Inspiration
Fraud detection is not the hard part anymore. Banks already have rules, models, alerts, and dashboards. The harder problem is investigation. When a suspicious UPI transaction is flagged, an analyst needs to know what happened, why the system thinks it is risky, which evidence supports the verdict, whether the decision follows policy, and what should be said to the customer. In a regulated banking environment, “the model said so” is not enough. FraudLens was inspired by that gap. Indian banks are dealing with rising fraud value, high-volume digital payments, under-reported customer fraud, and tighter expectations around AI governance. We wanted to build something that treats fraud investigation as a controlled, auditable workflow — not just a prediction problem. The idea behind FraudLens is simple: every AI verdict should leave a trail, every weak verdict should be measurable, and every improvement should require evidence and human approval.
What it does
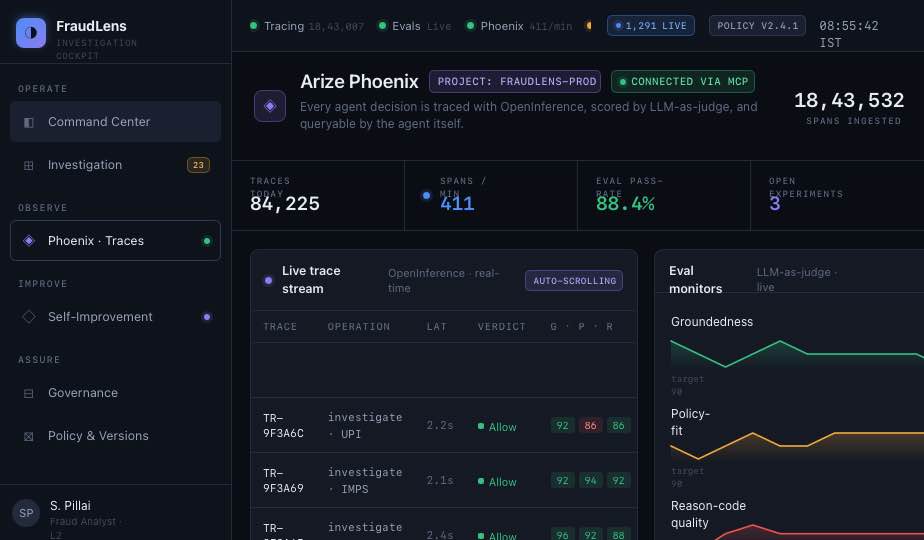
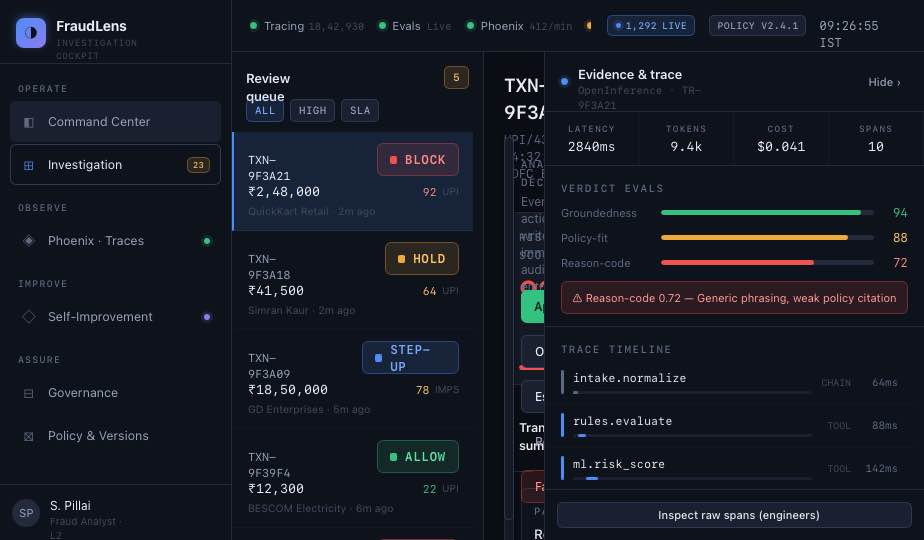
