

FraudShield AI
Inspiration
Job scams have unfortunately become very common, and I saw some friends get caught in them while searching for work. Even I once fell victim to a scam when I was looking for accommodation. These experiences motivated me to build a solution that could leverage real fraud data effectively. With so much fraud information available, I realized that using a database like MongoDB to store and query this data at scale would provide a strong foundation for an AI system that helps people and businesses recognize scams more easily.
What it does
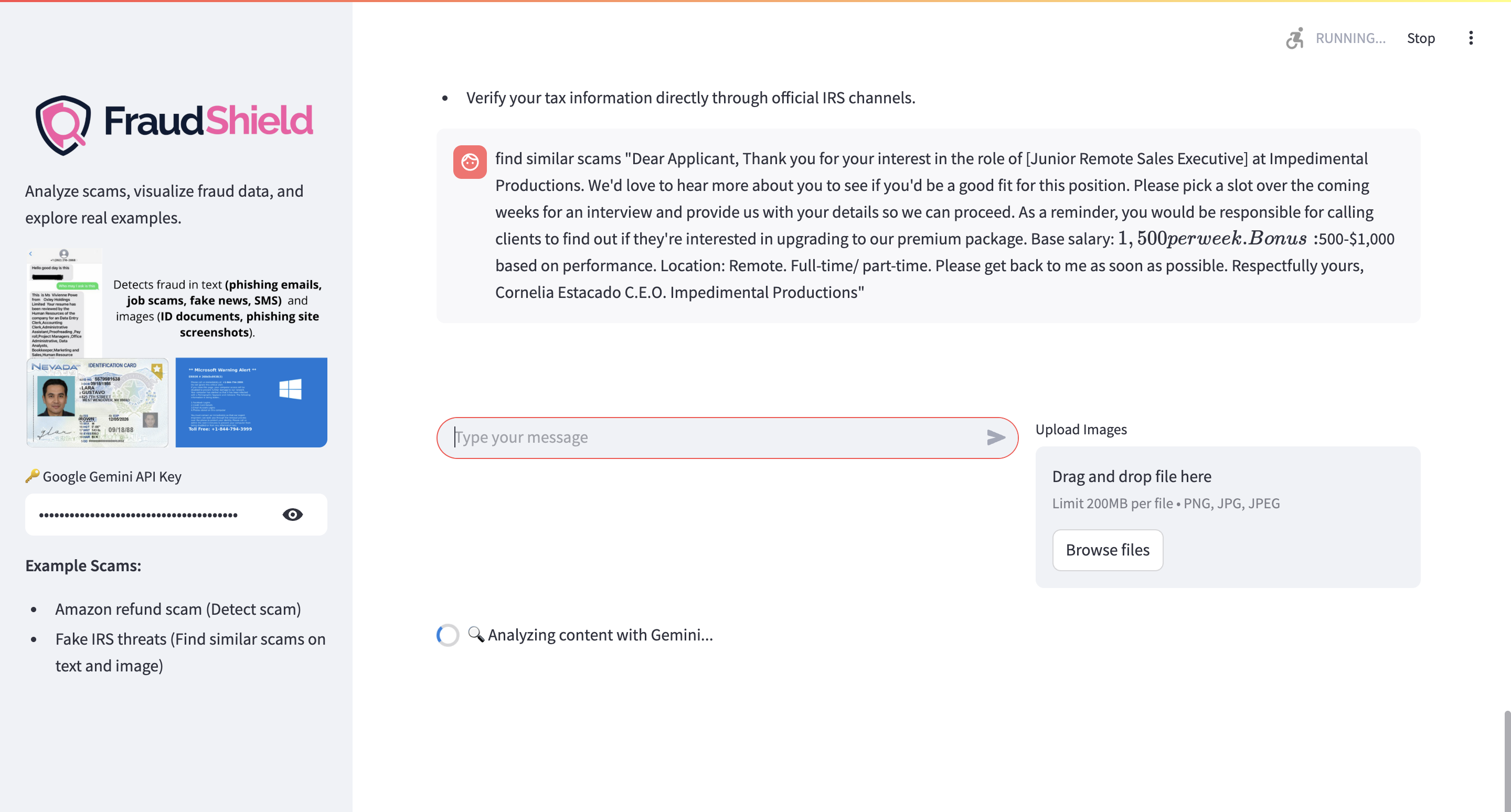
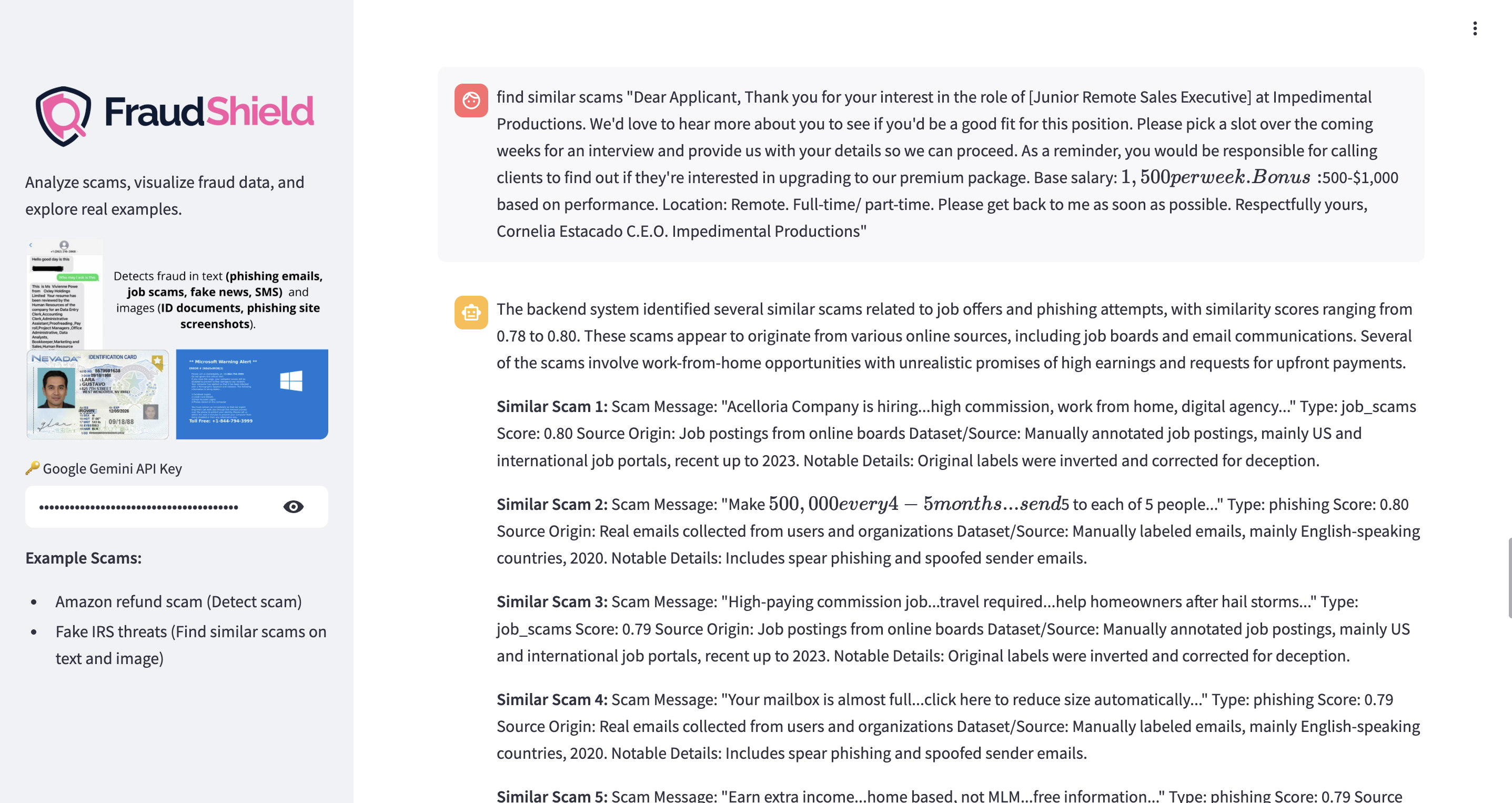
FraudShield AI focuses on detecting fraud in suspicious text messages and identity documents. For text, users can paste any message, email, or social media post, and the system searches a large fraud database for similar cases. It predicts whether the text is a scam, identifies the likely scam type — such as phishing, fake news, job scams, SMS fraud, among others — and highlights important keywords. The system also provides similarity scores and points out locations where similar frauds have been reported. Using Gemini, it gives clear explanations and recommendations to help users understand the risks and decide what to do next.
