
Inspiration
Despite the advanced state of technology, connecting with others has never been so hard. You move to a new city, start a new job, or just realize your social circle has quietly shrunk — and the apps that exist to fix this feel like dating apps without the romance. They give you a bio, a few photos, and expect you to figure out compatibility from a 150-character blurb.
We thought: what if an app could actually understand what you're into — not from what you type in a form, but from how you already live your life? Your Instagram is a visual diary of your passions. Your voice carries enthusiasm for things you'd never think to list in a profile. We wanted to build something that sees the person behind the profile and connects them with people who genuinely share their world — so you can skip the awkward small talk and get straight into deep conversations about shared passions.
What it does
Friendly automatically finds friends within your close network who share your interests — the ones you never knew about.
You connect your Instagram, and Friendly runs a multi-stage AI pipeline behind the scenes: it scrapes your posts and reels, analyzes your images with Reka's multimodal vision model, extracts structured entities (hobbies, locations, brands, sports, food, music, art) from your captions and bio using Pioneer's zero-shot NER, and enriches your top interests with real-world context through Yutori's research and scouting APIs. Everything feeds into a Neo4j graph database that maps the relationships between people, interests, and the evidence connecting them.
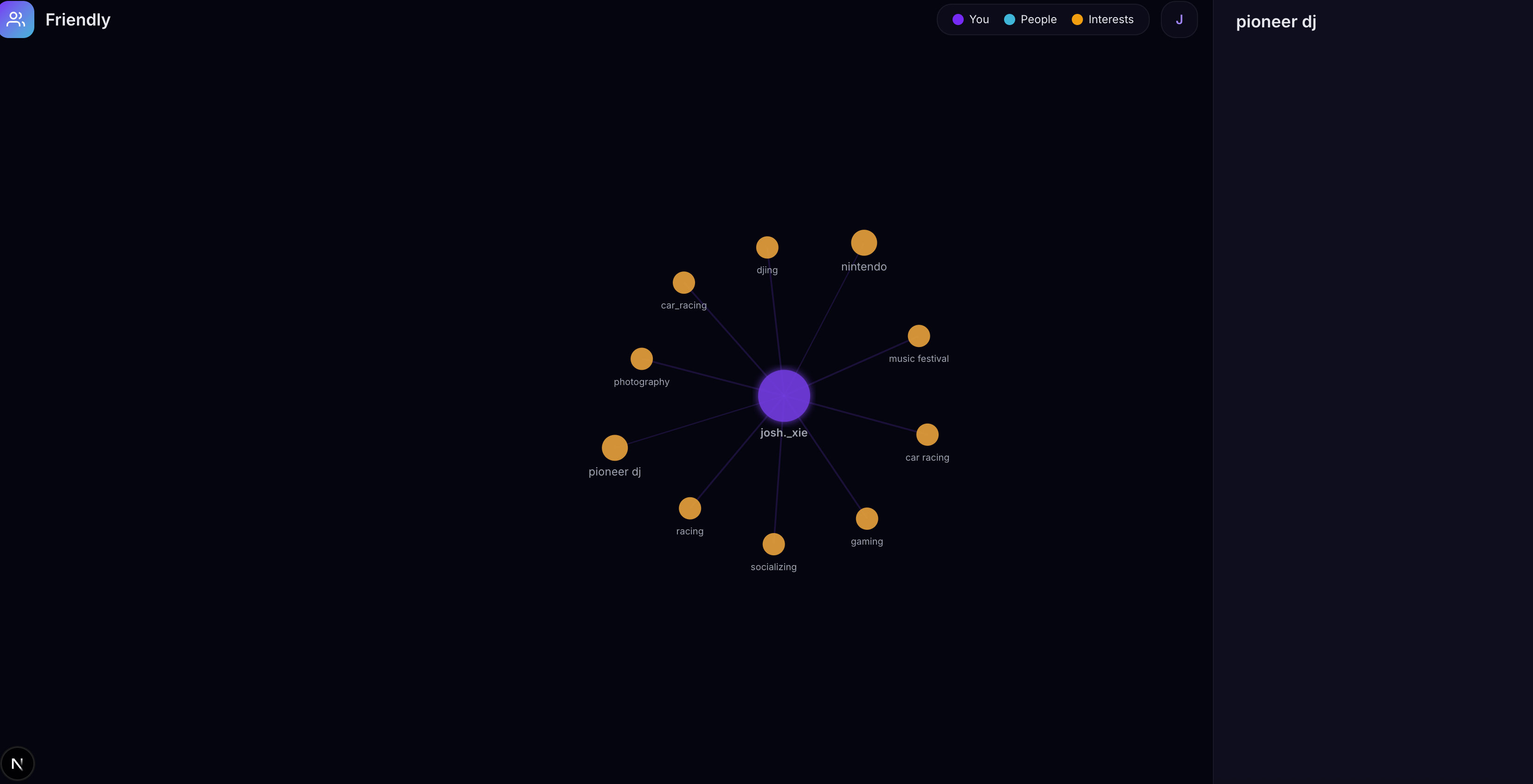
The result is an interactive force-directed graph visualization where you're at the center, surrounded by other users clustered by shared niche interests. Hover over a connection to see why you matched. Click a node and get an AI-generated icebreaker from Reka that uses the context of your shared interests to start a real conversation — not "hey, what's up" but "I saw you're into bouldering too — have you tried the new wall at Planet Rock?"
You can also record a voice clip, which Modulate's Velma-2 transcribes with emotion signals, feeding even more interest data into the graph with enthusiasm-weighted context.
How we built it
Backend — FastAPI + Python (uv)
The core backend orchestrates a six-service ingestion pipeline:
- Atlas scraper-standalone (:8090) pulls posts, reels, captions, and profile data from Instagram via HTTP scraping
- Reka (multimodal chat API,
