Inspiration
While researching project ideas for DevDash 2026, I stumbled on a staggering number: over $32 billion lost to payment card fraud every year (source: The Nilson Report). Digging deeper, I discovered something surprising — the problem isn't just detecting fraud (ML models are pretty good at that), it's that analysts reviewing the alerts have zero visibility into why a transaction was flagged. They're stuck triaging thousands of alerts with nothing but a confidence score and no explanation. The result? Alert fatigue, wasted hours, and real fraud slipping through.
The hackathon theme — "dashboards that turn data into action" — clicked immediately. What if a dashboard didn't just flag suspicious transactions, but explained the reasoning in plain language? That's the gap I wanted to fill.
FraudPulse was born from that idea: a fraud detection dashboard where every alert comes with a real explanation, not just a number.
What it does
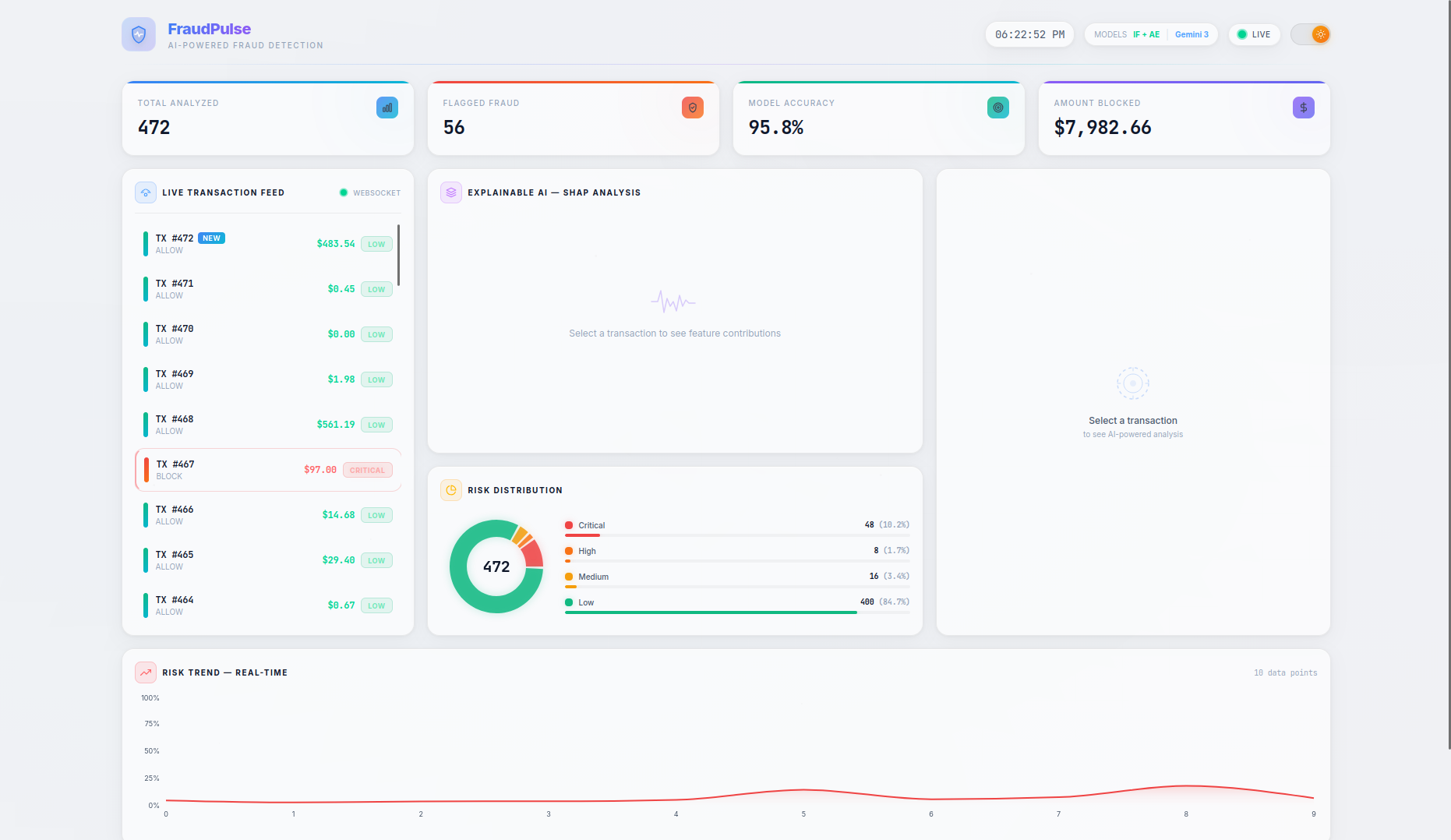
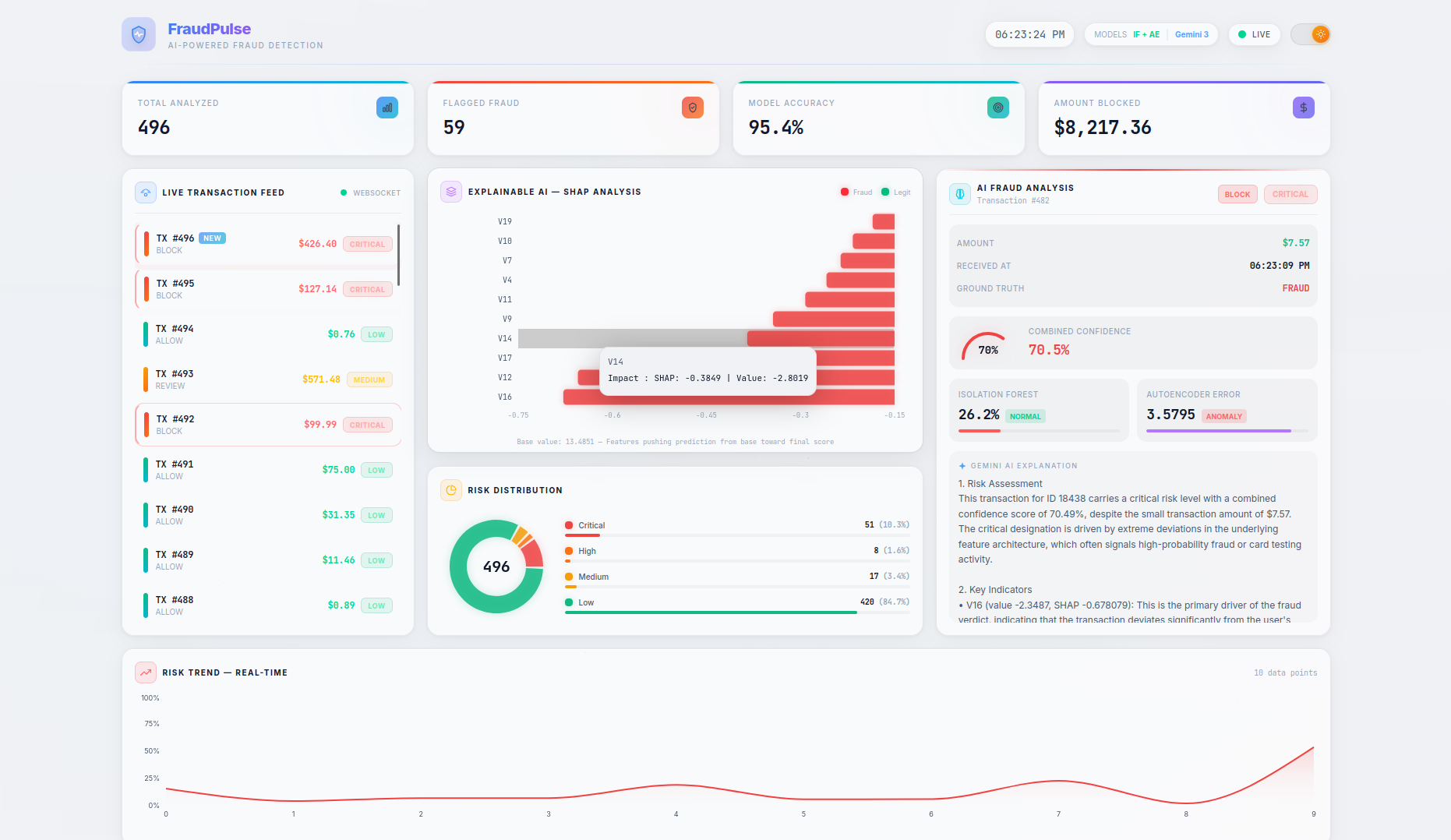
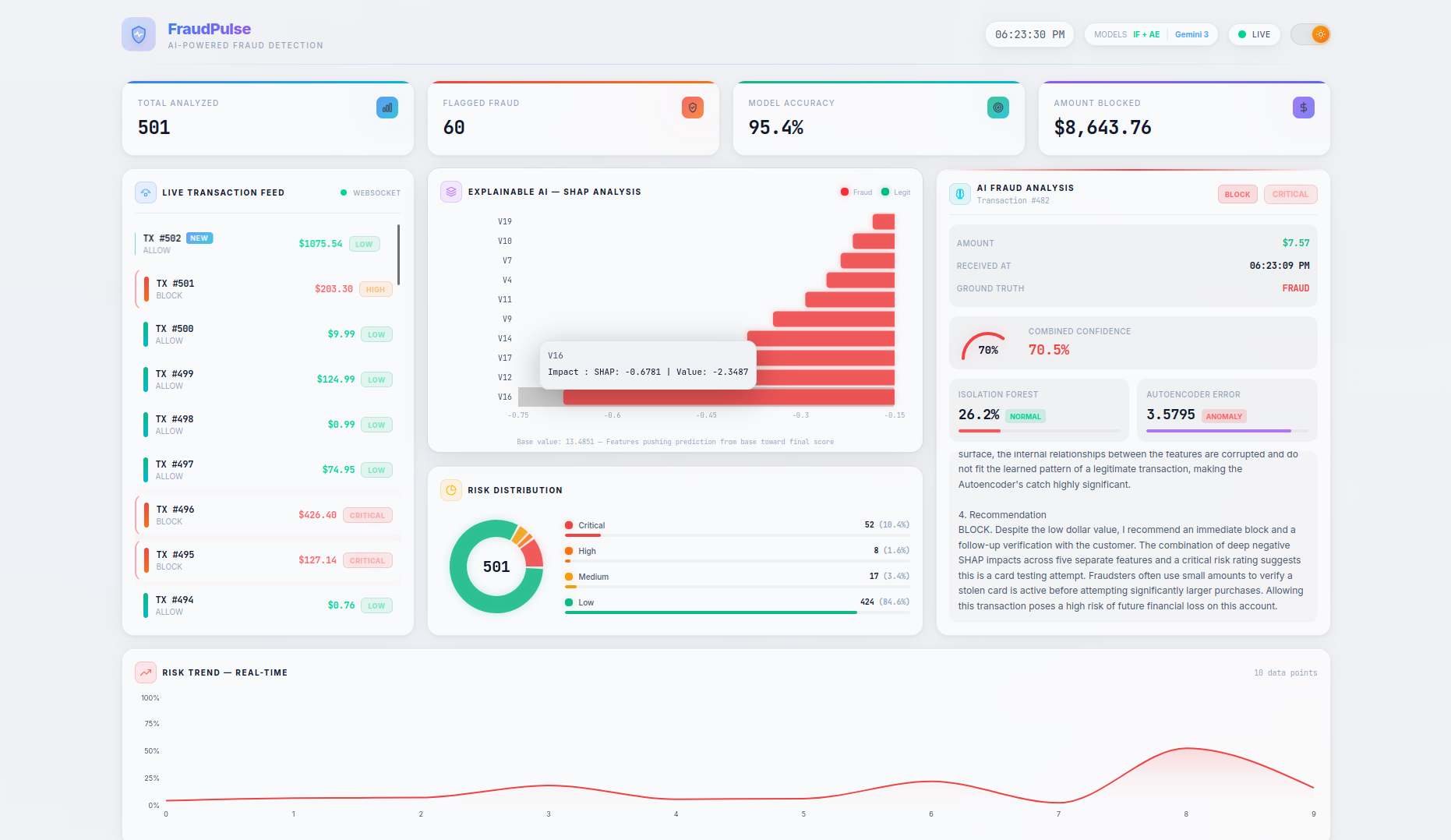
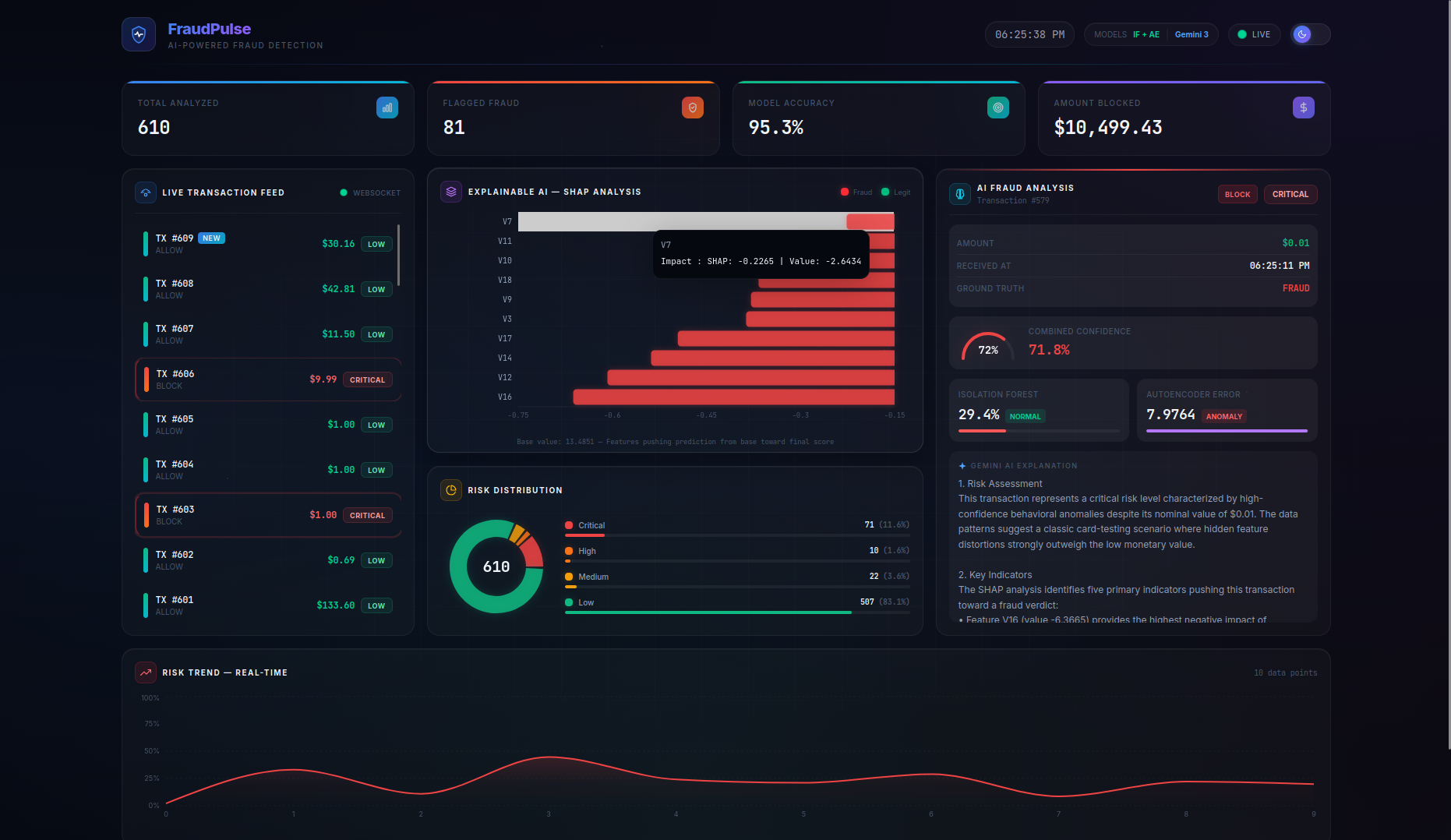
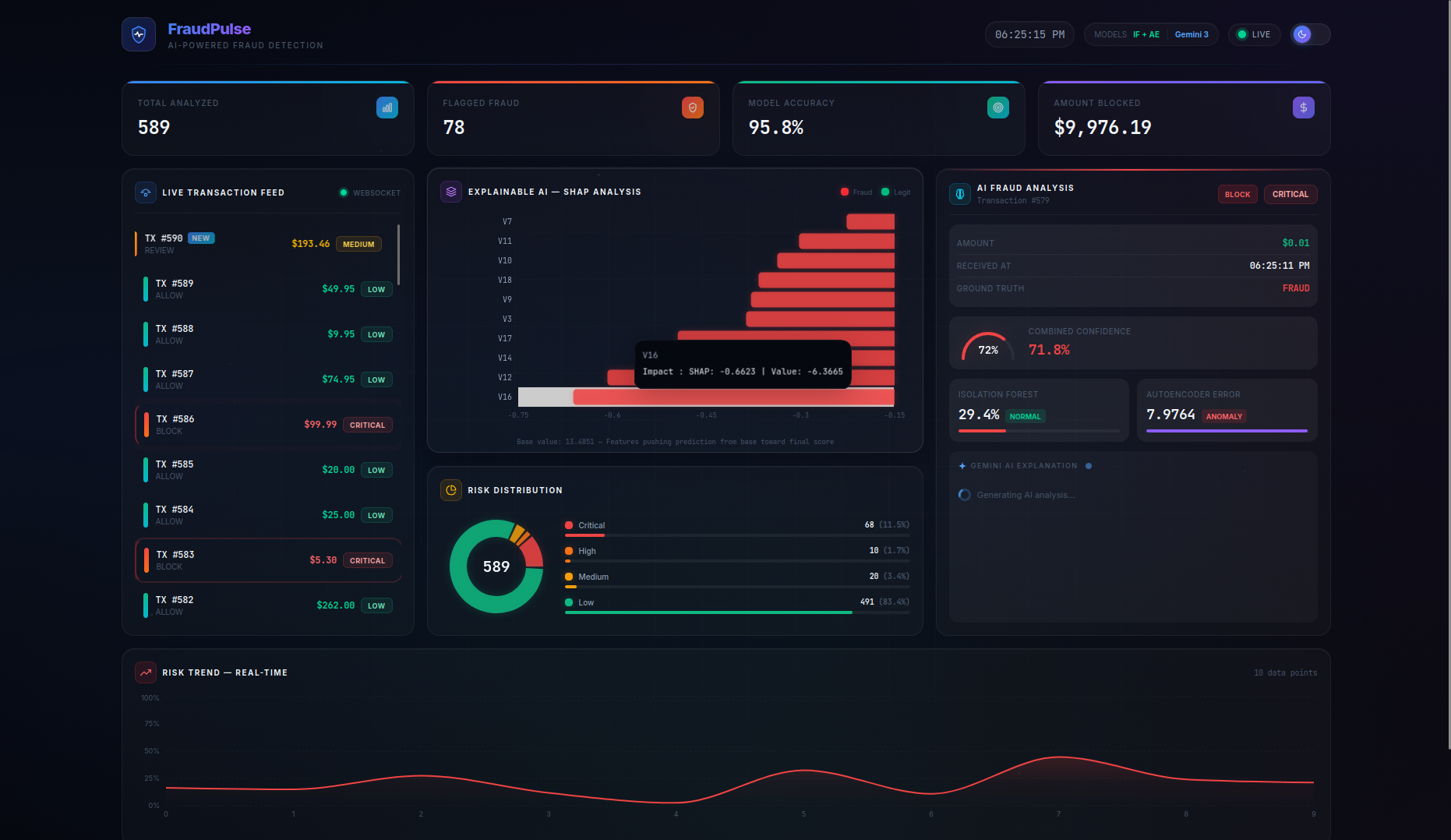
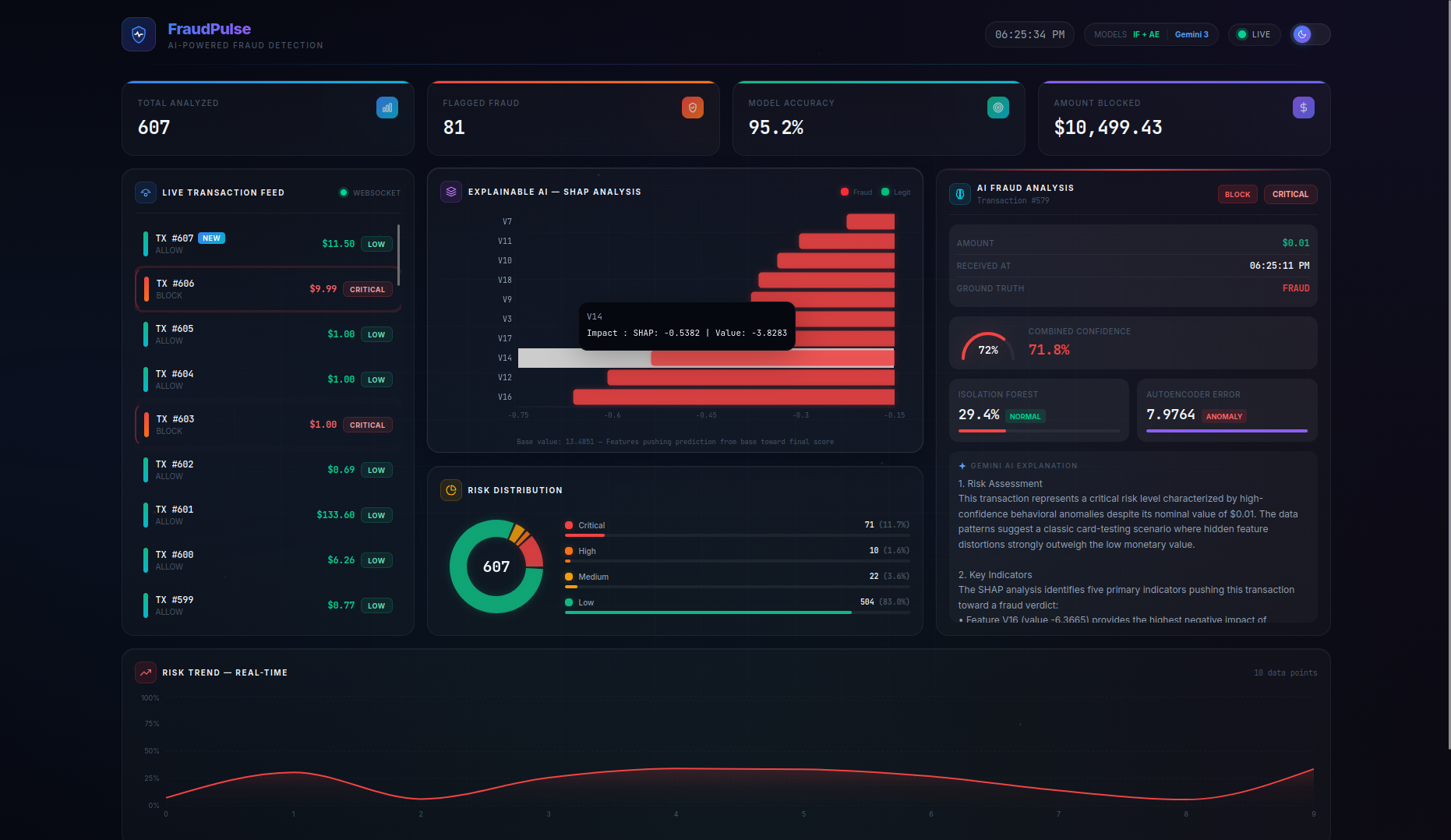
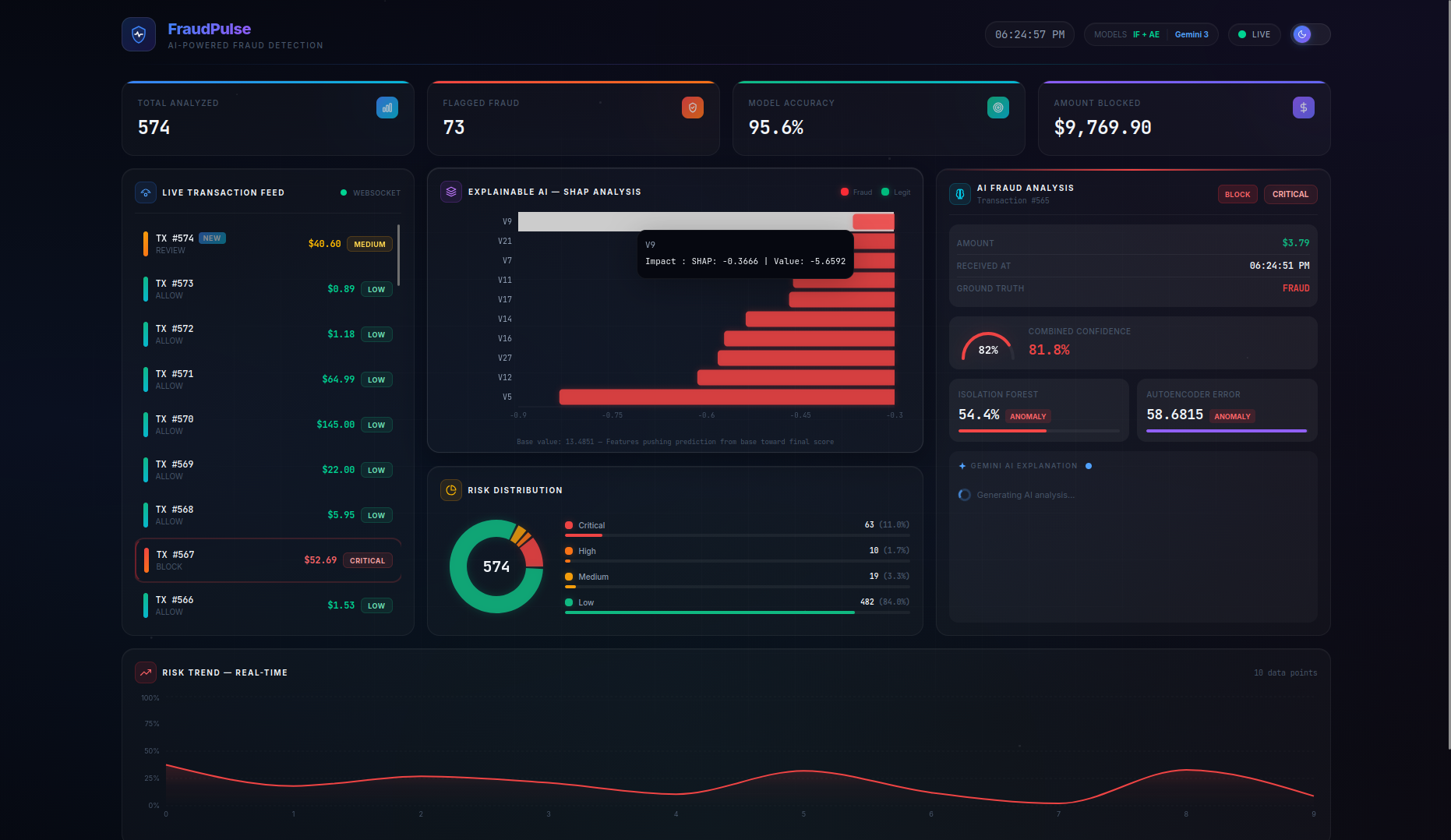
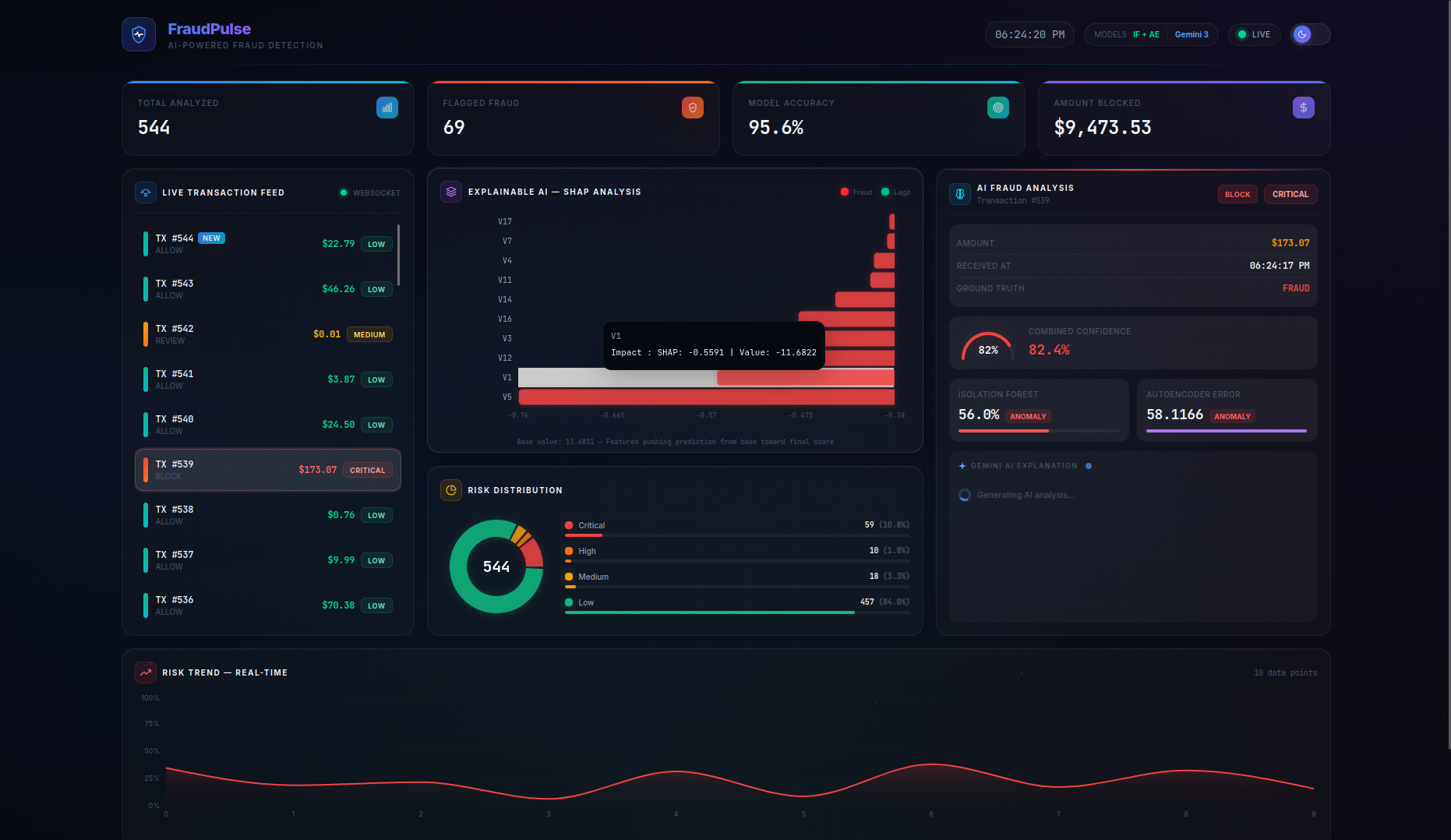