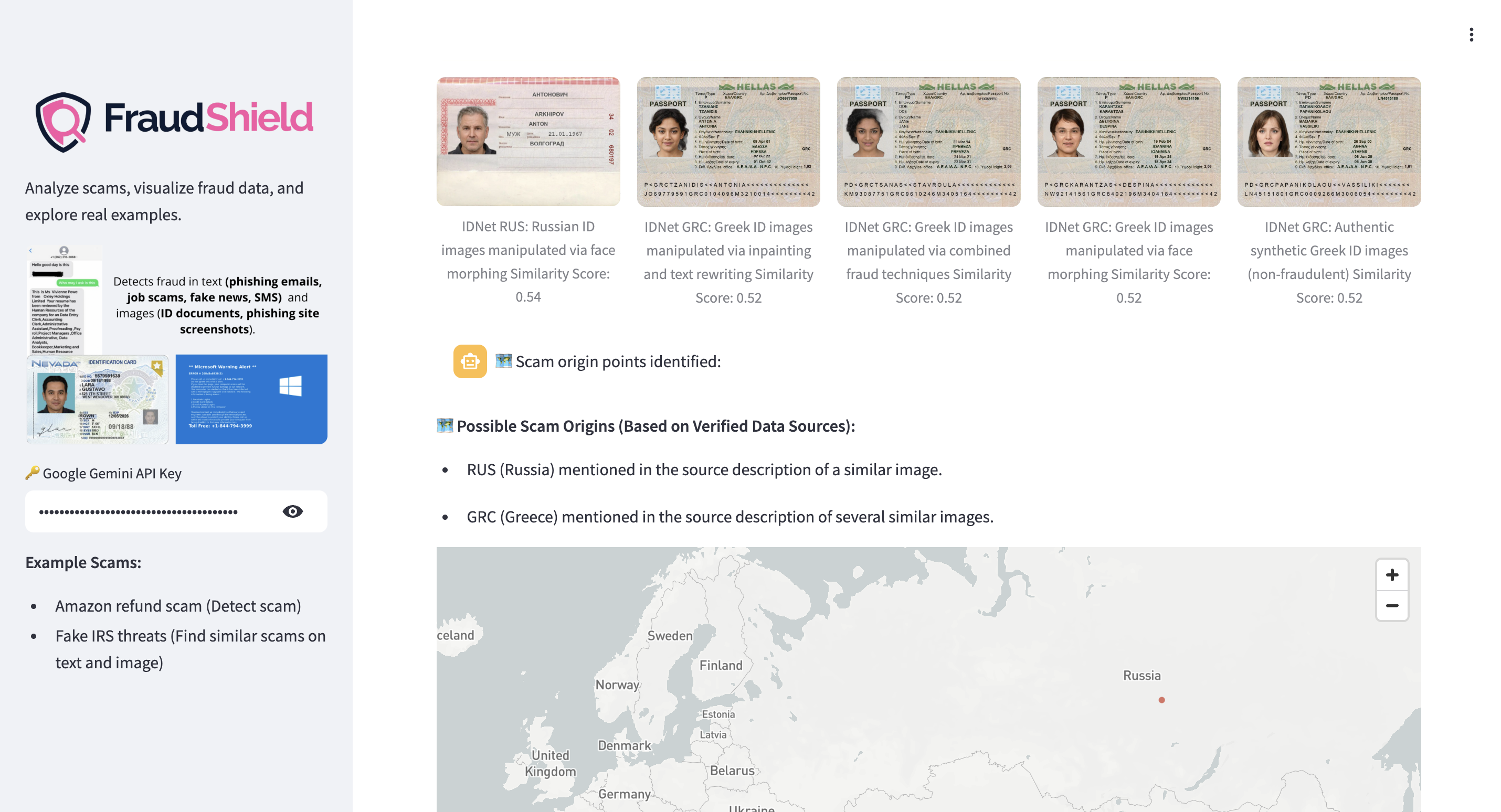
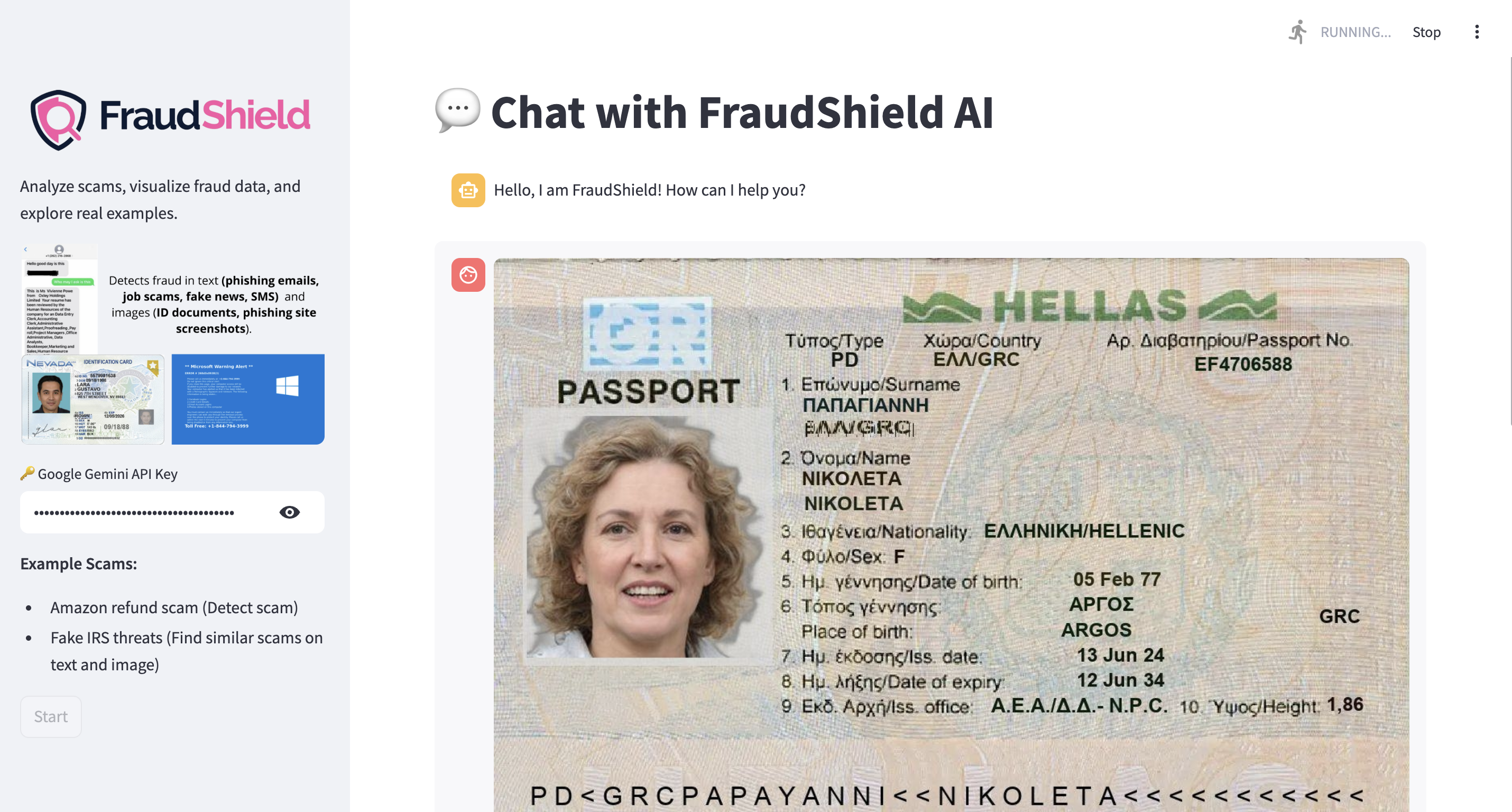
For images, users can upload scans or photos of identity documents like driver’s licenses, passports, or screenshots of phishing websites. The system generates embeddings and compares them to known fraudulent documents and sites. It returns a similarity score and risk level, along with any matching entries from the database. Gemini explains why the document looks suspicious and suggests safe steps to follow. This helps make fraud easier to recognize for individuals and businesses, giving them actionable insights to protect themselves.
How I built it
I structured the project into three main components:
1. Backend (FastAPI)
The API handles requests for analyzing text and images. It generates embeddings for both modalities and searches for similar records using MongoDB Atlas Vector Search. The backend also has separate routes that coordinate requests to Gemini, which acts as the conversational explainer and provides additional insights such as keyword extraction or location mentions.
2. Frontend (Streamlit)
I chose Streamlit to build a simple, interactive interface where users can paste messages, upload files, and chat with the AI assistant, without requiring complex frontend development.