reka-flashmodel) analyzes each post image and video — "describe the activities, hobbies, and interests visible in this image" — generating rich visual descriptions - Combined image descriptions + captions + bio text form a corpus that goes to Pioneer's GLiNER2 zero-shot NER, which extracts entities across 8 labels:
hobby,location,brand,activity,sport,food,music,art(threshold: 0.5) - Yutori Research API takes the top 3 extracted interests and runs deep research tasks — "what are the latest communities, events, and trends related to {interest}?" — returning structured results
- Yutori Scouting API sets up ongoing monitoring for trending content in those interest areas
- Everything writes to Neo4j as a graph: User, Hobby, Location, Brand, and Activity nodes connected by weighted, source-attributed relationships
For voice ingestion, Modulate's Velma-2 batch STT transcribes audio with emotion signals, then Pioneer extracts entities from the transcript with source: 'voice' attribution.
The pipeline is resilient — 20-second timeouts on external API calls, 3 retries on failure, a 5-minute cooldown between re-ingesting the same user, and capped parallelism (2 concurrent Reka calls) to stay within rate limits.
The pipeline is also extremely fast as we dump Reka's descriptions into Pioneer's zero-shot NER, which allowed for both profile generation and video recognition significantly more efficient.
Frontend — Next.js + React + TypeScript + Tailwind + shadcn/ui
The frontend is a dark-themed glassmorphism UI built with Bun. The core experience is a D3.js force-directed graph that renders the Neo4j interest graph in real-time — users as nodes, interests as clusters, weighted edges showing affinity strength. The onboarding flow walks you through Instagram sync → optional voice recording → an animated processing state → the discovery dashboard.
Infrastructure
Neo4j runs locally in Docker with the APOC plugin. The scraper runs as a standalone service on port 8090. Everything is orchestrated from a single docker-compose.yml.
Challenges we ran into
Orchestrating six different AI services in a single pipeline. Each sponsor API has its own auth pattern (header keys, SDK constructors, env vars), response format, and failure modes. Getting Reka's image analysis, Pioneer's NER, Modulate's STT, and both Yutori APIs to chain together reliably — where one service's output feeds the next — required careful error isolation so a single API timeout doesn't kill the whole ingestion.