FraudLens is an AI investigation cockpit for Indian banks. It reviews suspicious transactions, gathers evidence, reasons over fraud signals, and recommends an action: allow, step-up, hold, or block. The system combines rule signals, ML risk scores, graph patterns, past fraud cases, policy retrieval, and agent reasoning into one analyst-facing workspace. For every transaction, FraudLens shows:
- why the transaction was flagged
- which evidence the agent used
- what the risk signals were
- how the decision fits policy
- what customer-facing reason code should be sent
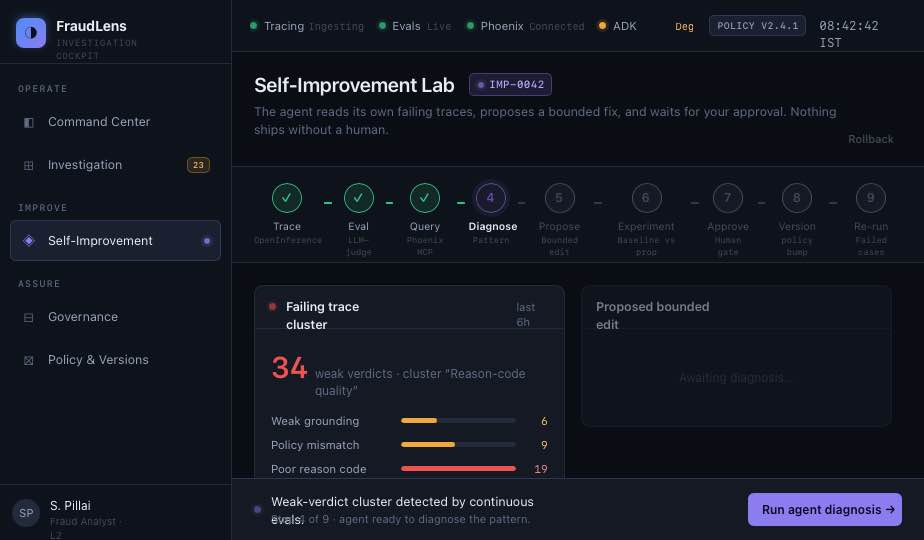
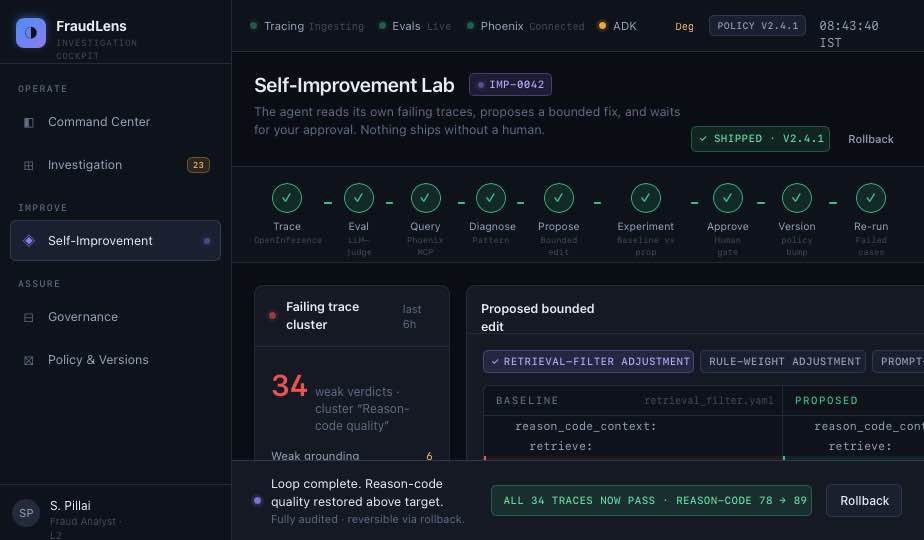
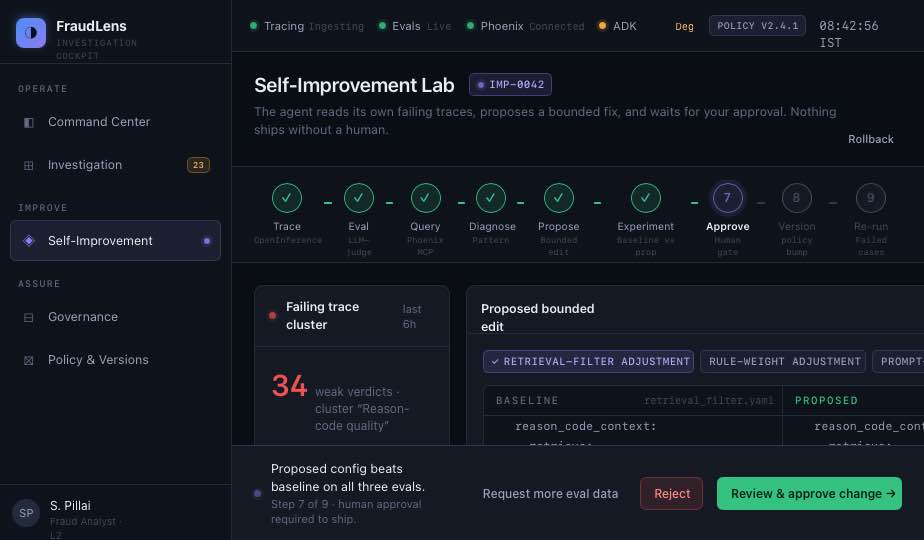
- what the analyst can approve, override, or escalate The more important part is what happens after a verdict. Every agent decision is traced into Phoenix using OpenInference. LLM-as-judge evaluations score the verdict on groundedness, policy-fit, and reason-code quality. When FraudLens finds weak decisions, the agent queries its own failing traces through Phoenix MCP, diagnoses the pattern, proposes a bounded correction, runs a baseline-vs-proposed experiment, and asks a human analyst to approve or reject the change. So FraudLens does not just investigate fraud. It investigates its own investigation quality.