3. Machine Learning and Embeddings
I selected lightweight yet effective embedding models for text and images, balancing speed and accuracy. Apart from the embeddings for similarity search, I trained two custom ML models: one to classify whether a message is a scam and another to predict the specific scam category. I also implemented a data pipeline to process and index all relevant information in MongoDB, ensuring fast and accurate searches.
Challenges I ran into
One key challenge was choosing embedding models that offered good accuracy while staying efficient enough for the backend to handle multiple requests with limited resources. Deploying these models within the backend also required careful optimization to keep the server responsive. Selecting and curating high-quality fraud datasets was another challenge, as I needed to balance the richness of the data with the storage limits of a free MongoDB tier.
Accomplishments I am proud of
I am proud that I managed to build an end-to-end system that combines similarity search with custom-trained ML models for both text and images. The classifier achieves reliable accuracy in predicting whether a text is fraudulent and determining the scam type. Integrating Gemini adds another layer of usability by providing clear, conversational explanations and extracting relevant information to help users make informed decisions.
What I learned
I had used MongoDB before but had never applied it for large-scale vector similarity search. Through this project, I learned how to combine embeddings, custom ML models, and a conversational AI like Gemini into a cohesive system for fraud detection. I also improved my skills in managing backend pipelines, optimizing model deployment, and designing user-friendly interfaces with Streamlit.
What’s next for FraudShield AI
There are several areas I would like to expand in the future. One priority is full document analysis for items like contracts or offer letters. Integrating OCR would allow the system to extract and embed text directly from images, increasing detection accuracy for various document types. I also plan to experiment with more robust image embedding models to better detect subtle forgeries. Another goal is to add malicious URL detection by comparing links against known blacklists. Finally, I would like to upgrade to a paid MongoDB cluster to handle larger datasets and higher traffic volumes, ensuring better performance for real users.
Built With
- fastapi
- gemini
- google-cloud
- mongodb
- streamlit

Log in or sign up for Devpost to join the conversation.