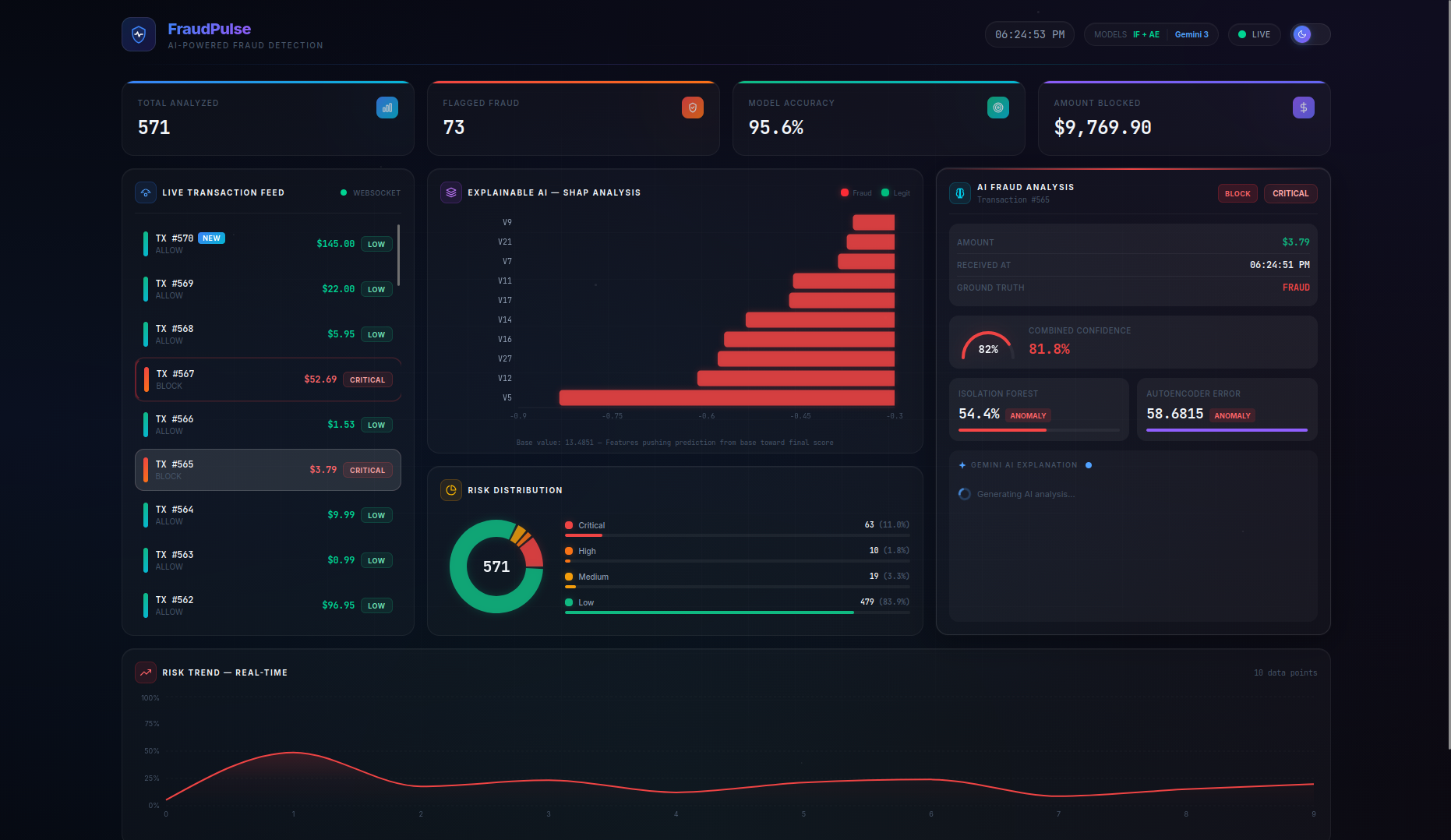
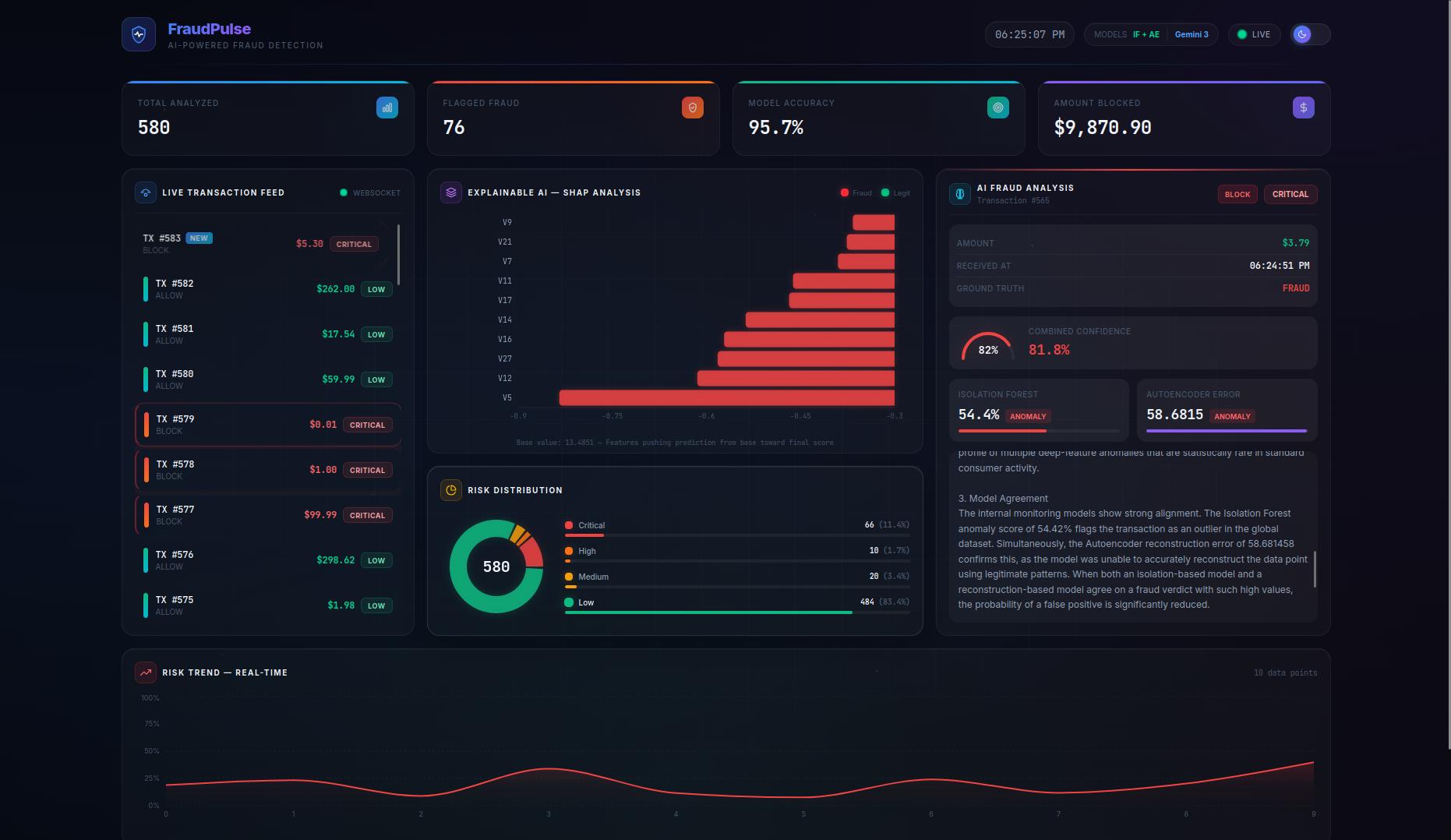
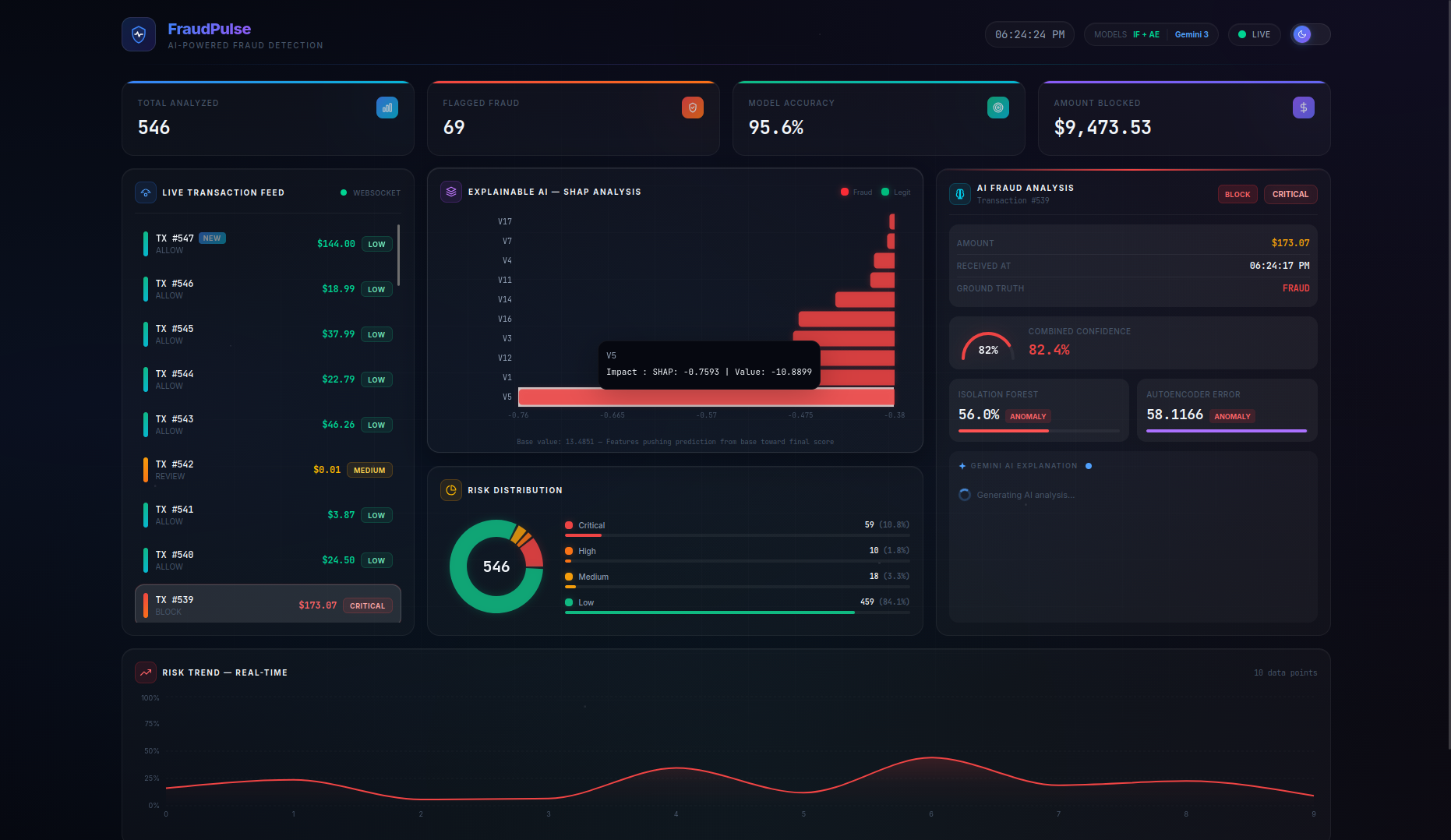
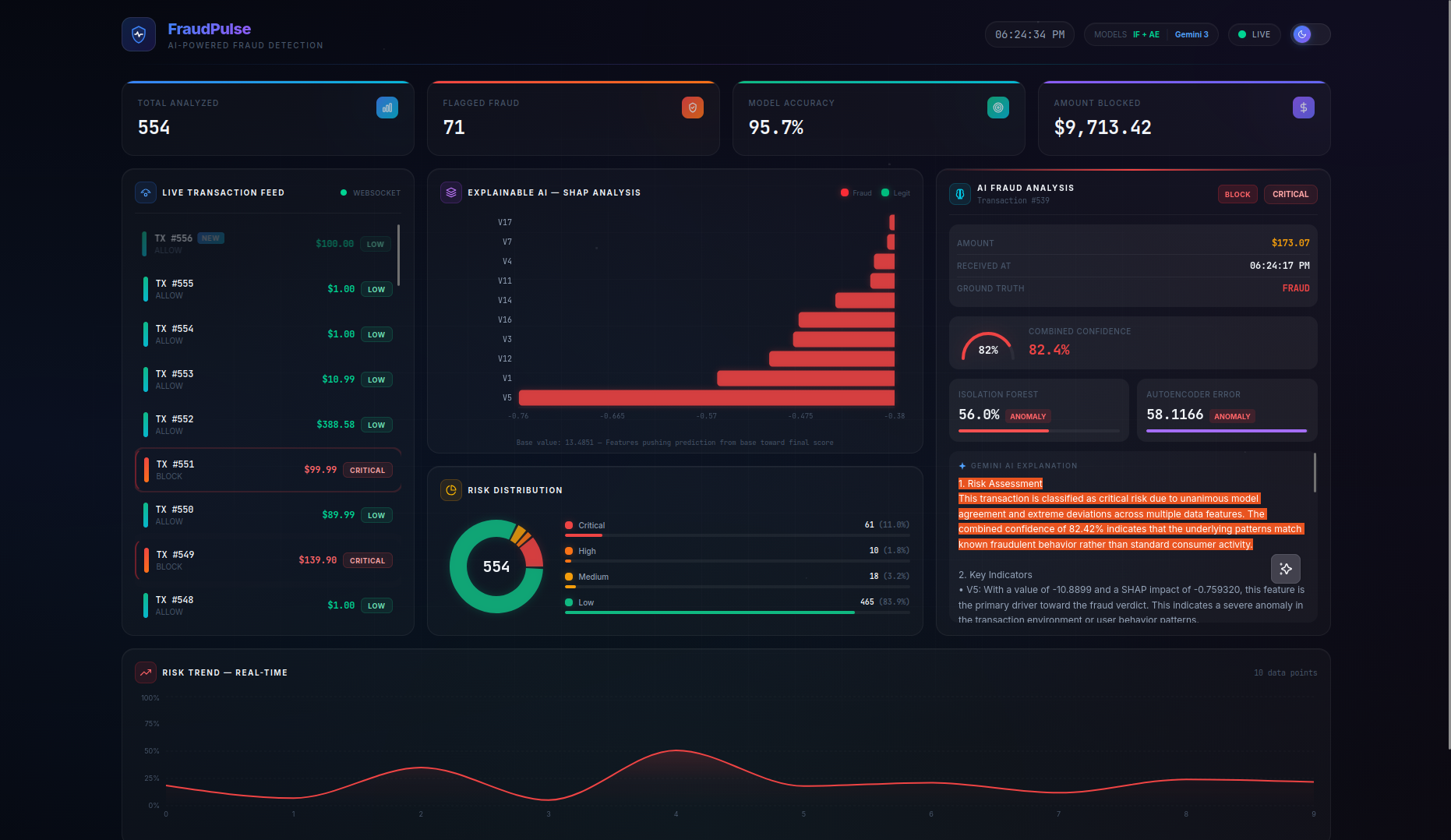
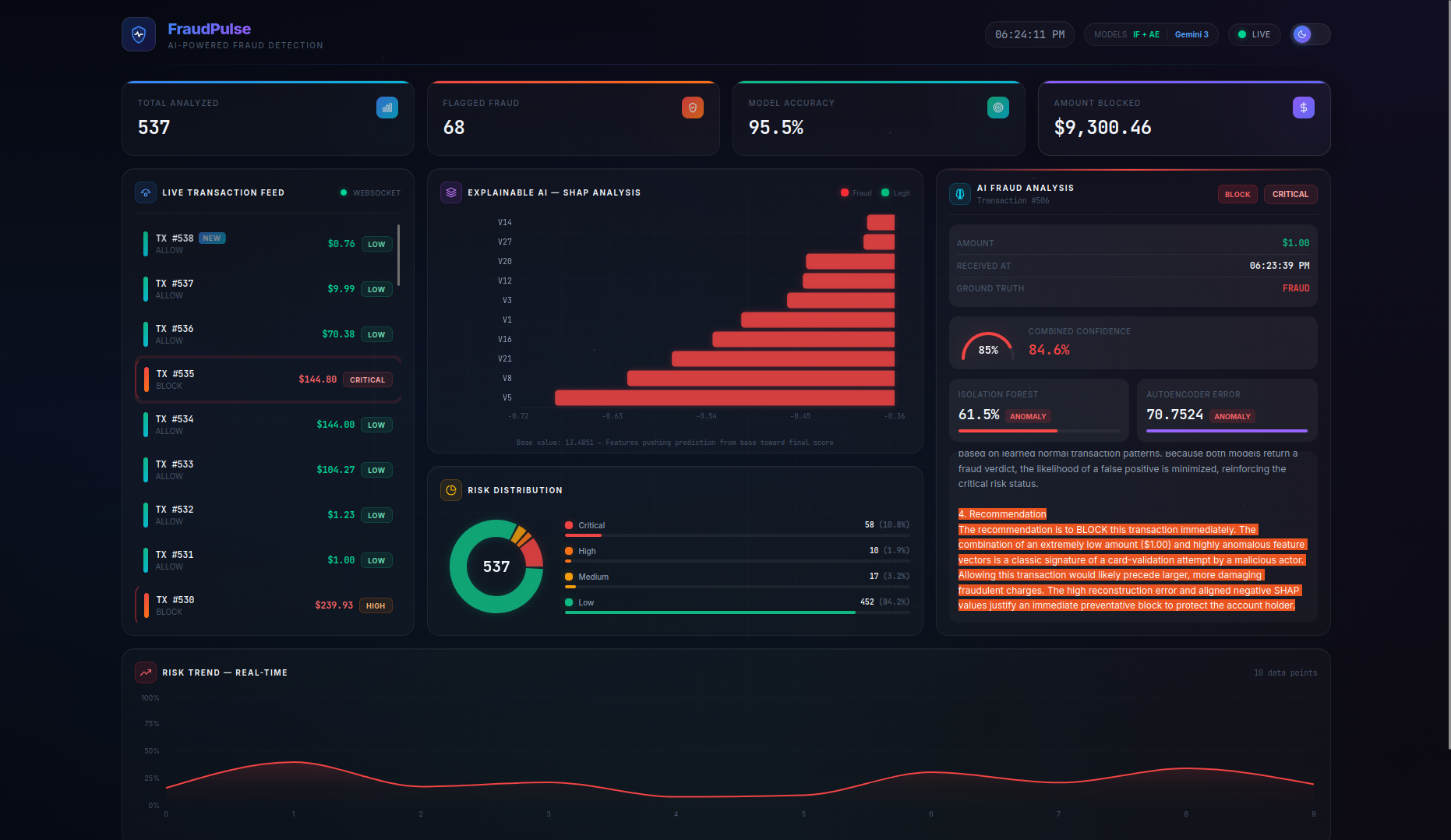
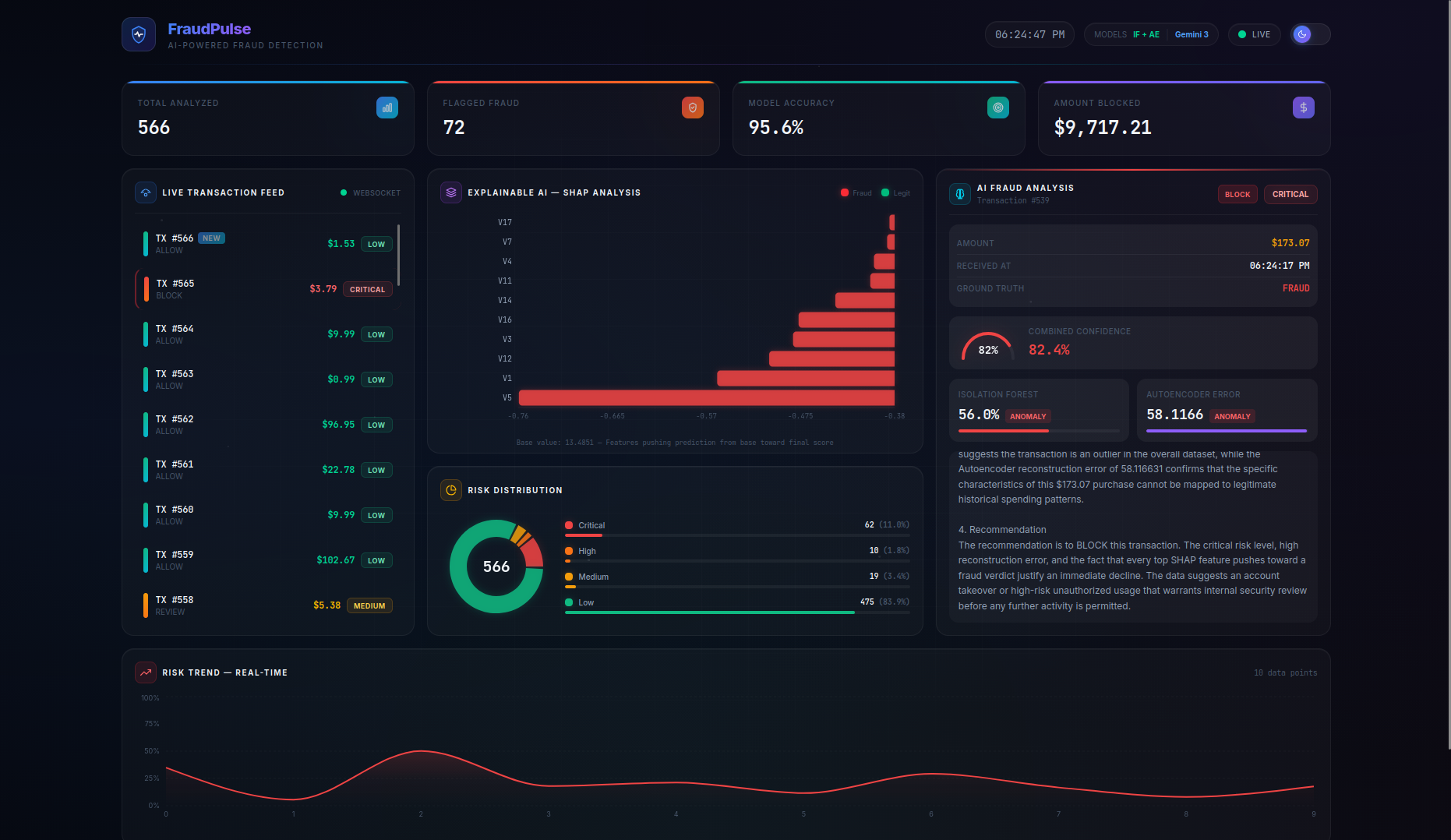
FraudPulse is a real-time fraud detection dashboard that monitors a live stream of credit card transactions and provides instant, explainable risk assessments.
- Real-Time Streaming — Transactions flow in via WebSocket (with automatic HTTP polling fallback) and appear live in the transaction feed with animated risk indicators. On page refresh, the server buffer is seeded back so no data is lost.
