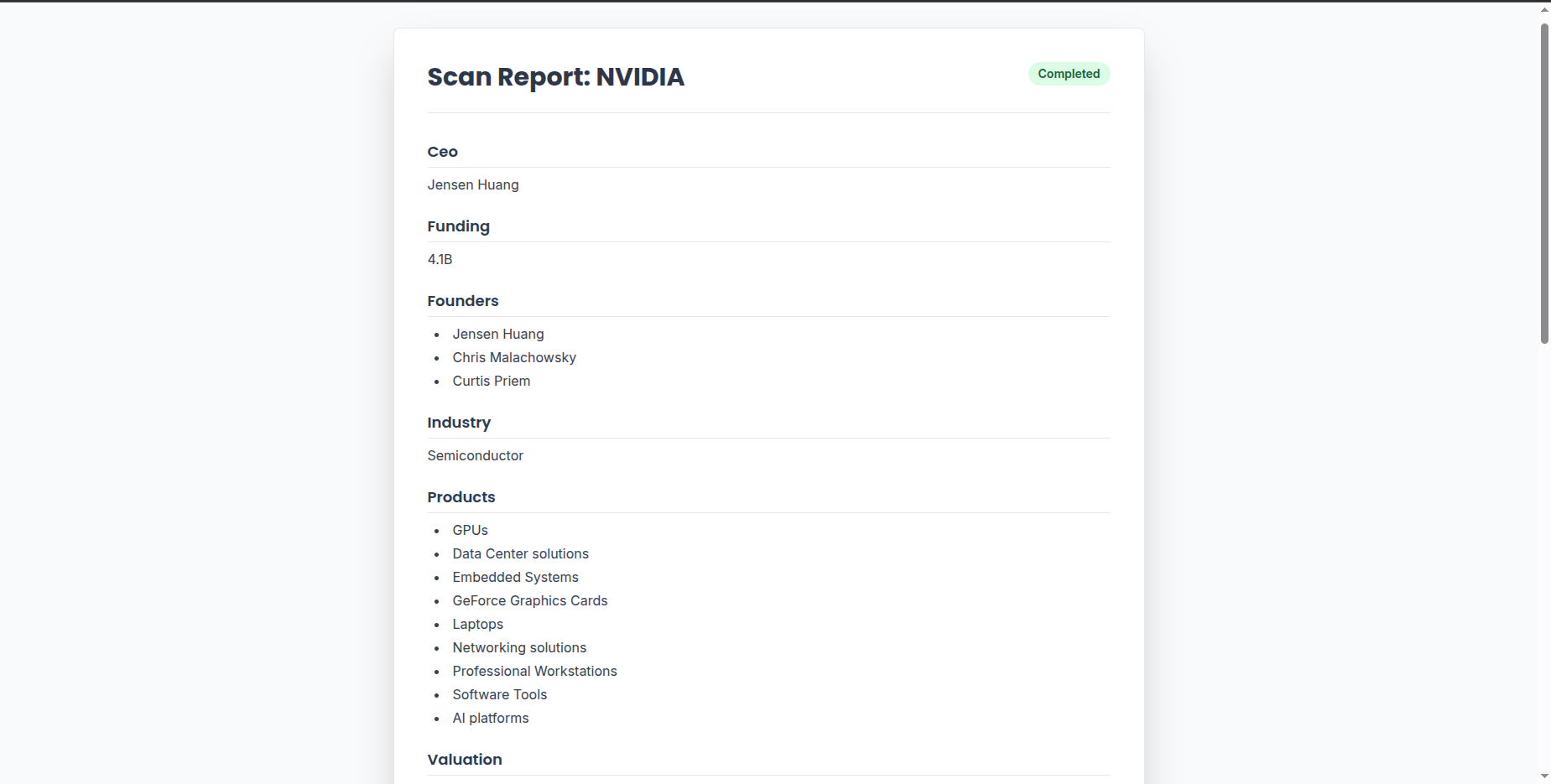
Successful results page
-
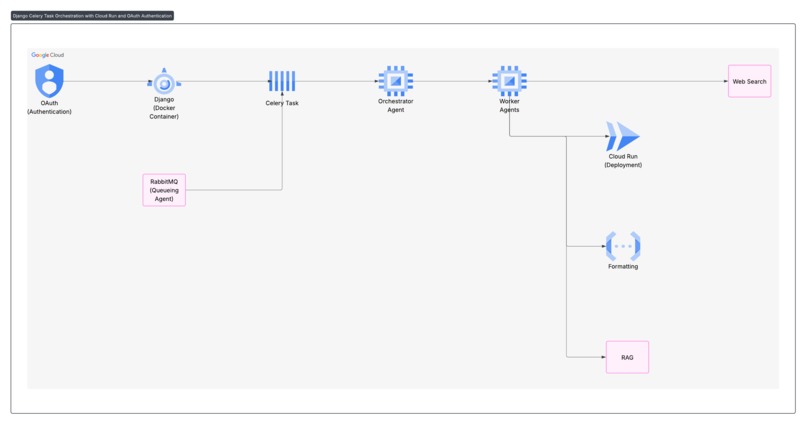
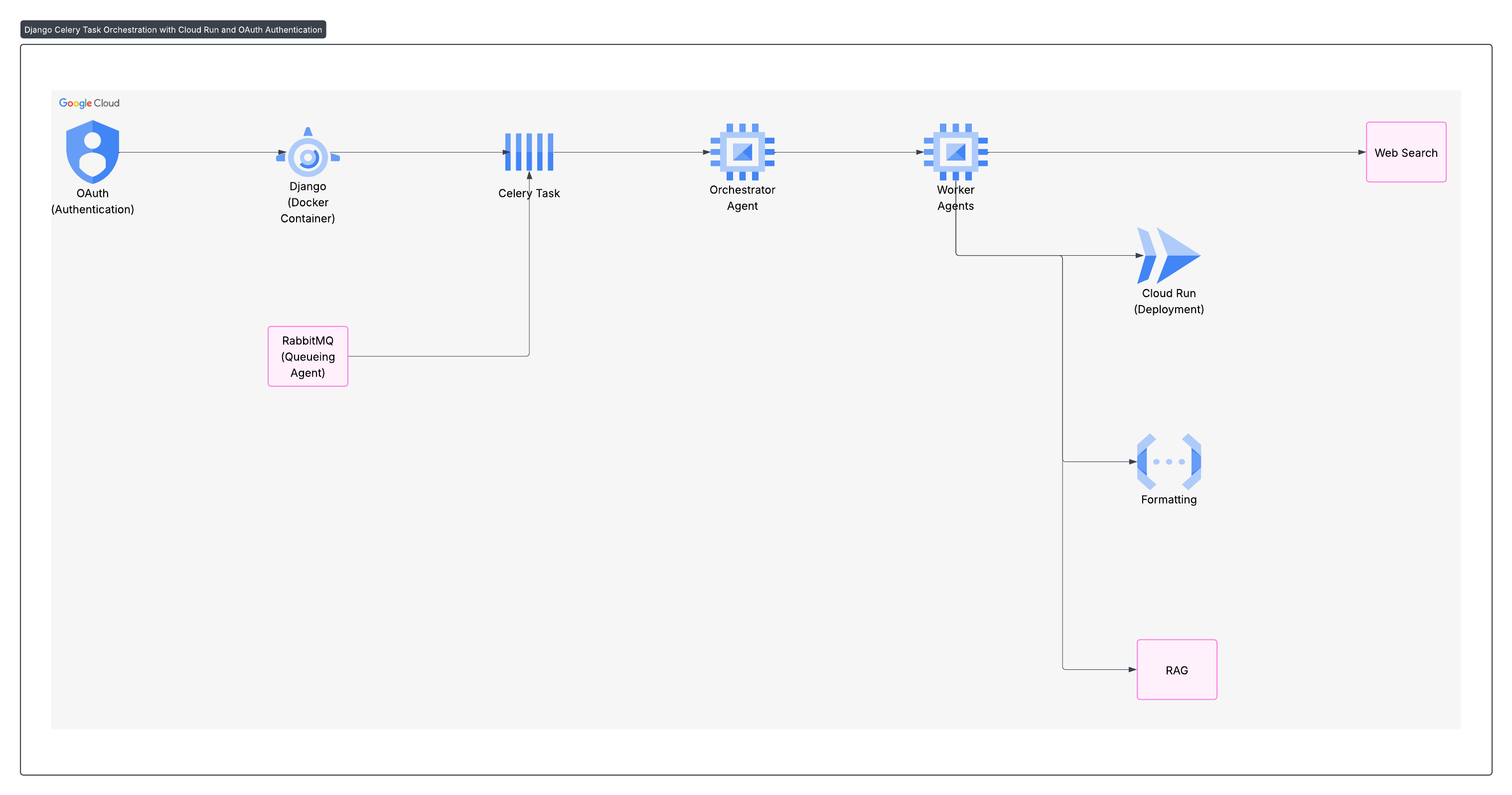
Architectural Diagram
Inspiration
Venture Capital (VC) firms dedicate substantial time and resources to due diligence, a process that is critical for assessing viability, growth potential, and risk, but is also highly time-intensive. Industry data indicates that a significant portion of a fund's returns comes from a small percentage (around 20%) of its investments. Therefore, streamlining and enhancing the accuracy of due diligence can lead to better investment decisions and improved resource allocation. Frisque was created to revolutionize this process.
Fun Fact: Frisque is derived from two French words "faux" and "risque", together meaning "false risk", which we are trying to eliminate.
What it does
Frisque is an AI-powered platform designed to significantly reduce the time and effort VCs spend on initial due diligence while improving the depth and breadth of insights. It utilizes a system of specialized AI agents to:
- Automate and augment key aspects of research and due diligence.