Tuning Pioneer's entity extraction. At low confidence thresholds we got noise — every noun became a "hobby." At high thresholds we missed real interests. We landed on 0.5 as the sweet spot across 8 entity labels, but different label types needed different handling. A "brand" mention in a caption is weaker signal than a "sport" visible in a photo analyzed by Reka.
Making the graph visualization readable. A naive force graph with 50+ nodes and hundreds of edges is just a hairball. We spent significant time on the D3.js layout — tuning force strengths, clustering shared interests, scaling node sizes by connection count, and getting hover tooltips to surface the why behind each connection without cluttering the view.
Instagram scraping reliability. Public Instagram data is surprisingly inconsistent — missing captions, variable image URLs, rate limiting. The Atlas scraper-standalone handles most of this, but we had to add our own retry logic and a hard cap of 25 posts per scrape to keep ingestion times under control.
Accomplishments that we're proud of
The full pipeline actually works end-to-end. Enter an Instagram username, wait a few seconds, and see a populated interest graph with real extracted entities, enrichment context from Yutori, and AI-generated icebreakers from Reka. Every sponsor API is integrated and contributing meaningfully.
Purposeful use of every AI service. Reka for vision + icebreakers. Pioneer for structured entity extraction. Yutori Research for one-time enrichment and Scouting for ongoing monitoring. Modulate for voice with emotion. None of these are shoehorned — each is doing what it's best at.
The graph visualization is genuinely useful. It's not just eye candy for the demo. The force-directed layout with interest clustering makes it immediately obvious which people in your network share your niche passions. The "why" tooltips and Reka-powered icebreakers turn that insight into action.
Multimodal interest extraction is way richer than text alone. A photo of someone bouldering at sunset tells Reka about climbing, outdoor fitness, and golden-hour photography. Pioneer then extracts "bouldering" as a sport, "outdoors" as an activity, and the location from the caption. A bio-only approach would get maybe one of those.
What we learned
Graph databases change how you think about social data. Modeling relationships as first-class entities with their own properties (weight, source, evidence) makes queries like "find people who share 3+ interests with me, weighted by centrality" natural instead of painful. Neo4j's Cypher felt like the right abstraction for this problem from day one.
Zero-shot NER is powerful but needs guardrails. Pioneer's GLiNER2 can extract arbitrary entity types without training data, which is incredible for a hackathon. But "zero-shot" doesn't mean "zero-tuning" — the label definitions and confidence threshold matter enormously for output quality.
Multimodal pipelines compound value. Each AI service alone is useful. But the chain — Reka sees a photo → generates a description → Pioneer extracts entities → Yutori researches context → Neo4j connects users — produces insights that no single service could. The whole is greater than the sum of the parts.
Voice carries signal that text doesn't. Modulate's emotion signals on voice transcription let us weight interests by enthusiasm. When someone's voice lights up talking about ceramics, that's a stronger signal than a passing mention in a bio.
What's next for Friendly
Real user validation. Our demo runs on a small graph. The next step is onboarding a cohort at our university and measuring whether the matches actually lead to meaningful conversations.
Privacy and consent controls. Before any real launch, users need explicit opt-in for Instagram analysis, granular control over what enters the graph, and the ability to delete their data completely.
Deeper enrichment tiers. We've architected Tier 2 (Yutori Browsing API for finding real events and communities per interest) and Tier 3 (Yutori n1 for navigating Instagram highlights and generating visual "vibe fingerprints" for aesthetic-based matching). The backend microservices are scaffolded and ready to integrate.
Event-driven matching. With Yutori Scouting already monitoring interest trends, we can push notifications like "a new bouldering gym just opened near you and 3 of your matches — want to go together?" Turn passive discovery into active connection.
Mobile app. The voice recording and graph exploration experience would be significantly better on native. We're eyeing React Native to share component logic from the web frontend.
Built With
- modulate
- neo4j
- pioneer
- python
- reka
- typescript
- yutori



Log in or sign up for Devpost to join the conversation.