- Dual AI Detection — Every transaction passes through two complementary ML models:
- An Isolation Forest (scikit-learn, 200 estimators) trained on 284,807 real bank transactions to detect statistical anomalies
- A PyTorch Autoencoder (29→20→12→6→12→20→29 architecture) trained exclusively on legitimate transactions, flagging anything it fails to reconstruct
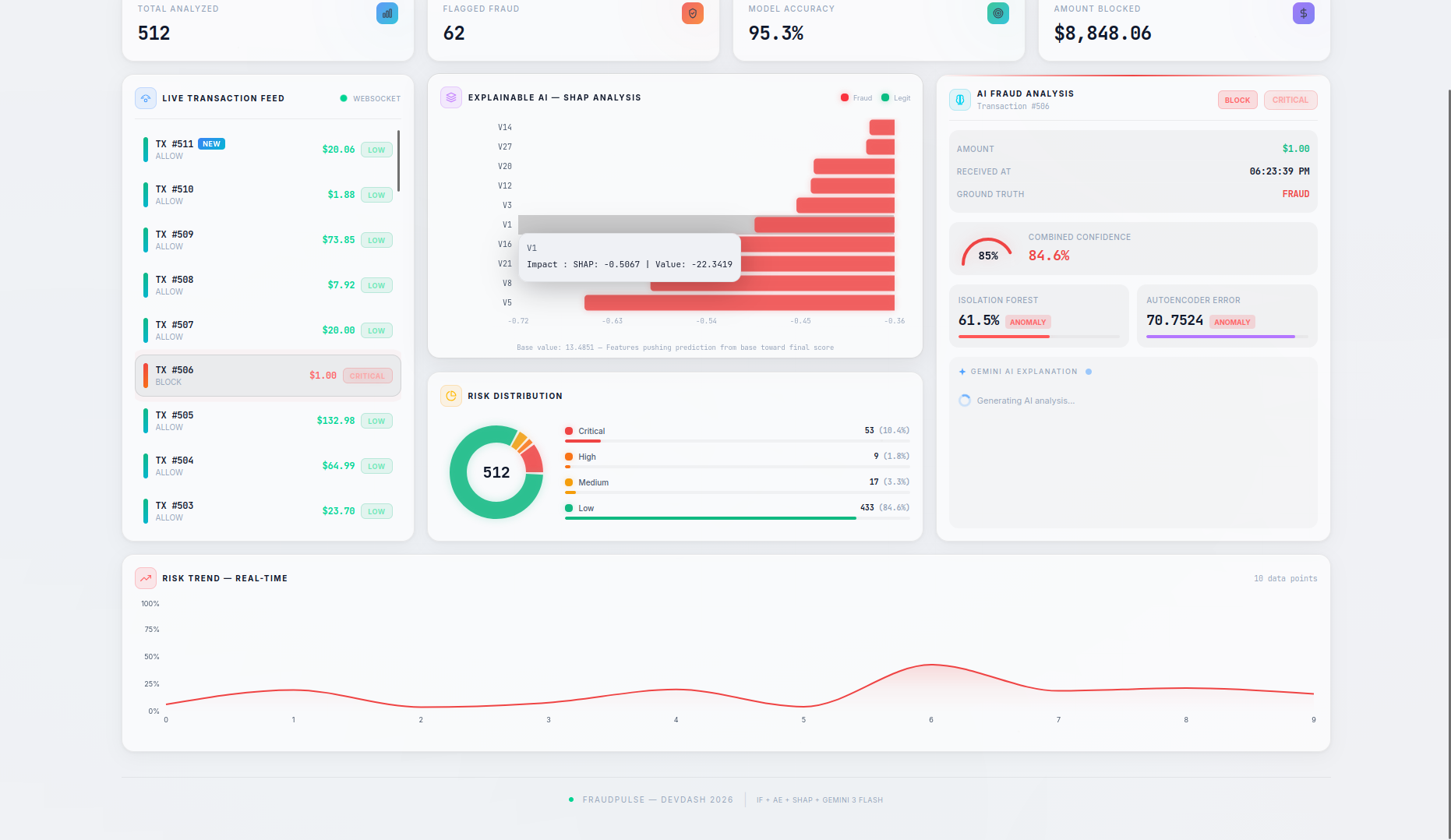
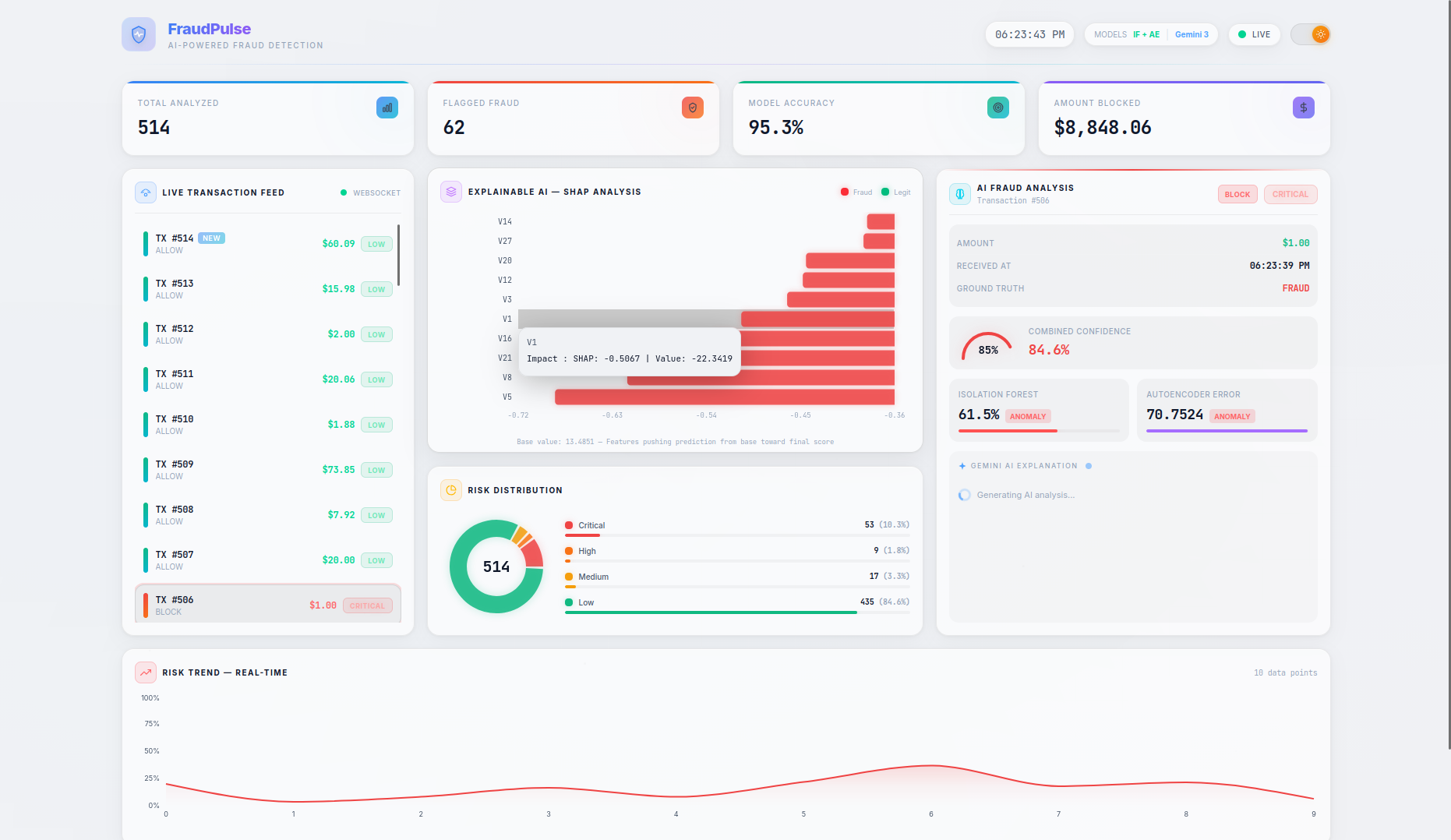
- SHAP Explainability — A per-transaction waterfall chart shows the top features driving each prediction, with their exact impact values and theme-aware tooltips — no more black-box scores.
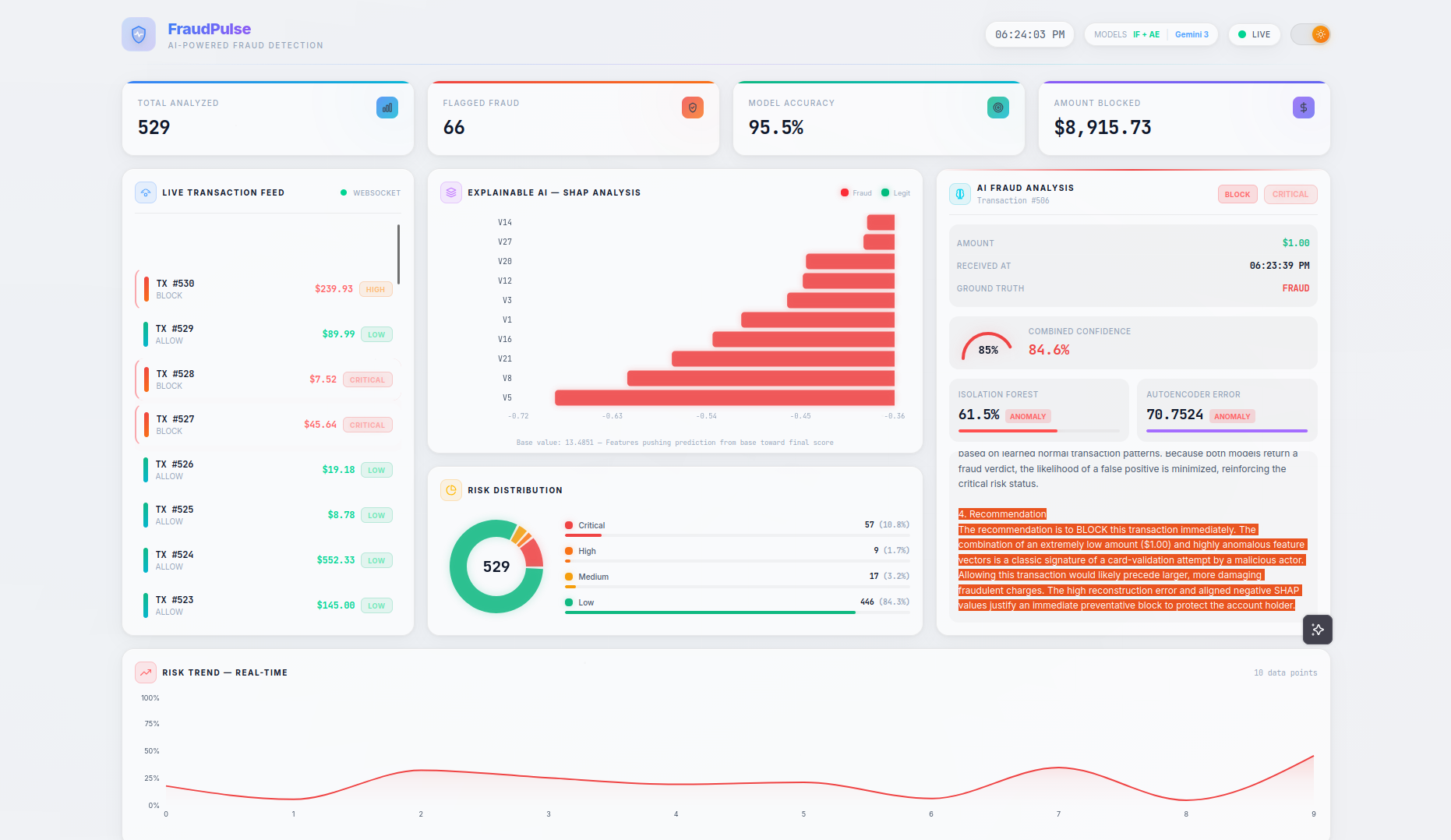
- LLM-Powered Analysis — Clicking on any transaction triggers a Gemini 3 Flash native async streaming explanation covering risk assessment, key indicators, model agreement analysis, and an actionable recommendation (BLOCK / REVIEW / ALLOW). A loading spinner provides visual feedback while the AI generates its analysis.