- Perform targeted research based on various inputs such as pitch decks, financial documents, founder profiles, company websites, and social media links.
- Analyze technology stacks, market trends, legal documents, and social media sentiment.
- Synthesize all findings into a structured investment memo and a summary dashboard, and can also generate financial projections, assumptions, key questions, and cited sources.
- Provide real-time updates and notifications on scan progress and completion.
- The core scan process involves input collection, asynchronous task initiation, agent orchestration (Master Bot delegating to specialized worker agents), data processing and analysis, output generation, and results storage
How we built it
Frisque's architecture and technology stack are designed for modularity, scalability, and efficient AI-powered due diligence. It aims to support asynchronous workloads and intelligent processing. Here's a breakdown of the key components:
Backend Framework (Django): Frisque is a web-based platform built on Django. Django provides a self-contained framework for the application's backend. Its ORM (Object-Relational Mapper) simplifies database interactions by managing models for users, companies, and scan jobs. This structure allows for quick integration with other technologies, such as Docker, for consistent development and deployment.
AI Agents (Google Agent Development Kit - ADK): The platform leverages Google's Agent Development Kit (ADK) to create its multi-agent AI system. ADK is an open-source, code-first framework designed for building and deploying sophisticated AI agents. It is "Multi-Agent by Design," enabling complex coordination and delegation of tasks within a team of agents. The Agent Starter Pack provides an easier way to quickly set up, customize, and deploy agents. This approach supports modular and scalable development, breaking down intricate problems into manageable sub-tasks handled by specialized agents.
Asynchronous Task Queue (Celery) and Message Broker (RabbitMQ): Frisque uses Celery for background task processing. When a scan is initiated, a Celery task is dispatched to handle it asynchronously. This allows for scheduling and managing complex, time-consuming operations outside of the main web request flow. RabbitMQ (or Redis) serves as the message broker for Celery, facilitating communication between the application and the worker processes.