How we built it
We built FraudLens as a Gemini-on-ADK agent running in a code-owned runtime on Google Cloud. The real-time pipeline starts with a transaction event. It is enriched with behavioural, transactional, device, beneficiary, and graph features. The decisioning layer combines rules, a LightGBM risk model, graph signals, and a late-fusion score. The ADK agent then reasons over the risk context using tools for graph walk, case fetch, risk scores, policy search, verdict emission, and audit logging. Phoenix is central to the system, not an add-on. We use OpenInference instrumentation to trace the ADK agent’s decisions into Phoenix. Each trace captures the agent loop, tool calls, retrieved evidence, model calls, final verdict, and audit write. A separate evaluation job runs LLM-as-judge checks for groundedness, policy-fit, and reason-code quality. The self-improvement loop runs through Phoenix MCP. FraudLens queries failed traces, identifies the most common failure pattern, proposes one bounded intervention, runs a Phoenix experiment comparing old and proposed behaviour, and only applies the change after analyst approval.
- The cockpit itself is designed around three main surfaces:
- An investigation workspace for fraud analysts
- A self-improvement lab for trace-based corrections
- A governance dashboard for audit, policy, drift, fairness, and compliance review
Challenges we ran into
The biggest challenge was keeping the system powerful without making it feel unsafe. A self-improving fraud agent sounds useful, but in banking it can quickly become unacceptable if the agent can silently rewrite its own behaviour. We had to design the loop so improvement is measurable, bounded, reversible, and human-approved. Another challenge was making the trace useful to more than engineers. Phoenix gives us rich observability, but a fraud analyst should not have to read raw spans to understand a decision. We had to translate traces into an investigation story: what the agent saw, what it used, what it ignored, and where the verdict was weak. We also had to balance latency and depth. Fraud decisions need to happen quickly, but investigation needs evidence. The architecture separates real-time decisioning from deeper evaluation and self-improvement, so the system can act fast while still learning from its mistakes. The final challenge was regulatory framing. FraudLens had to feel credible for Indian banking from day one. That meant thinking about audit logs, policy versions, customer reason codes, natural justice, DPDP purpose checks, fairness monitoring, and rollback — not just model accuracy.
Accomplishments that we're proud of
We are proud that FraudLens is not another fraud-score dashboard. The strongest part is the closed loop: trace, evaluate, diagnose, propose, experiment, approve, version, and re-run. The agent can find its own weak decisions, but it cannot change production behaviour without passing safety rails and getting human approval. We are also proud of how visible Phoenix is in the product. It is not hidden in the backend. Traces, evals, experiments, prompt versions, datasets, and rollback all become part of the cockpit experience. The investigation workspace is another important piece. A bank analyst can open a suspicious transaction and see the verdict, risk signals, graph evidence, similar cases, policy references, trace summary, and customer reason code in one place. That is the difference between an alert and an investigation. We are also proud of the governance layer. FraudLens keeps a versioned trail from transaction to verdict to eval to approved correction. That makes the system easier to explain to risk teams, compliance reviewers, and model-risk committees.
What we learned
We learned that the real value of AI in fraud operations is not just better prediction. It is better judgment under constraints. A fraud system has to be fast, but it also has to be explainable. It has to adapt, but not recklessly. It has to help analysts, but not remove accountability. It has to protect banks, but it must still treat customers fairly. We also learned that observability becomes much more valuable when it changes product behaviour. A trace is useful for debugging. But a trace that can trigger evaluation, expose a repeated failure pattern, support an experiment, and justify a controlled correction becomes part of the operating system of the product. The biggest lesson was that human-in-the-loop design is not just a checkbox. The analyst needs enough context to make a real decision. That means showing the failure pattern, the proposed change, the before/after eval scores, the safety checks, and the rollback path clearly.
What's next for FraudLens — Investigation Cockpit
Next, we want to turn FraudLens into a fuller investigation cockpit for bank fraud teams. The immediate next step is a stronger analyst workflow: better queue prioritisation, richer transaction timelines, clearer graph exploration, and faster review actions. We also want to improve the reason-code experience so customers receive explanations that are plain, respectful, and available in Indian languages. On the AI side, we want to expand the self-improvement loop with more evaluation types, stronger human calibration, and staged rollout. Instead of applying an approved change everywhere at once, future versions can support canary rollout, production KPI monitoring, and automatic rollback when quality drops. On the governance side, we want to add exportable audit packs for model-risk committees, regulator reviews, and fraud reporting. Each pack should show the transaction, evidence, trace, policy version, eval scores, analyst action, and any later self-improvement linked to that decision. Longer term, FraudLens can support cross-bank mule-network intelligence through privacy-preserving or federated approaches, subject to regulatory approval. Fraud networks do not respect bank boundaries. The investigation layer should eventually help banks collaborate without exposing customer data unnecessarily. Our goal is to make FraudLens the cockpit where fraud analysts, AI agents, and governance teams work from the same evidence.
Built With
- adk
- arize
- google-cloud-build
- mcp
- next.js
- open-telemetry
- phoenix
- python
- react
- typescript
- vertexai

Log in or sign up for Devpost to join the conversation.