- Persistent Live Dashboard — Stats cards (Total Analyzed, Flagged Fraud, Model Accuracy, Amount Blocked), risk distribution charts, and a risk trend timeline are all driven by the server as the single source of truth, persisting across page refreshes. The Amount Blocked counter preserves real dollar values (not scaled features) for accurate financial reporting.
- Actionable Recommendations — The combined model score maps to clear action labels:
BLOCK(≥ 0.45),REVIEW(≥ 0.25), orALLOW(< 0.25), giving analysts a concrete next step for every transaction.
How I built it
I split the architecture into two independently deployable services:
Backend (FastAPI + Python)
- I loaded the Kaggle Credit Card Fraud Detection dataset (284,807 transactions, 492 real fraud cases)
- I built a training pipeline (
train.py) that trains both models and evaluates them with full classification reports - The Isolation Forest is configured with contamination matching the actual fraud rate (~0.17%) for optimal recall
- The Autoencoder trains only on legitimate transactions — the key insight is that it learns "what normal looks like", so any transaction it can't reconstruct well is suspicious
- Combined scores are weighted 40% IF / 60% AE, since autoencoders are typically more precise for anomaly detection
- Risk thresholds were calibrated for meaningful classification: CRITICAL (≥ 0.70), HIGH (≥ 0.45), MEDIUM (≥ 0.25), LOW (< 0.25) — tuned through iterative testing to produce a balanced distribution across all risk levels
- SHAP TreeExplainer computes per-feature attributions for each prediction
- Gemini 3 Flash generates native async streaming analysis via SSE, with anti-buffering headers (
X-Accel-Buffering: no,Transfer-Encoding: chunked) to prevent proxy-related truncation. The structured 4-section prompt (Risk Assessment, Key Indicators, Model Agreement, Recommendation) is backed by 4096 max output tokens for thorough explanations - I built a
TransactionStreamerservice that cycles through the dataset with randomized timing (0.5–2s) and boosted fraud visibility (8× fraud samples), simulating a realistic real-time feed with ~12% visible fraud rate - The server preserves original dollar amounts in a separate
Amount_Originalcolumn before StandardScaler transforms theAmountfeature — this ensures real dollar figures appear in the dashboard and in Gemini's analysis, while the ML models still receive properly scaled features - All dashboard statistics (total transactions, flagged count, accuracy, blocked amount, risk distribution) are accumulated server-side and exposed via a
/api/statsendpoint, making the server the single source of truth. Clients poll these stats every 3 seconds, ensuring data persists across page refreshes
Frontend (Next.js 15 + TypeScript)
- I used the App Router with Recharts for data visualization, Framer Motion for micro-animations, and a custom glassmorphism design system with full dark/light theme support using CSS custom properties
- The
useTransactionStreamhook manages WebSocket connections with automatic fallback to HTTP polling, and seeds initial data from the server's 100-transaction buffer on page load - Stats are fetched from the server every 3 seconds — the server is the authoritative source, eliminating double-counting and refresh-reset issues
- SHAP waterfall charts use theme-aware colors and tooltips (CSS variables for axes and labels), ensuring readability in both light and dark mode
- The LLM alert panel shows a loading spinner while waiting for the Gemini response, then streams the text in real-time with a typing caret animation
- Transaction times display in human-friendly AM/PM format throughout the interface
Challenges I ran into
The class imbalance problem — The Kaggle dataset has only 0.17% fraud. Training the Autoencoder on all data would make it reconstruct fraud perfectly (defeating the purpose). The solution: train only on legitimate transactions, so fraud becomes "foreign" to the model.
WebSocket reliability — WebSocket connections drop frequently in deployed environments (proxies, load balancers, cold starts). I built a transparent fallback: the frontend detects WebSocket failure and silently switches to HTTP polling, with a visual indicator showing the active mode.
SHAP computation cost — Computing SHAP values for every transaction in real-time was too slow. I moved SHAP to an on-demand endpoint: values are only computed when a transaction is clicked, keeping the streaming pipeline fast.
LLM streaming resilience — Early Gemini integration used synchronous streaming which blocked the FastAPI event loop, causing truncated explanations — especially on low-risk transactions where the response was longer. The fix was switching to native async streaming (
client.aio.models.generate_content_stream) and adding anti-buffering SSE headers for Railway/nginx deployments. I also doubled max output tokens to 4096 for thorough analysis.Data persistence across refreshes — Client-side stats computation meant everything reset to zero on page refresh. I restructured the architecture to make the server the single source of truth: all counters (total processed, flagged count, blocked amount, risk distribution) are accumulated server-side. The frontend seeds its transaction buffer from the server's 100-item ring buffer on load, and polls stats periodically.
Scaled vs. real dollar amounts — The ML pipeline applies StandardScaler to the Amount feature, which is correct for model input but disastrous for display. A transaction of $149.62 appeared as "$0.29" in the dashboard. The fix was preserving the original amount in
Amount_Originalbefore scaling, using it for display and LLM context, while keeping the scaled value exclusively for model features.Making the demo feed realistic — Simply cycling through the dataset linearly resulted in long stretches of legitimate transactions with no fraud visible. I boosted fraud samples 8× in the demo pool and shuffled the order, resulting in a ~12% visible fraud rate. Combined with lowered risk thresholds (CRITICAL ≥ 0.70 instead of 0.85), the dashboard now shows a healthy mix of all risk levels during any demo session.
Accomplishments that I'm proud of
- The "aha" moment works — When you click a CRITICAL transaction and watch the LLM explanation stream in with a loading spinner, then text appearing word-by-word, breaking down exactly why the models flagged it, referencing actual SHAP values and model scores... it genuinely feels like having an expert analyst sitting next to you. That's the experience I wanted to build.
- True dual-model architecture — This isn't a wrapper around one API. Two fundamentally different ML approaches (statistical isolation vs. neural reconstruction error) collaborate and sometimes disagree, which itself is informative. The Autoencoder error gauge dynamically scales to accommodate values beyond the typical 0–1 range.
- The entire pipeline is real — Real dataset (284K transactions from European cardholders), real trained models (not mock scores), real SHAP values (not random numbers), real LLM analysis (not hardcoded text). Every number on the dashboard means something — including real dollar amounts, not scaled feature values.
- Zero-config resilience — WebSocket drops? Automatic fallback. Page refresh? Stats persist from server. No Gemini API key? Rule-based fallback explanations. The dashboard never breaks.
- Server-side truth — The architecture evolved from client-side computation to a server-authoritative model. Risk distribution, transaction counts, blocked amounts — everything persists across page refreshes because the server owns the data.
What I learned
- Explainability > Accuracy — A model with 95% accuracy that nobody trusts is less useful than a model with 90% accuracy that explains every decision. SHAP transformed FraudPulse from "another ML demo" into a tool an analyst could actually rely on.
- Streaming changes everything — The difference between a static table and a live transaction feed is not just UX polish — it fundamentally changes how you interact with the data. You watch for anomalies instead of searching for them.
- LLM as a "last mile" interface — The ML models do the hard work (detection), SHAP does the attribution, but Gemini 3 Flash does something neither can: it translates math into human language. That final layer is what would make the system accessible to non-technical stakeholders.
- The server must own the truth — Client-side computation is fast and reactive, but it's ephemeral. Moving stats accumulation to the server eliminated an entire class of bugs (refresh resets, double-counting, inconsistent state between tabs) and made the architecture more robust.
- Async streaming is non-negotiable — Blocking the event loop with synchronous LLM streaming caused cascading failures: truncated responses, dropped WebSocket connections, and unresponsive endpoints. Native async streaming solved all of it.
- Solo hackathon = ruthless prioritization — Every feature decision was a trade-off. I learned to cut scope aggressively (no database, no auth, simulated stream instead of live API) while doubling down on what matters: working demo, real AI, polished UX.
What's next for FraudPulse
- Live API integration — Connect to real payment gateway APIs (Stripe, Plaid) for actual real-time transaction monitoring
- Custom model retraining — Allow organizations to upload their own transaction data and retrain the models on their specific fraud patterns
- Alert rules engine — Let analysts define custom rules (e.g., "flag any transaction > $5,000 from a new device") that work alongside the ML models
- Team collaboration — Multi-analyst workflows with case assignment, investigation notes, and audit trails
- Continuous learning — Feedback loop where analyst decisions (confirm fraud / dismiss alert) are fed back to retrain the models over time
Built With
- docker
- fastapi
- framer-motion
- gemini
- next.js
- python
- pytorch
- recharts
- scikit-learn
- shap
- tailwindcss
- typescript
- websocket
Log in or sign up for Devpost to join the conversation.