Containerization (Docker and Docker Compose): Docker is used for containerization, ensuring that the application and all its dependencies are packaged into isolated units. Docker Compose simplifies the management of multi-container Docker applications for local development. This setup provides reproducibility across different environments, making it easy to get the development environment up and running consistently. All development commands are designed to be run inside the web container for a consistent workflow.
Database (PostgreSQL): PostgreSQL is the chosen database for storing structured data. This includes details of target companies and scan job metadata.
Object Storage (Google Cloud Storage - GCS): Google Cloud Storage (GCS) is integrated for storing unstructured data. This includes uploaded documents like pitch decks and financial spreadsheets, as well as generated reports and memos.
Real-time Communication (Django Channels): Django Channels, utilizing WebSockets, enables real-time updates and notifications. This allows the scan results page to display live progress updates and provides in-app notifications upon scan completion.
Infrastructure as Code (Terraform): Terraform is used for provisioning Google Cloud Platform (GCP) resources. This ensures that the cloud infrastructure is managed consistently and repeatably.
Cloud Platform (Google Cloud Platform - GCP): The entire system is designed to leverage Google Cloud Platform services for deployment and scalability. This includes potential use of Vertex AI for Agent Engine and LLM hosting, Cloud Run for serverless agent deployment, and Cloud SQL for managed PostgreSQL. Frisque is also a contribution to the Agent Development Kit Hackathon with Google Cloud.
This comprehensive stack allows Frisque to efficiently process complex due diligence tasks, manage data, and provide real-time insights to users
The development happened locally but the agents were soon deployed one after the other since we were using a microservices architecture.
Challenges we ran into
One of the first challenges that we ran into was hallucination by the agents. Another big challenge was system integration difficulty which was leading to prompt leakage. Fortunately, we were able to resolve these by using advice given on the issue we opened on the open source adk-python repository.
Accomplishments that we're proud of
- Successfully implemented a pipeline/assembly line architecture for the Agentic AI system, which enabled separation of concerns and allowed agents to specialize in specific tasks.
- Resolved issues with prompt leakage and hallucination by creating a new worker agent specifically for formatting responses
- Deployment of the agents to Cloud run which taught us about service accounts and permissions on the cloud
What we learned
Pipeline / Assembly line architecture for the Agentic AI system - This allows separation of concerns and agents can specialize on specific tasks. In our particular scenario, we had the master agent also formatting the response and this led to some sort of prompt leakage and hallucination. We created a new worker agent for formatting that solved this.
Prompting agents - we learnt that agents do not need to be directed as to which tools to use. Only give it the prompt as the adk already tells it the tools that are at its disposal. The tools it chooses to use is part of its agency, pun intended.
What's next for Frisque
- Enhanced Input Collection (UI for uploading various document types and links).
- Selective Scans allowing users to choose specific agents/scans (e.g., Tech, Legal, Financial).
- Development of Specialized ADK Agents such as Tech Bot, Legal Bot, Market Research Bot, Social Media Sentiment Bot, and Financial Bot.
- Structured Output Generation for investment memos, dashboards, scores, and financial projections.
- Deeper ADK Integration (Model Context Protocol, Agent-to-Agent communication).
- Management Commands for batch processing of portfolio companies.
- Implementation of RAG (Retrieval Augmented Generation) for "Chat with Scans" to allow natural language queries about reports.
- Advanced Scoring and Valuation Models.
- Moving agents to serverless platforms on GCP like Cloud Run or Cloud Functions for improved scalability, isolation, and cost-efficiency.
- Development of AI-Powered Deal Sourcing and Screening agents to proactively identify investment opportunities from public data sources.
- Contributing back to the open-source ADK repository
Built With
- agent-starter-kit
- celery
- cloudrun
- django
- docker
- gcs
- postgresql
- rabbitmq
- terraform


Log in or sign up for Devpost to join the conversation.